01 动机
当前的视觉-语言-动作(VLA)模型通常拥有数十亿参数,导致训练成本极高、难以在真实场景中部署。这一"规模崇拜"使得机器人学习研究对大多数团队而言门槛极高。
"existing VLA systems are typically massive–often with billions of parameters–leading to high training costs and limited real-world deployability."
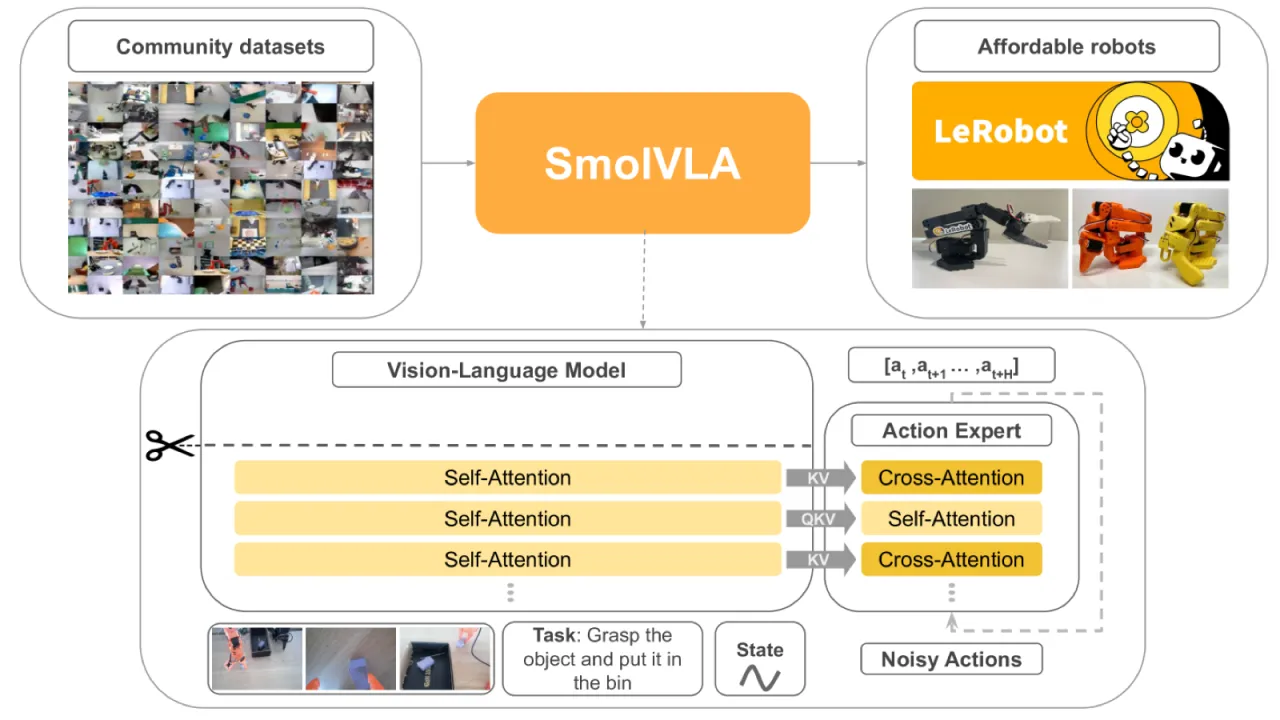
SmolVLA 的核心主张是:性能优秀的 VLA 不必庞大。通过精心的架构设计和利用社区贡献的开放数据集,0.45B 参数的 SmolVLA 在多个基准上超越了 3B 参数的 π₀,同时大幅降低了训练与部署的资源门槛。
0.45B总参数量(含 action expert)
87.3%LIBERO 平均成功率(超越 3.3B π₀ 的 86.0%)
57.3%Meta-World 平均成功率(超越 π₀ 的 47.9%)
78.3%SO100 真实机器人平均成功率(超越 π₀ 的 61.7%)