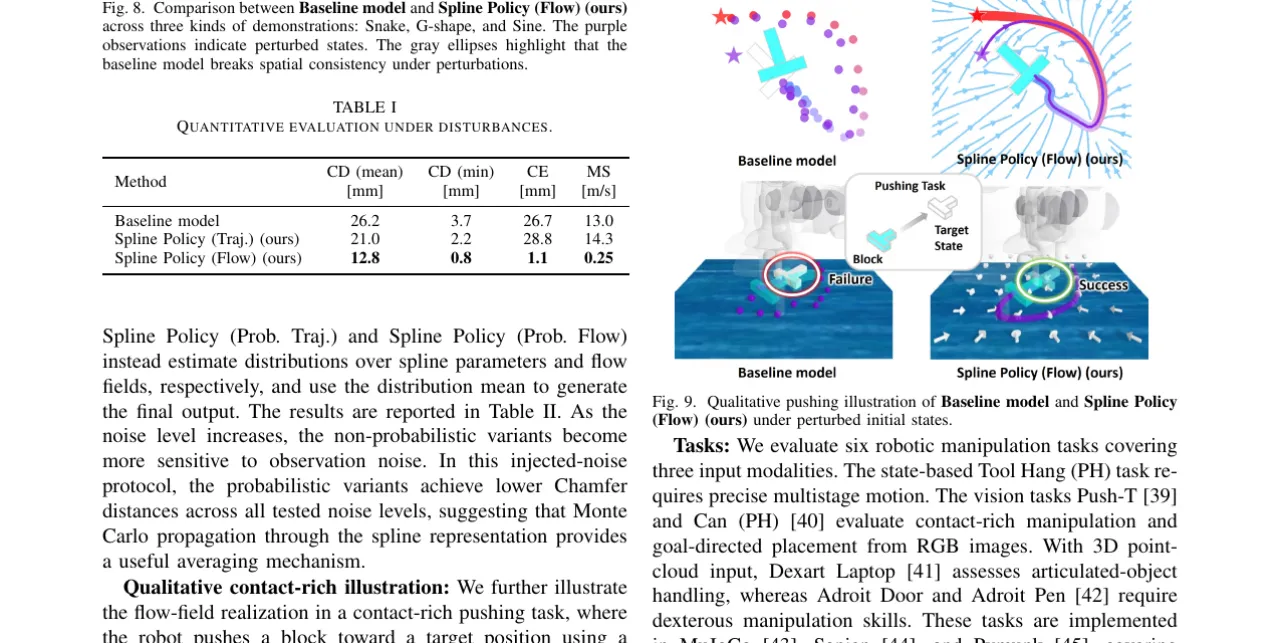
"Modern imitation-learning policies for robot manipulation often represent actions as fixed-resolution action chunks, which are simple and effective but expose limited geometric and temporal structure before execution."
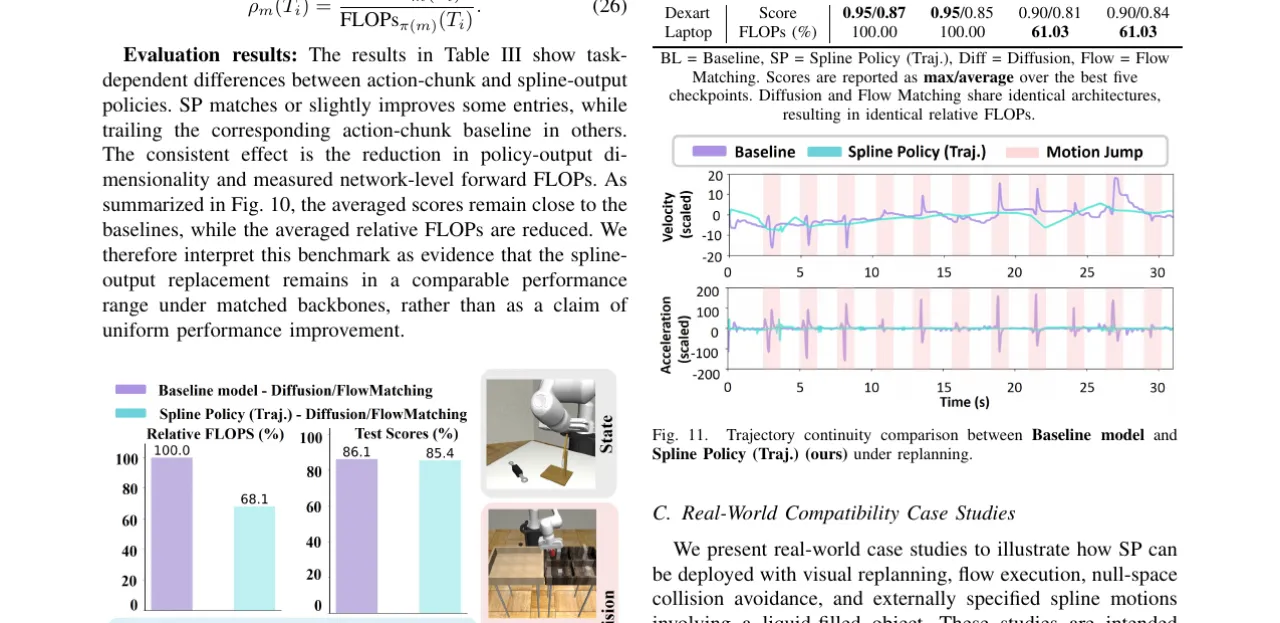
SP 在六个任务上(Tool Hang、Can、Push-T、Adroit Door、Adroit Pen、Dexart Laptop)的平均得分与基线相当,"consistent effect is the reduction in policy-output dimensionality and measured network-level forward FLOPs"(引自论文),不作为性能均匀提升的主张,而是等效性能下更高效的证据。
SP 更改的是预测动作对象的表示,而非策略主干。"It does not remove the need for an accurate and expressive policy backbone. If the policy predicts an inappropriate spline, the structured decoder or the induced flow field cannot by itself guarantee task success."(引自原文)
流场修正仅为局部保证,不适用于高度不连续任务(stated)
"The distance-to-spline corrective property applies to the generated motion under the assumptions of the analytical construction, not to arbitrary task objectives or arbitrary off-manifold states. SP may also be less suitable for highly discontinuous or dynamic interactions, such as hitting a moving object, where additional task-specific modeling or engineering may be required."(引自原文)
解析流场仅限于拼接二次样条(stated)
当前解析距离场与流场构建依赖拼接二次样条的 C⁰/C¹ 连续性。"Extending the construction to broader spline families and evaluating uncertainty-aware or constraint-aware execution policies are important directions for future work."(引自原文)
真实机器人实验非受控对比(stated)
真实机器人实验为兼容性案例研究,"intended as system-level demonstrations of compatibility, rather than controlled comparisons against action-chunk policies"(引自原文)。不同主干的模型规模、预训练、优化器与训练时长均不同,成功率差异不能单独归因于主干架构。