01 动机
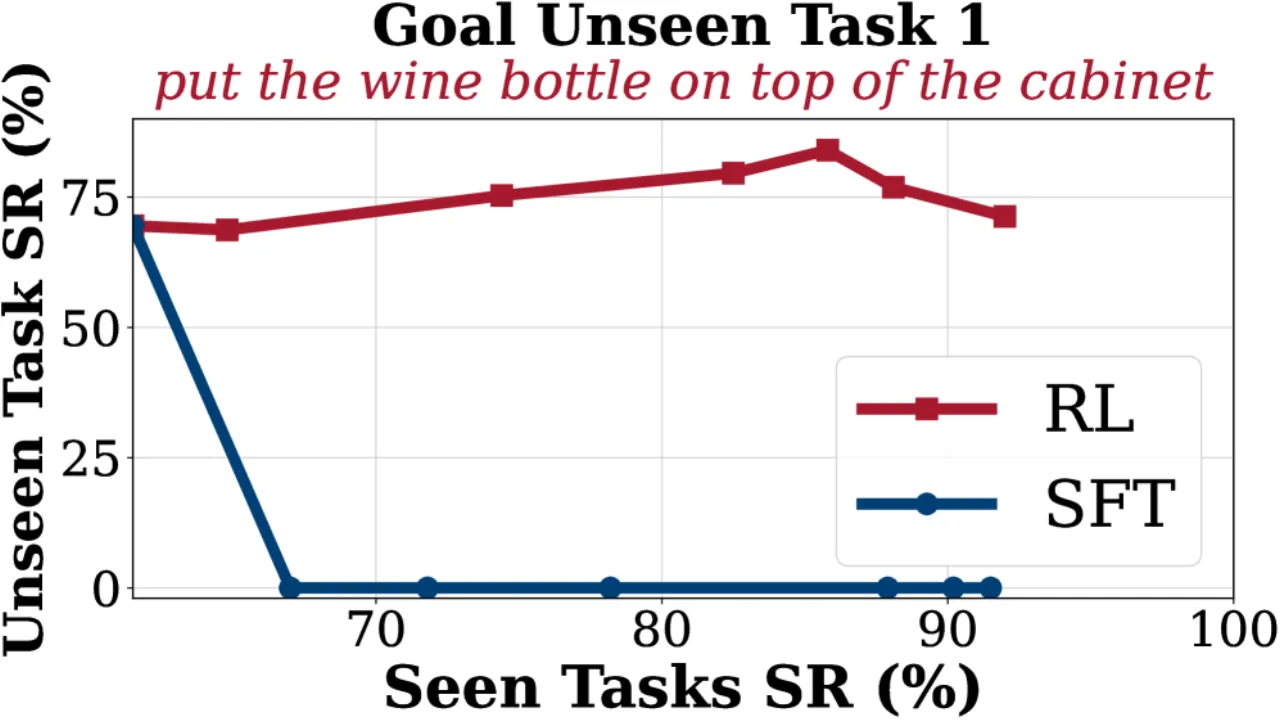
VLA 模型在机器人操控领域展现出强大潜力,但面临两大核心挑战:一是人工操作轨迹数据稀缺——大量高质量示范数据难以获取;二是分布偏移下泛化能力有限——在监督微调(SFT)范式下,模型面对未见场景时表现急剧下降。已有工作尝试将强化学习(RL)引入 VLA,但受限于在线训练效率低下和缺乏可扩展的并行化框架,实际应用受阻。
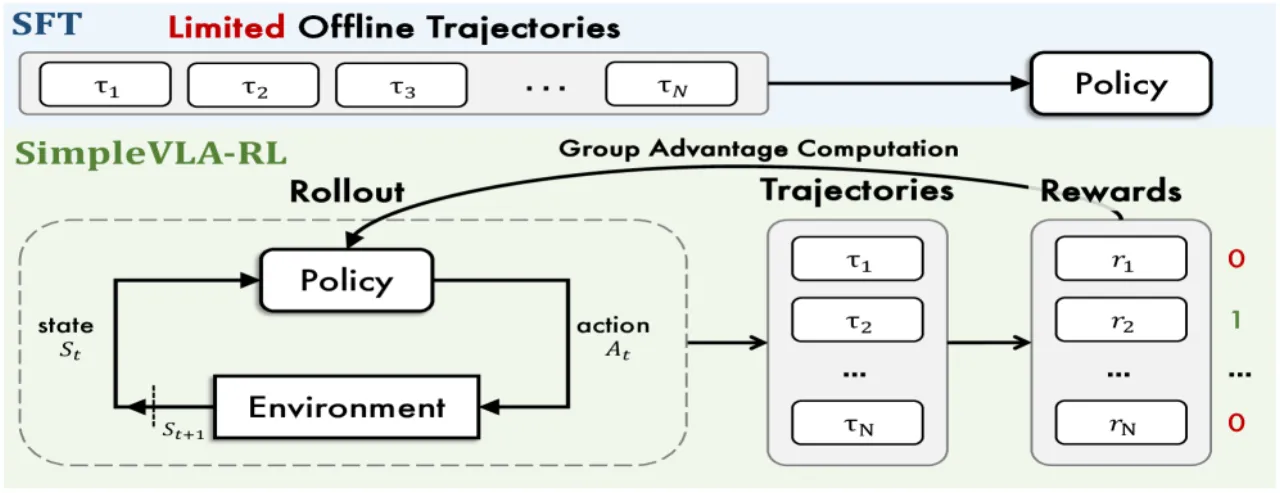
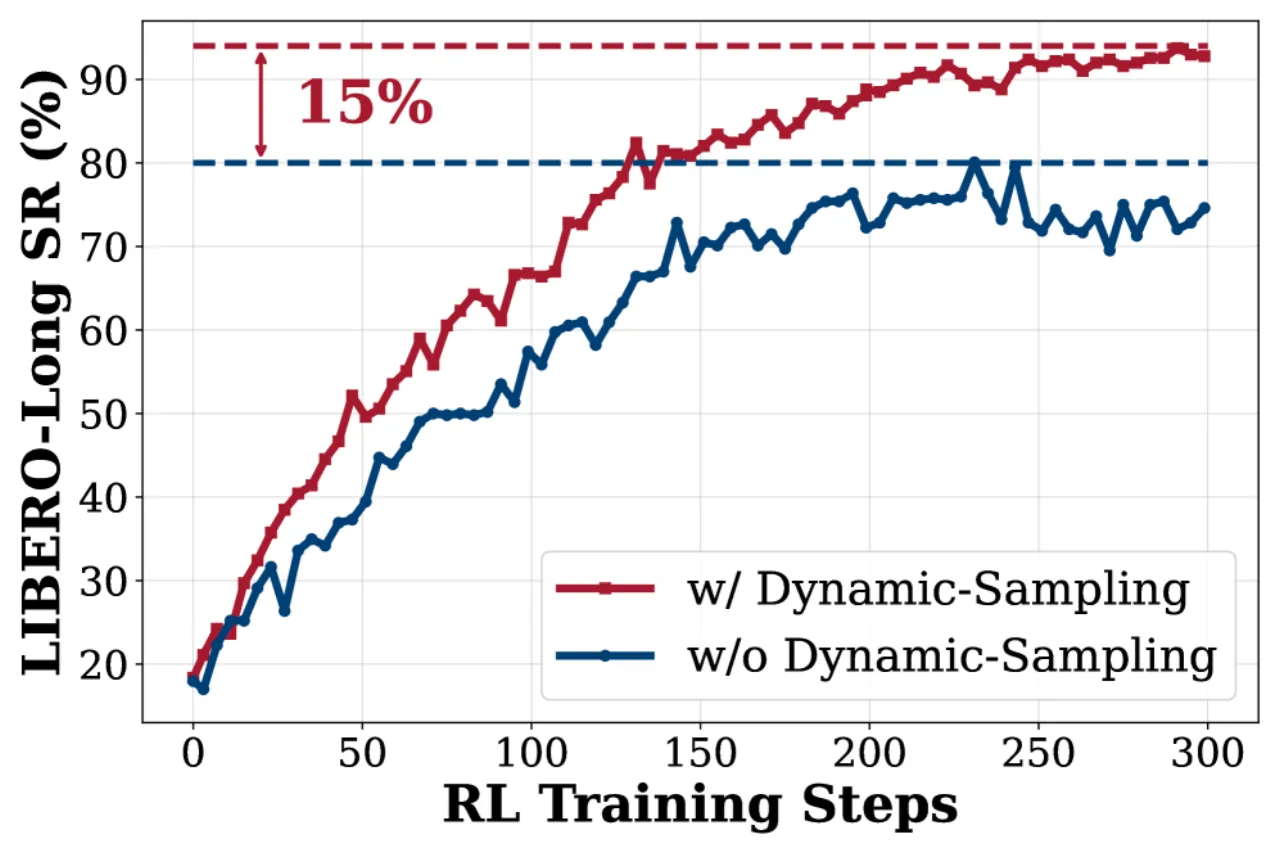
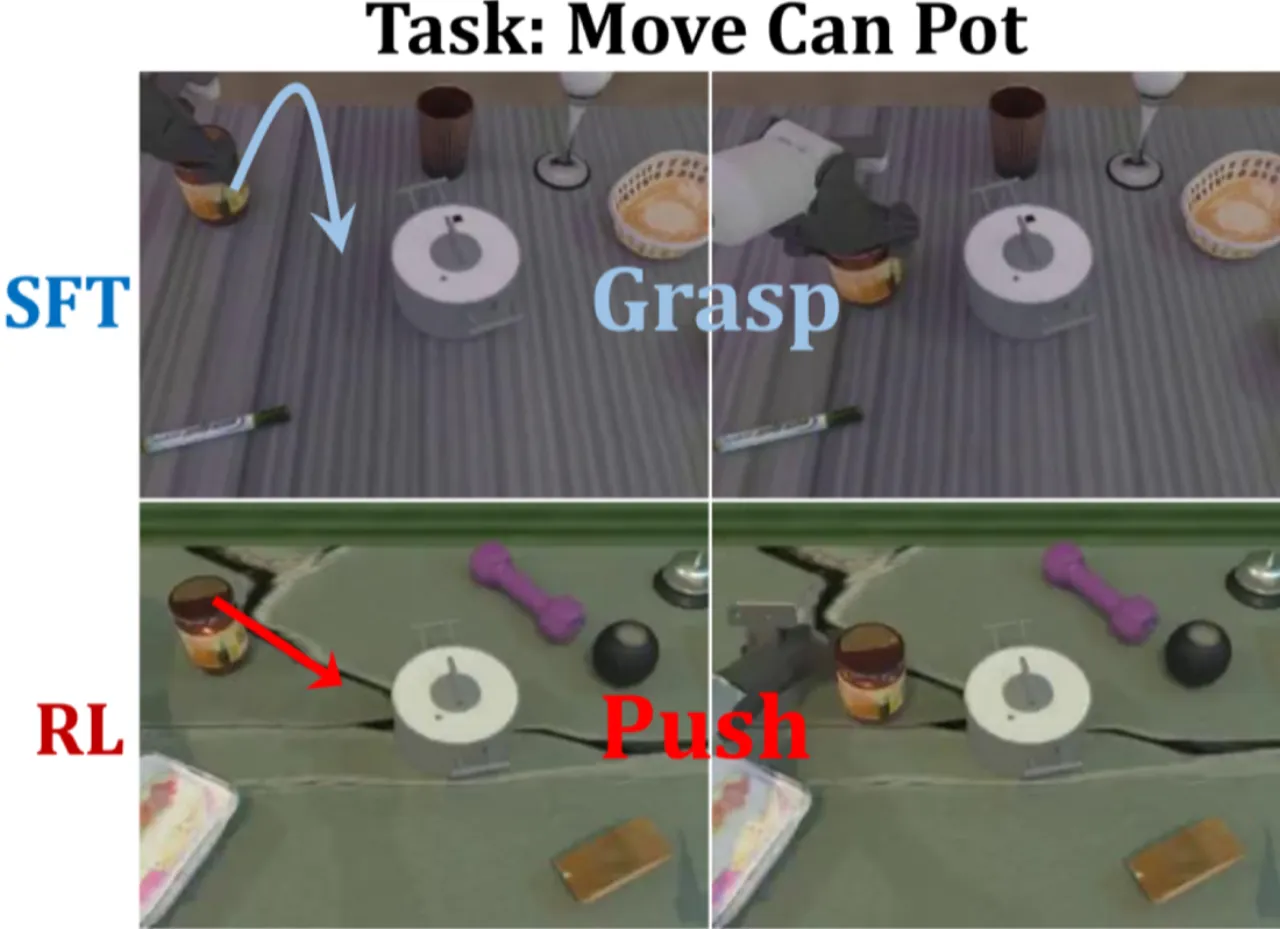
"我们提出 SimpleVLA-RL,通过 VLA 专用的轨迹采样、可扩展并行化、多环境渲染和优化的损失计算,将 veRL 框架扩展至 VLA 模型,实现高效在线 RL 训练。"
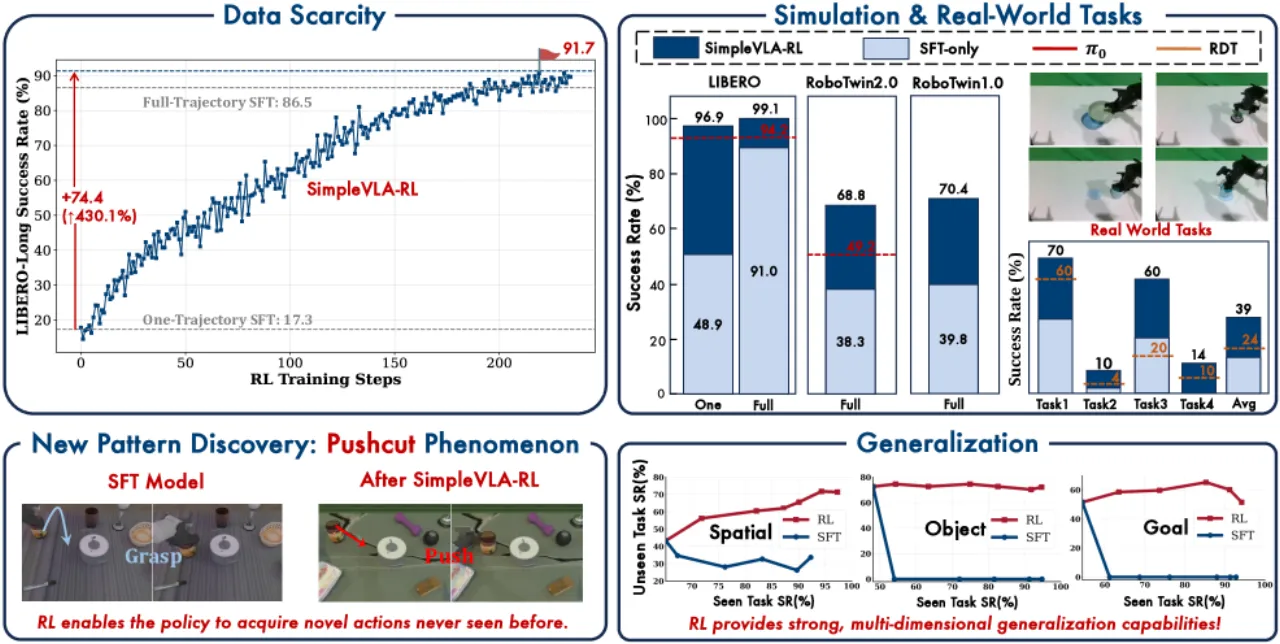
99.1%LIBERO 平均成功率
(原 SFT 基线:91.0%)
(原 SFT 基线:91.0%)
68.8%RoboTwin 2.0 平均成功率
(原 SFT 基线:38.3%)
(原 SFT 基线:38.3%)
38.5%Sim-to-Real 迁移成功率
(无真实机器人数据)
(无真实机器人数据)
+74.4%LIBERO-Goal 单轨迹数据场景
RL 相对 SFT 的提升幅度
RL 相对 SFT 的提升幅度