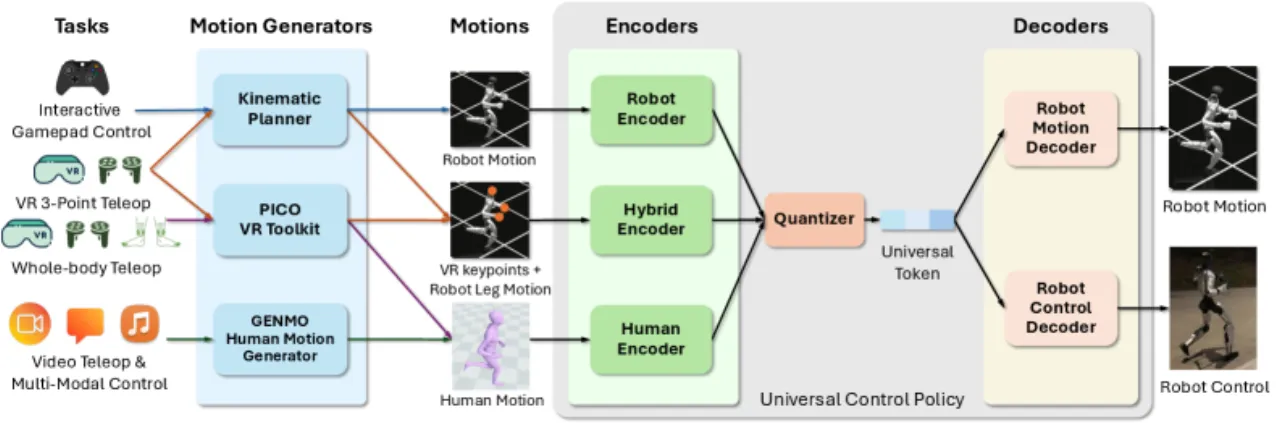
01 动机
大语言模型已证明"规模即能力",但 humanoid 控制领域至今未能复现这一增益:现有神经控制器参数规模有限、行为种类单一、训练资源匮乏。 SONIC 的出发点正是弥合这一差距——证明在 humanoid 控制上同样存在清晰的 scaling law。
"Despite the rise of billion-parameter foundation models trained across thousands of GPUs, similar scaling gains have not been shown for humanoid control. Current neural controllers for humanoids remain modest in size, target a limited set of behaviors, and are trained on a handful of GPUs."

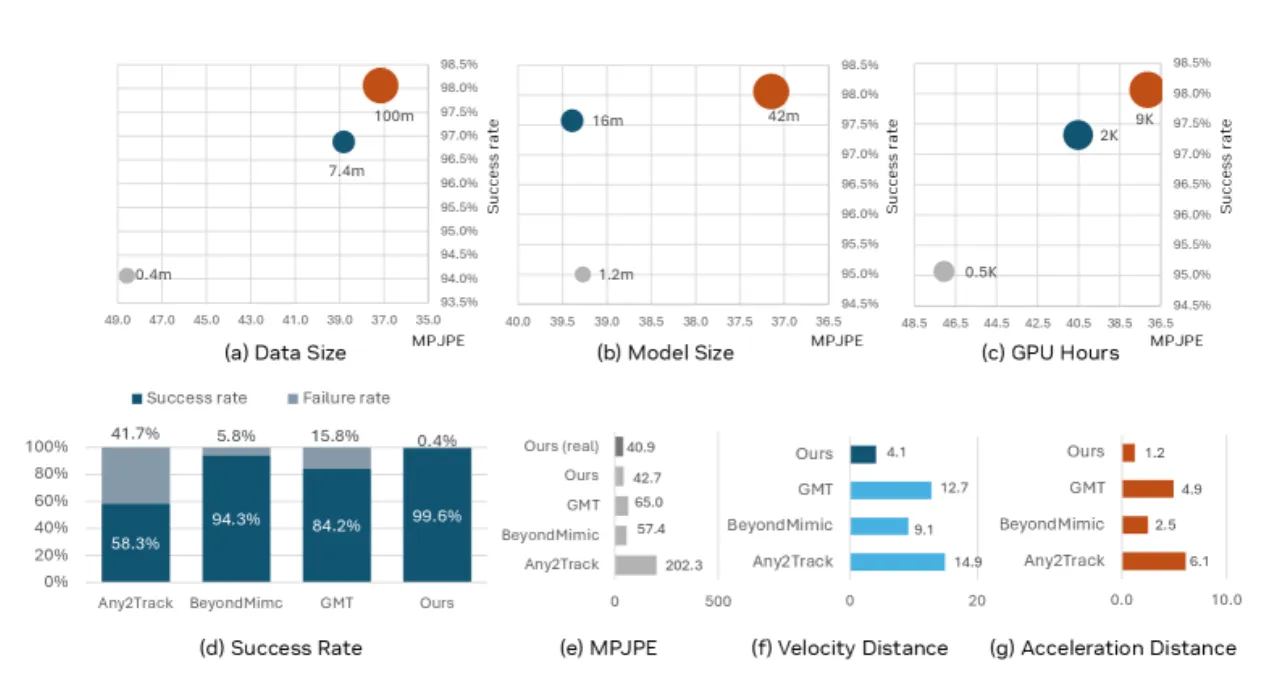
42M最大模型参数量
700h运动捕捉数据(100M+ 帧)
21kGPU 小时训练计算量
95%VLA 自主操作任务成功率(20 次试验)
Motion tracking 天然适合 scaling:运动捕捉数据提供密集的监督信号,无需手工设计奖励函数;多样化数据集隐式赋予策略人体运动先验(human motion prior)。 SONIC 同时在三个维度上扩展:网络容量(1.2M → 42M 参数)、数据量(100M+ 帧,700 小时高质量 mocap)、计算量(21,000 GPU 小时)。