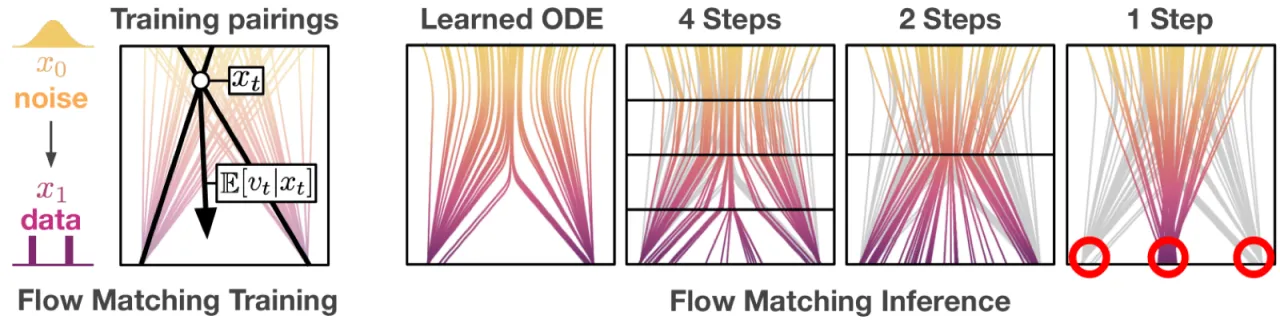
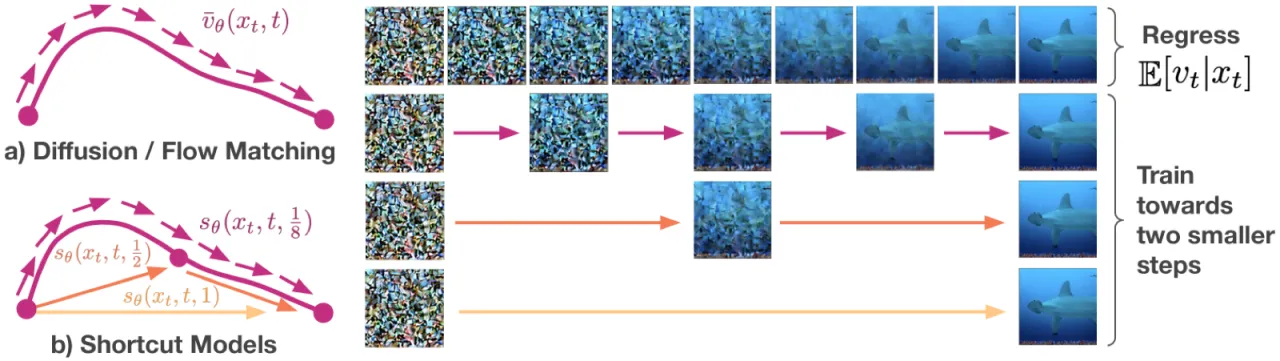
"The mapping between noise and data is entirely dependent on an expectation over the dataset."(论文原文)
与 GAN 或 VAE 不同,Shortcut Models 无法对噪声到数据的映射做独立的干预或调整,
生成的多样性上限受限于训练数据的分布。
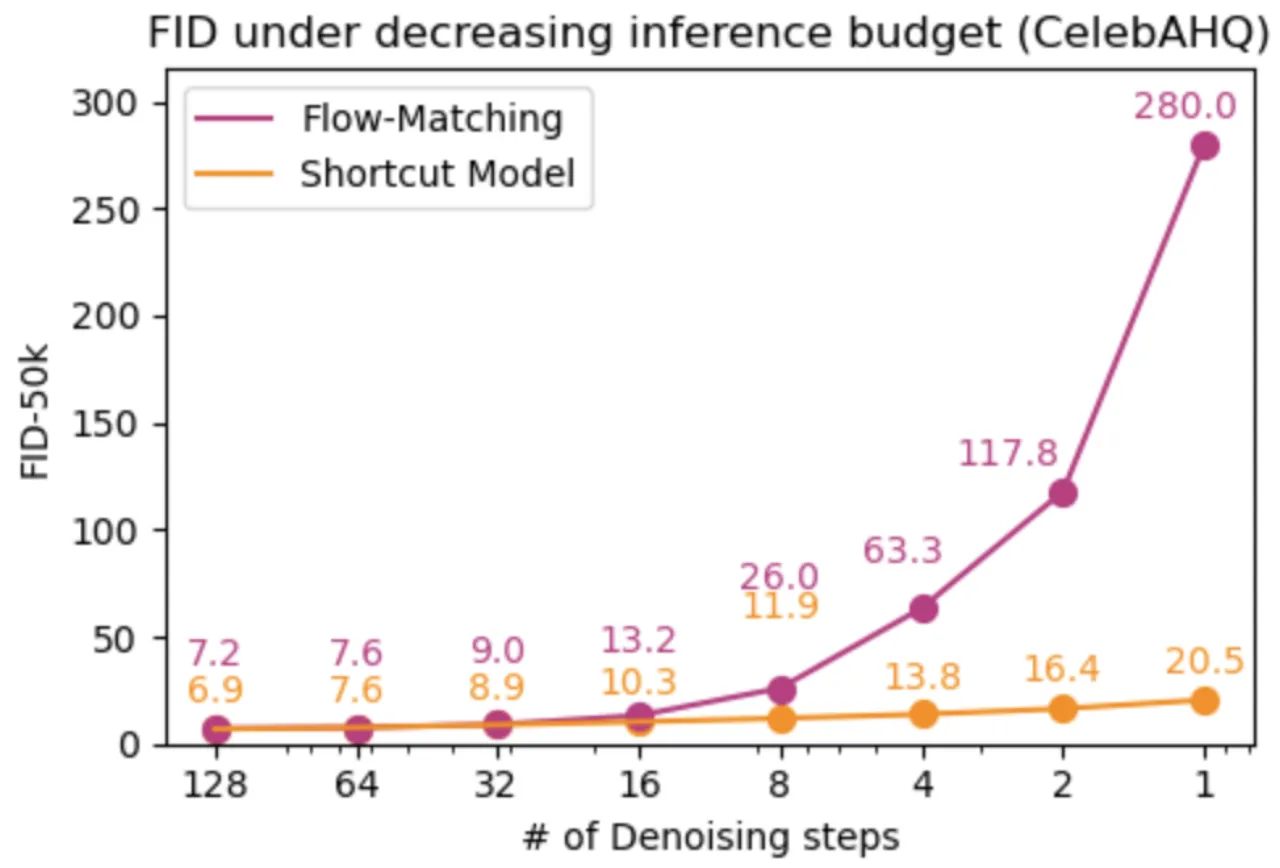
多步与单步生成质量仍存在差距(作者明确陈述)
"In our shortcut model implementation there remains a gap between many-step generation quality and one-step generation quality."(论文原文)
尽管 Shortcut Models 的差距远小于标准扩散模型,但 1 步的 FID 仍明显高于 128 步,
完全消除该差距仍是开放问题。
Classifier-Free Guidance (CFG) 仅适用于小步长(作者明确陈述)
论文指出,CFG 在大步长时不能直接使用,因为"linear approximation is not appropriate"(论文原文)。
实现中只在 d=0(极小步长)时使用 CFG,大步长时必须放弃 CFG 加成,
这在一定程度上限制了 1 步生成的可控性。
此外,CFG 的比例(scale)需要在训练前指定,不能在推理时灵活调整。