01 动机
现有大规模视频数据集(如 Sports-1M、ActivityNet)以高层动作识别为目标,使得模型可以依赖单帧特征或场景线索作弊,而无需真正理解物体的物理属性与因果关系。这一缺陷导致神经网络缺乏类似人类的"视觉常识"(visual common sense)。
"One obstacle that prevents networks from reasoning more deeply about complex scenes and situations, and from integrating visual knowledge with natural language, like humans do, is their lack of common sense knowledge about the physical world."

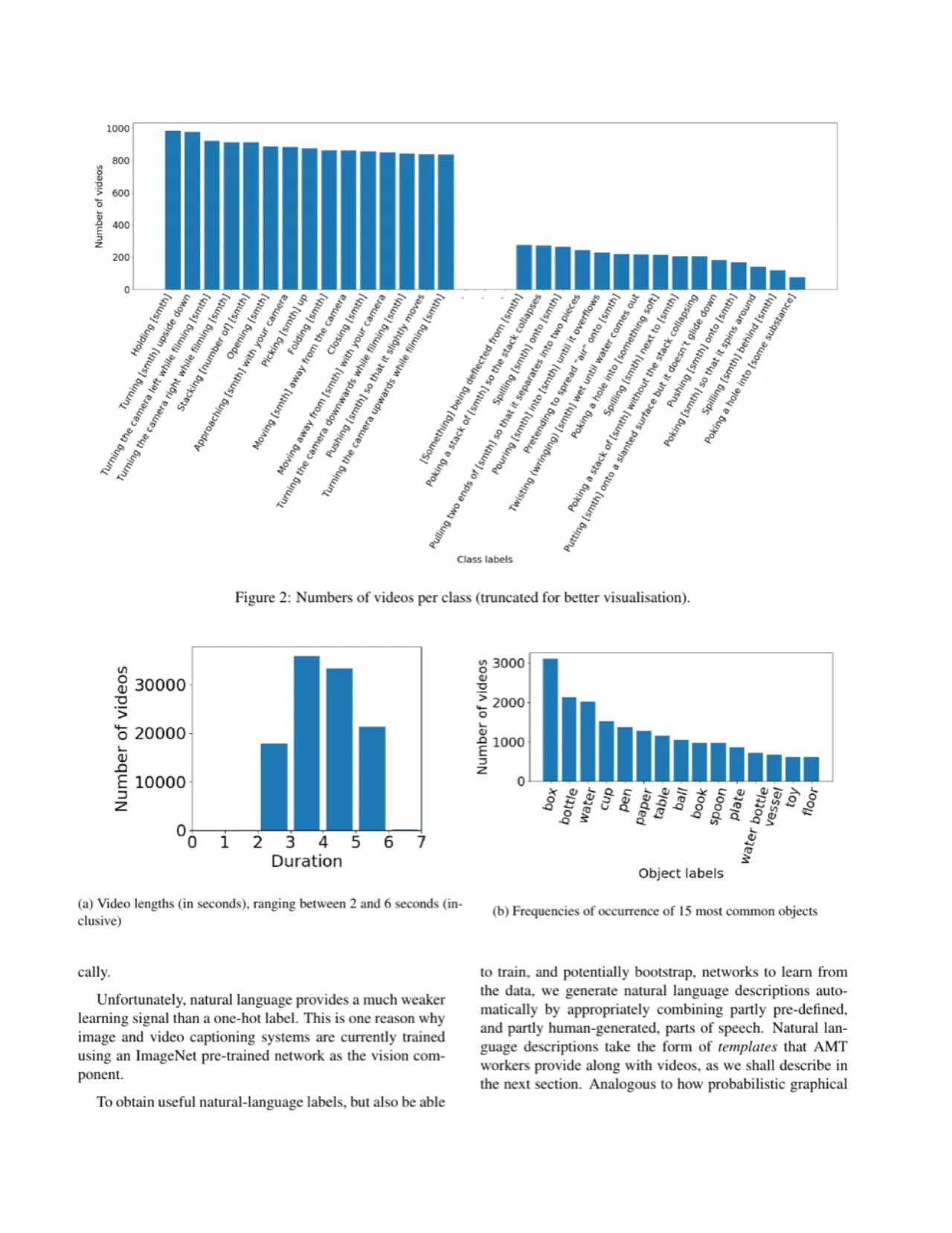
108,499视频总数
174动作类别数
4.03 s平均视频时长
1,133众包工作者人数
视频(而非静态图像)天然包含物体运动、形变、遮挡等信息,是学习直觉物理(intuitive physics)和空间关系的理想载体。作者认为,要真正学习"opening"这一概念,网络必须能跨越"opening a door"、"opening a zipper"、"opening a mouth"等不同场景进行泛化——而这正是 Something-Something 数据集的设计初衷:提供高度细粒度、专注于基础物理概念的视频-标签对。
与现有数据集的对比(Table 1)显示,Something-Something 视频数量(108,499)远超其他专注于物理交互的数据集(如 Physics 101:17,408),且视频更短(平均 4.03 秒),时序标注更精确。