01 动机
人类玩家可以在几分钟内学会 Atari 游戏,而最优秀的 model-free RL 算法需要数千万乃至数亿次交互才能达到相近水平——相当于数周的实时训练。这种巨大的样本效率差距是 model-based RL 研究的核心动机。
"So far, there has been no clear demonstration of successful planning with a learned model in the ALE." — Machado et al. (2018) 对 Atari 基准上 model-based 控制的挑战性评述
论文的核心假设:人类之所以能快速学会游戏,部分原因在于拥有对物理过程的直觉理解,能够预测动作的结果。SimPLe 通过学习视频预测模型来实现类似的能力,从而大幅降低与真实环境的交互次数。

100K真实环境交互上限
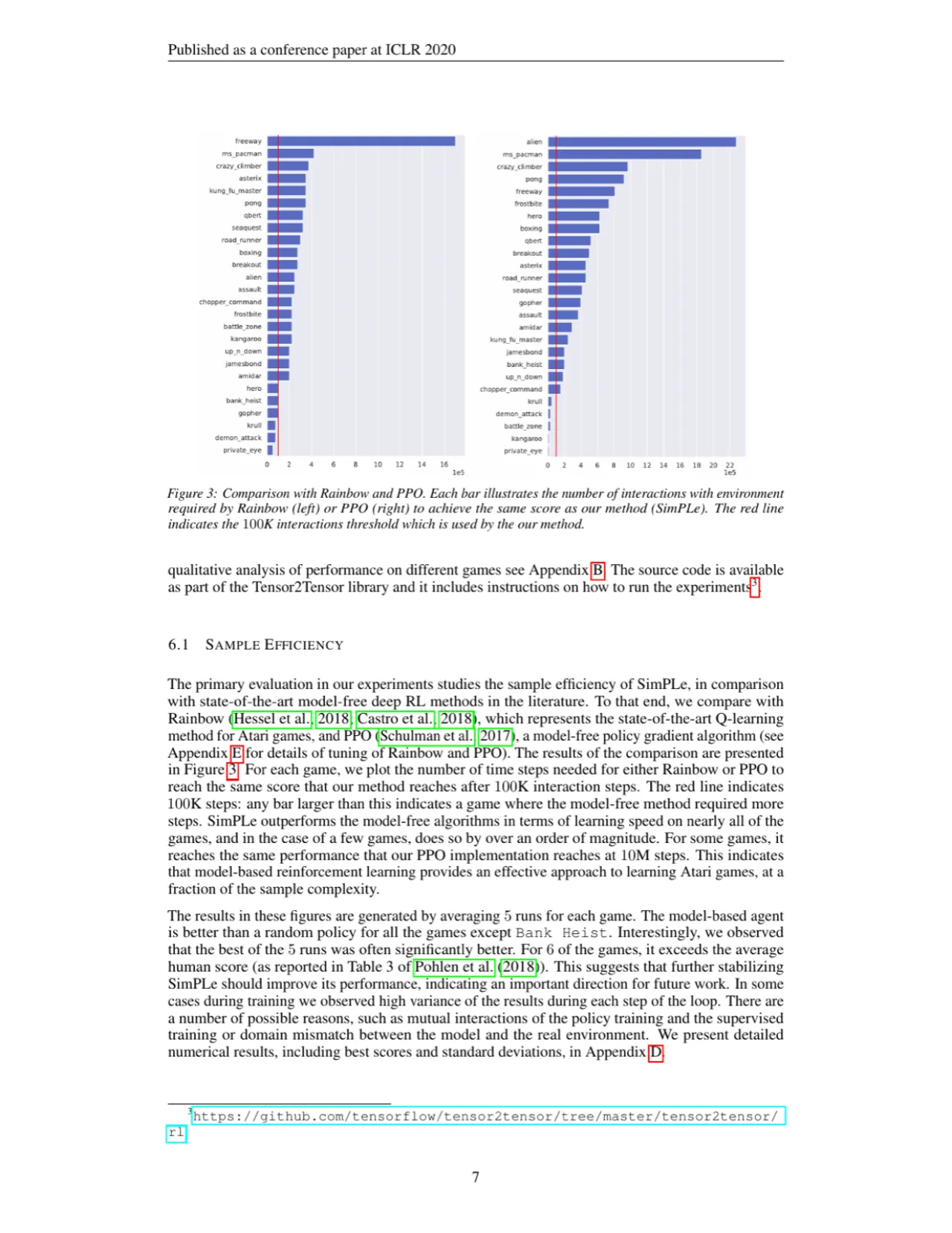
>10×Freeway 游戏上的样本效率提升(对比 Rainbow)
26评测的 Atari 游戏数
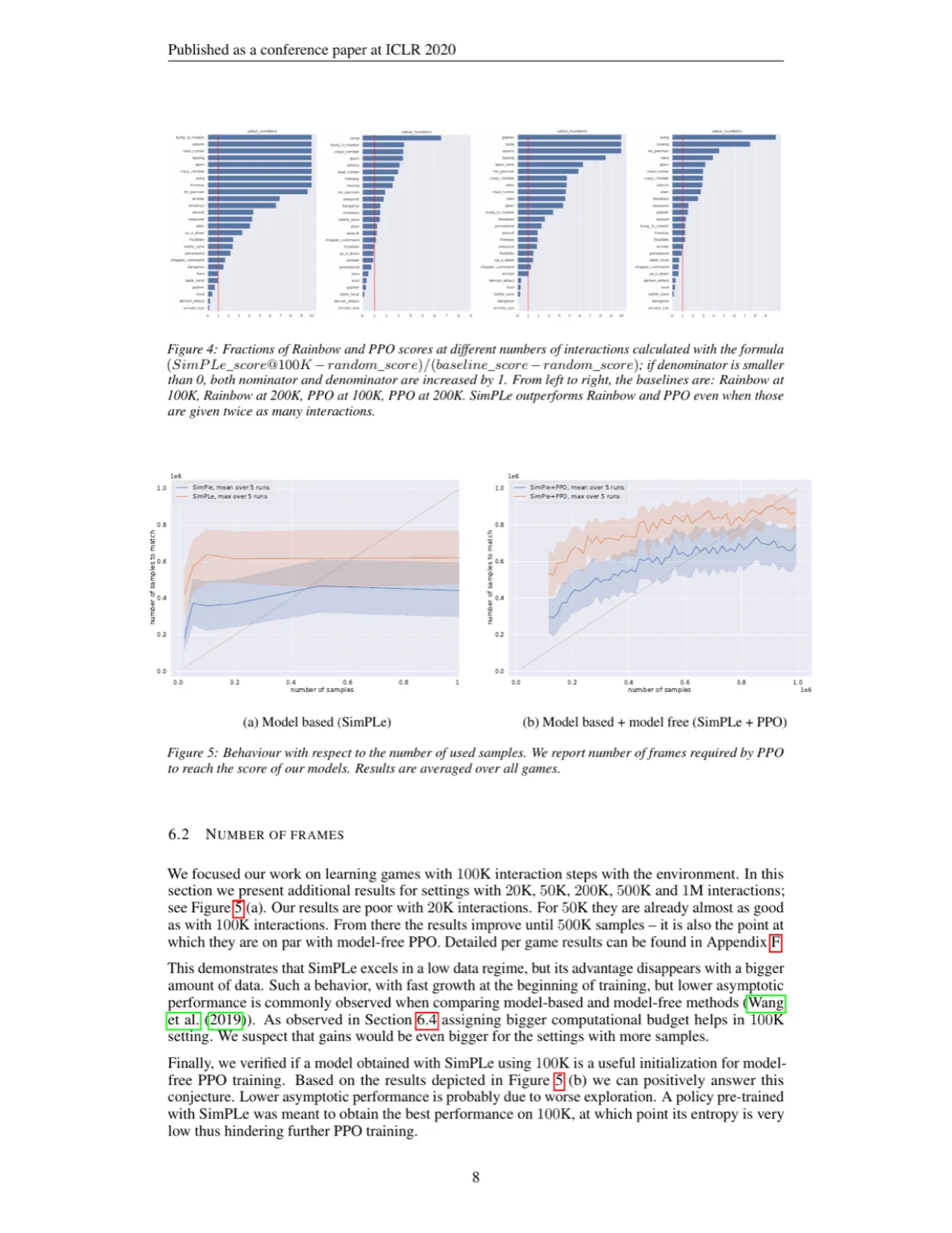
15SimPLe 迭代训练轮次