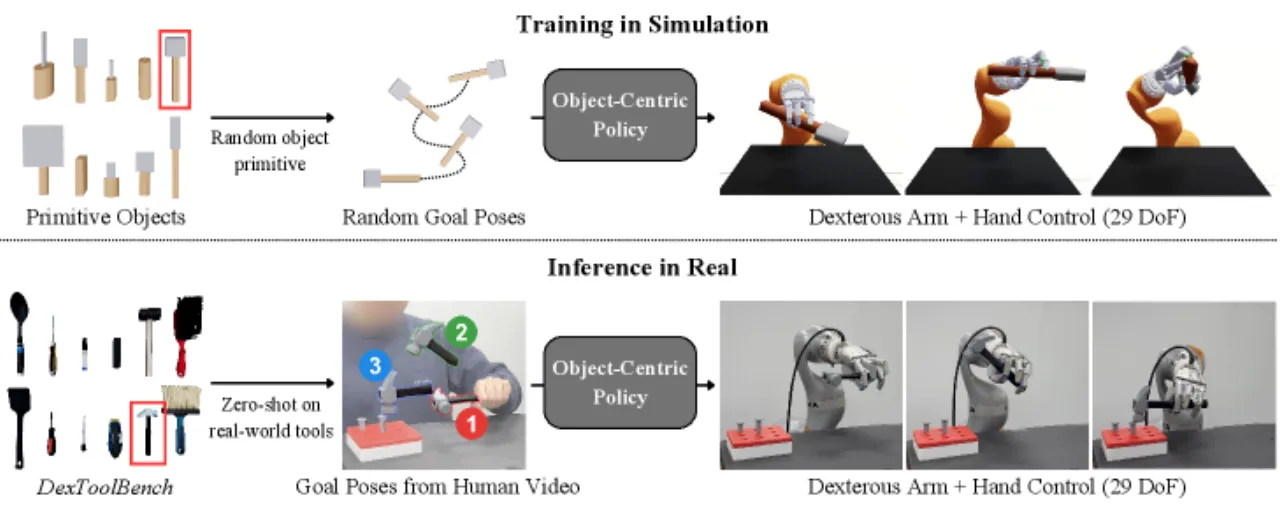
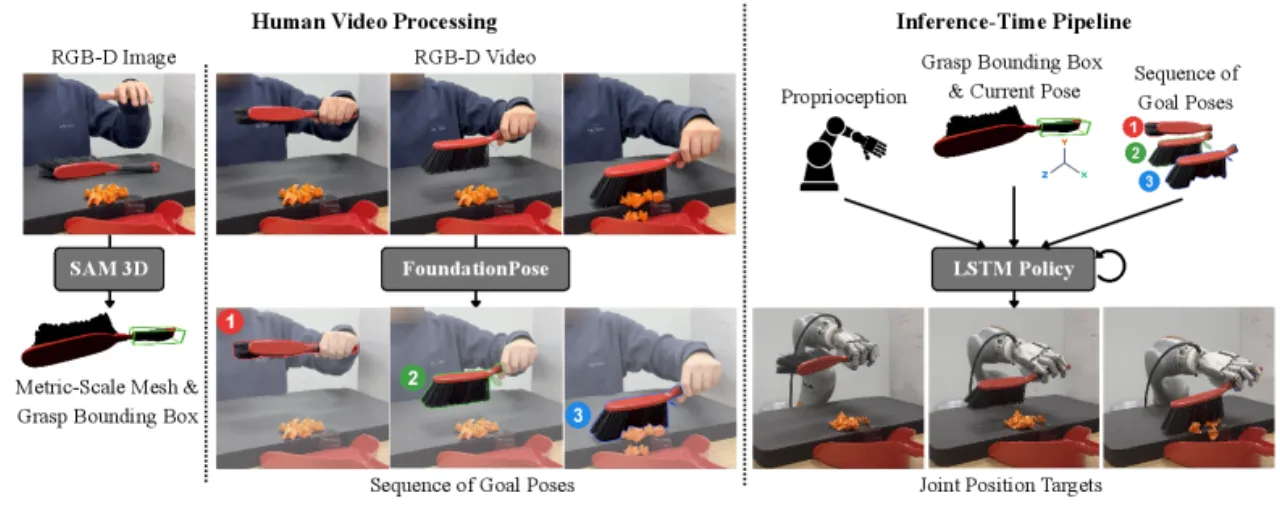
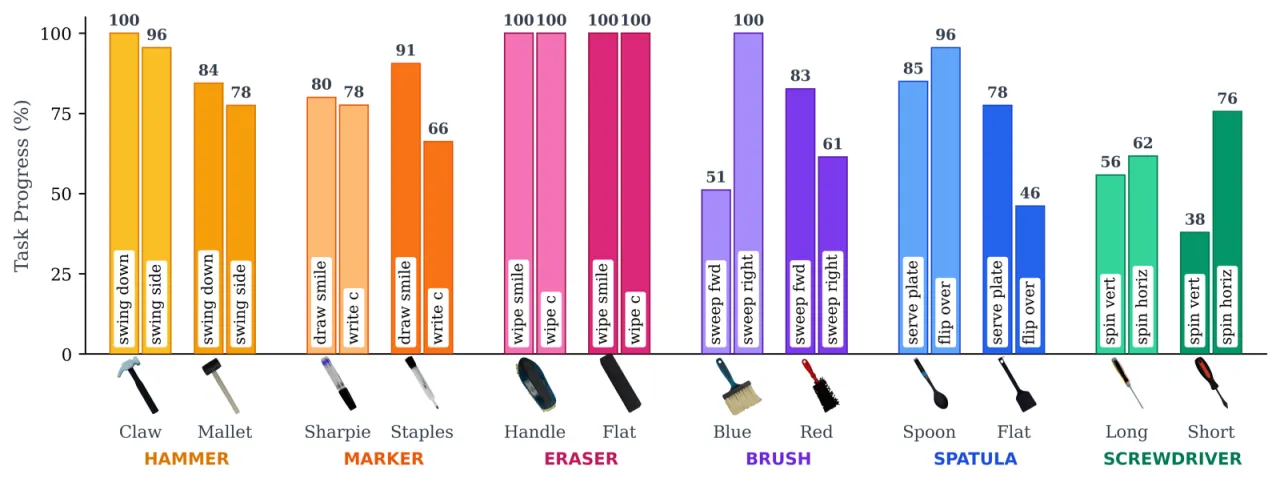
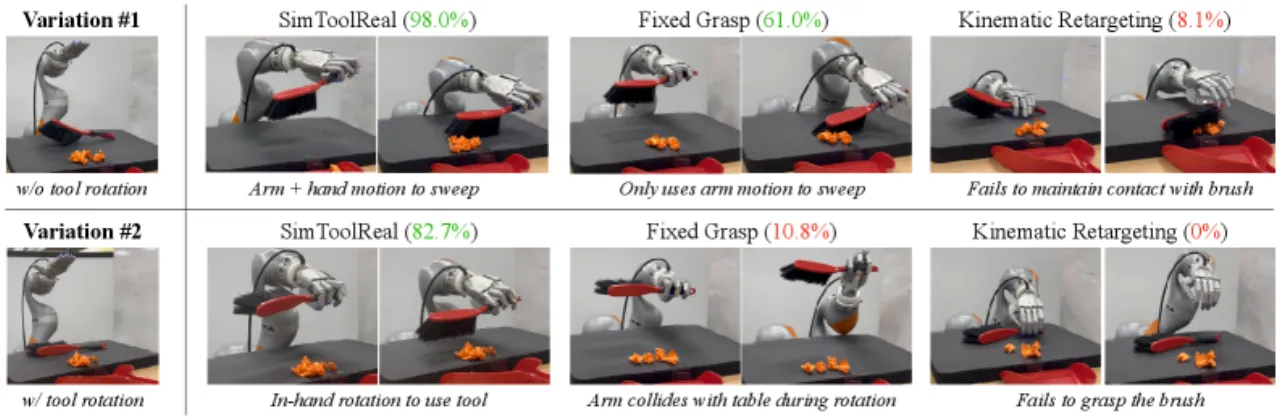
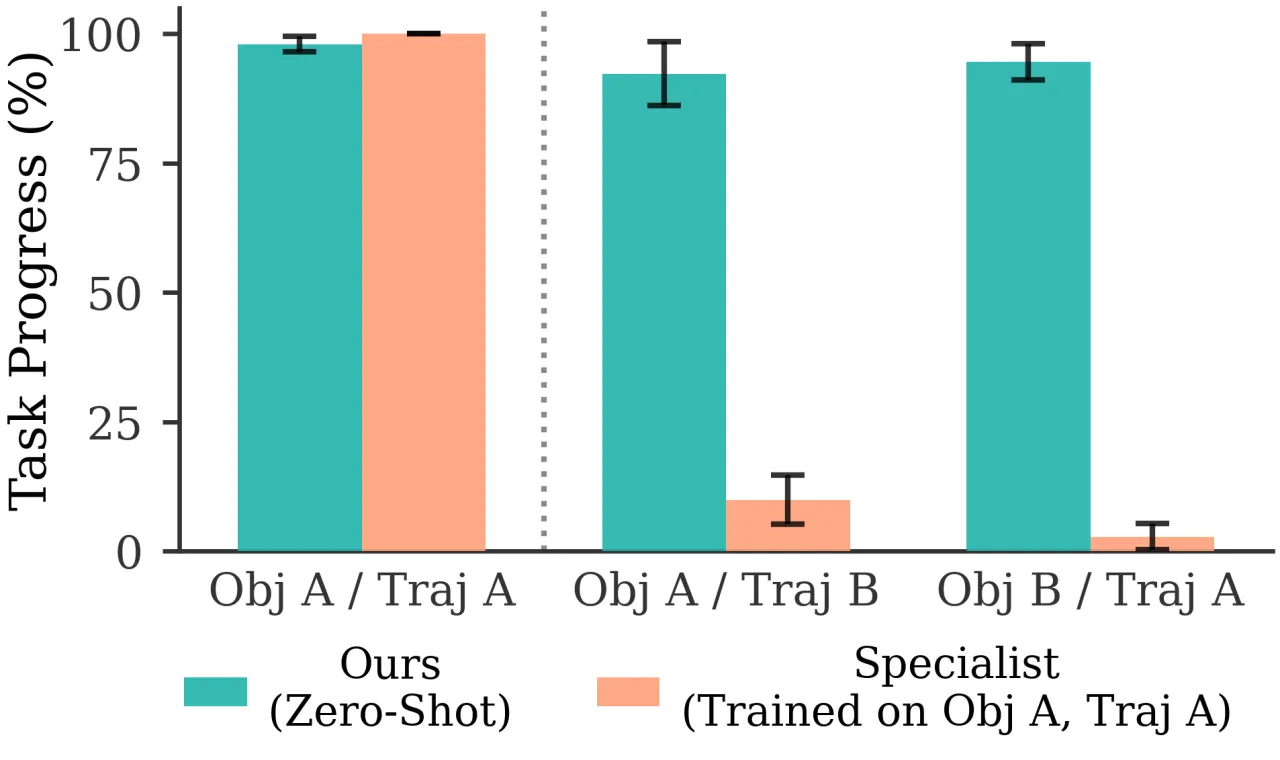
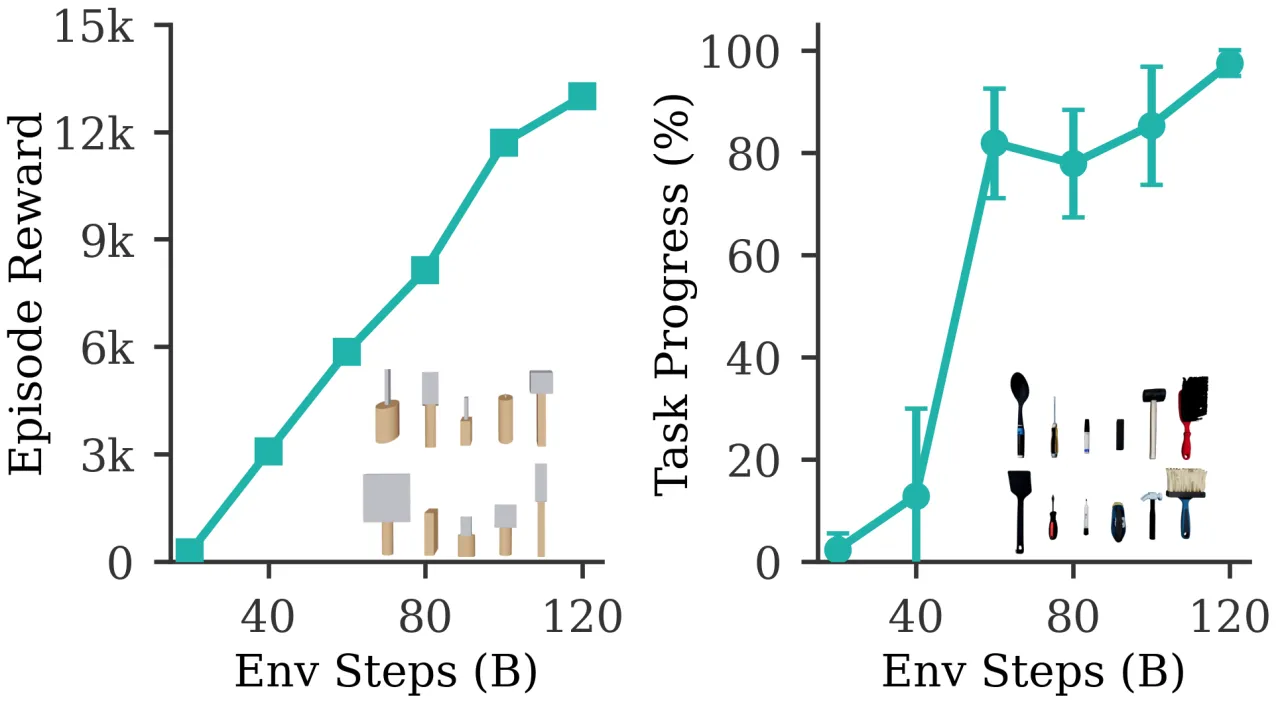
"Instead of focusing on a single object and task, we procedurally generate a large variety of tool-like object primitives in simulation and train a single RL policy with the universal goal of manipulating each object to random goal poses. This approach enables SimToolReal to perform general dexterous tool manipulation at test-time without any object or task-specific training."
"Conditioning on object pose goals alone is environment-blind, which can lead to collisions in cluttered scenes."——策略仅感知物体位姿与目标位姿,不感知周围障碍物,在复杂场景中可能发生碰撞。