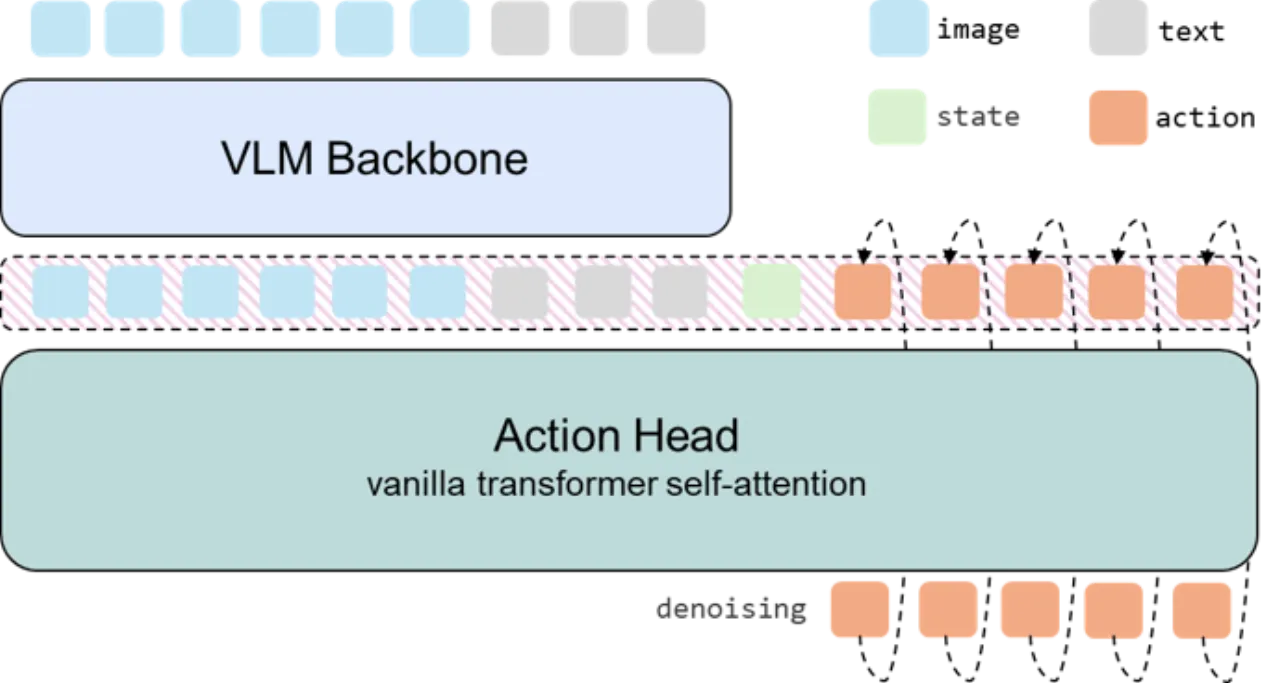
03 实验
实验在三类基准上评估:仿真基准 LIBERO(含 Spatial / Object / Goal / Long 四个子任务集)与 LIBERO-PRO(鲁棒性评估)、SimplerEnv(WidowX 与 Google Robot)、以及 Galaxea R1 Lite 真实机械臂上的八项多阶段任务。
LIBERO 仿真基准
模型 参数量 Spatial Object Goal Long 平均
OpenVLA-OFT 7B 97.6% 98.4% 97.9% 94.5% 97.1%
π₀.₅ 3B 98.8% 98.2% 98.0% 92.4% 96.9%
VLA-Adapter 0.5B 97.8% 99.2% 97.2% 95.0% 97.3%
SimVLA 0.5B
99.6% 99.8% 98.6% 96.4% 98.6%
SimplerEnv 仿真基准
平台 模型 平均成功率 WidowX MemoryVLA 71.9% WidowX FPC-VLA 64.6% WidowX SimVLA 95.8% Google Robot SpatialVLA 67.5% Google Robot RT-2-X 65.6% Google Robot ThinkAct 65.1% Google Robot X-VLA 75.7% Google Robot SimVLA 76.1%
显存效率对比
模型 参数量 LIBERO 平均 VRAM (GB) OpenVLA-OFT 7B 97.1% 62.0 π₀.₅ 3B 96.9% 51.3 VLA-Adapter 0.5B 97.3% 24.7 SimVLA 0.5B 98.6% 9.3
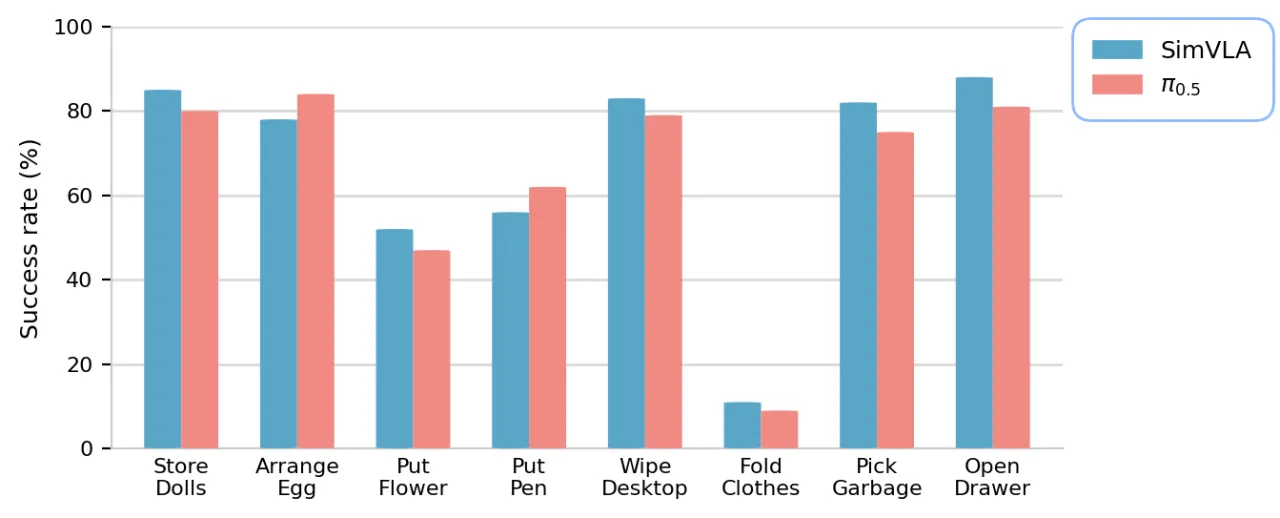
真实机器人零样本结果(Galaxea R1 Lite)
图 3:Galaxea R1 Lite 上的真实机器人零样本结果。 SimVLA 在 held-out 场景上直接部署,无需额外微调,评估八项多阶段操作任务,总体性能与 π₀.₅ 基线相当。(原文 Figure 3 caption)
八项评估任务包括:整理玩偶(store dolls)、排列鸡蛋(arrange eggs)、插花(put flowers in vase)、放笔(put pen in holder)、擦桌面(wipe desktop)、折叠衣物(fold clothes)、捡垃圾(pick up garbage)、开抽屉(open drawer)。大多数任务在零样本跨场景设置下取得约 80% 的成功率。
消融实验
消融分析将每项因素独立移除后在 LIBERO 上评估,揭示了哪些是决定性因素、哪些影响有限:
消融项 LIBERO 平均成功率 变化 完整 SimVLA(基准) 98.6% — 禁用 data shuffling 9.9% −88.7% 禁用 action normalization 12.3% −86.3% 学习率 5×10⁻⁴ 72.7% −25.9% VLM LR 乘子 = 1.0 44.2% −54.4% Cross-attention(替换 token concat) 91.5% −7.1% Conditional AdaLN injection 91.1% −7.5% Florence-2 backbone 97.7% −0.9% 缩小 Action Transformer 规模 98.0% −0.6%
消融结果显示:data shuffling 和 action normalization 是最关键的因素 ,禁用任意一项都会导致性能崩溃至接近 10%。相比之下,架构细节(如 action transformer 规模、backbone 选型)的影响相对次要,充分支持了"训练动态比架构创新更重要"的核心论点。