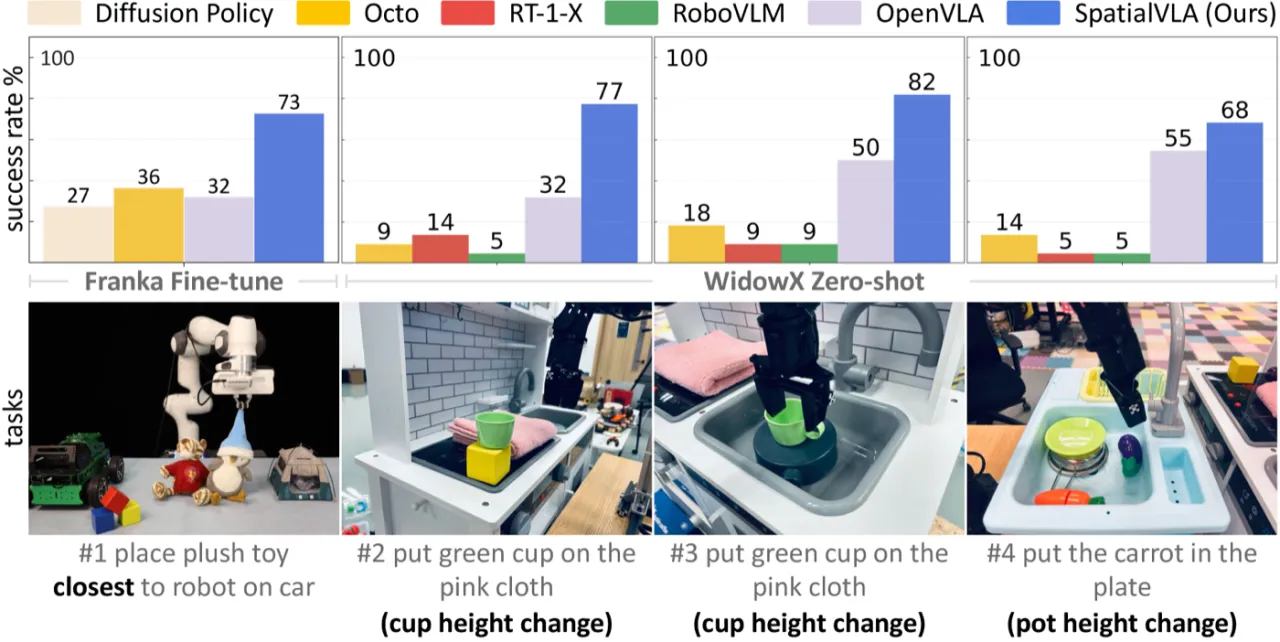
"Spatial understanding is the key to robot manipulation … we propose SpatialVLA, a spatial visual-language-action model that focuses on exploring spatial representations for robot manipulation."
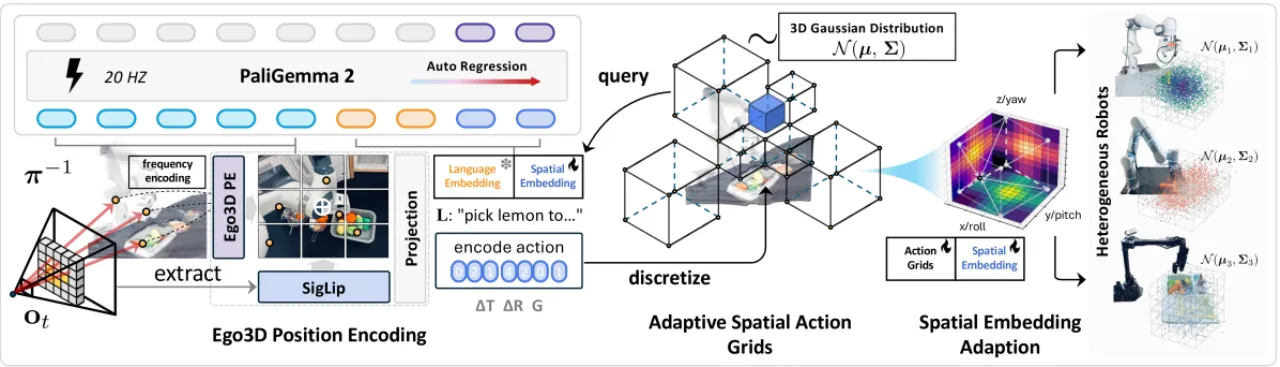
图1:SpatialVLA 总览。 给定图像观测 ot 与任务指令 L,模型通过 Ego3D Position Encoding 处理图像,自回归预测空间动作 token,再反 tokenize 为连续动作 At 执行控制。
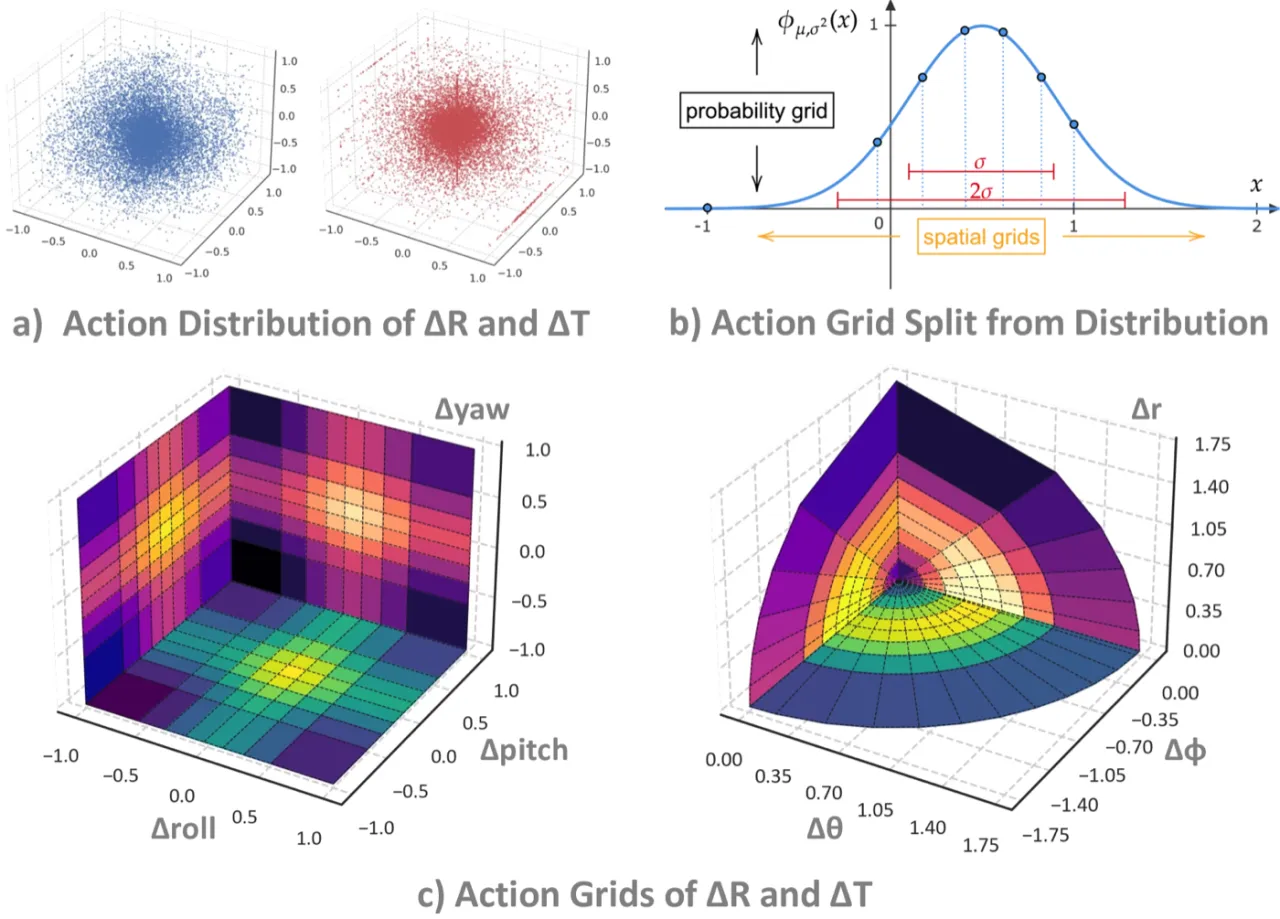
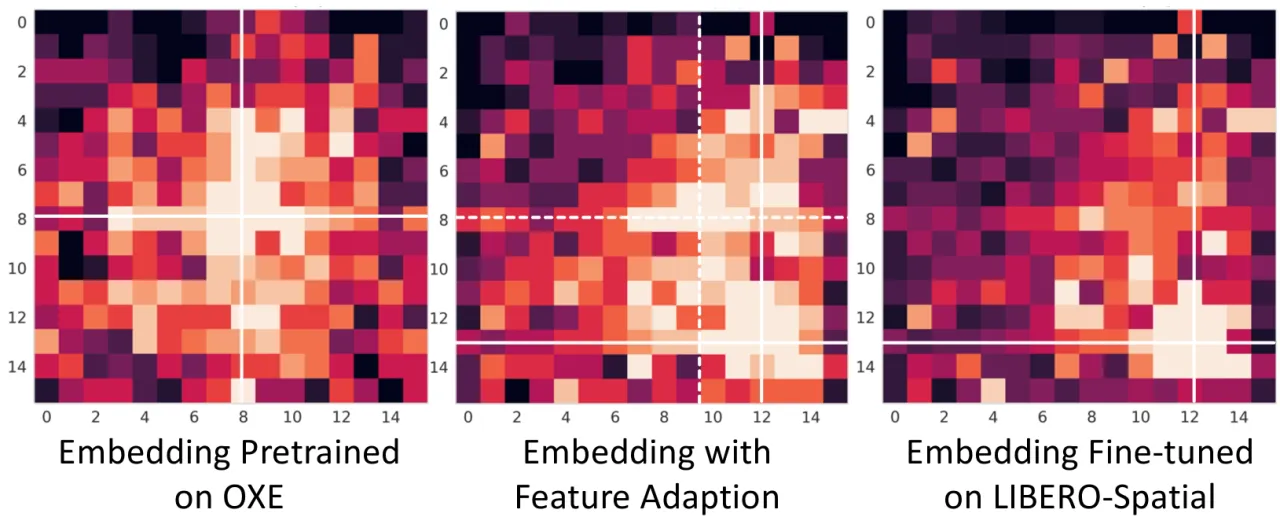
"Is modeling data distributions as Gaussian optimal? We argue that Gaussian modeling is suboptimal, as it can lead to grid clustering on specific coordinate axes in extreme robot operation scenarios, such as single-axis motion, resulting in lost motion capabilities on other axes."(单轴运动等极端场景下,Gaussian 拟合可能导致某些轴的网格过度聚集,使其他轴的运动能力退化。)
仅依赖当前帧,长时序任务表现受限
"As the model relies solely on current frame observations and history tokens for action prediction, it faces challenges in long-horizon tasks." 作者指出未来需要设计高效的历史信息感知机制以增强长序列建模能力。
推理速度慢于 diffusion 方法
"SpatialVLA achieves 21Hz inference speed, it is slower than diffusion decoding." 自回归 token 预测的推理开销高于基于扩散的策略网络,在对实时性要求极高的场景下存在瓶颈。
预训练数据质量参差
"The variable quality of OXE data can hinder training. Therefore, future work exploring optimal data composition and distilling high-quality subsets from the heterogeneous robot data collections is vital for boosting model efficiency and generalizability."