01 动机
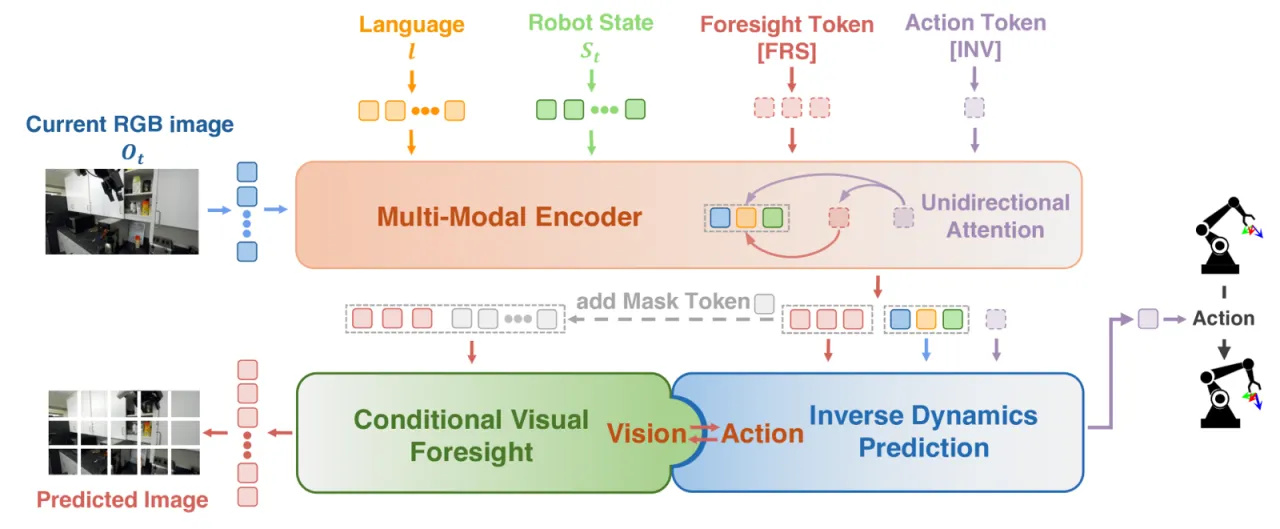
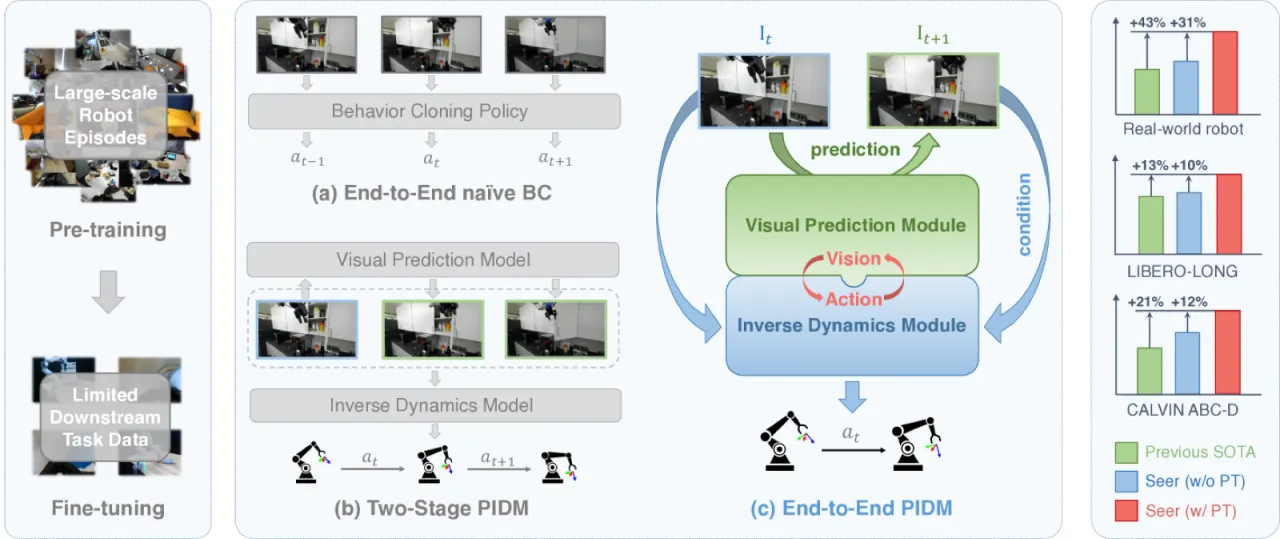
机器人操作学习面临两条主流路线的天然裂痕:以动作为中心的行为克隆(behavior cloning)能直接产生动作,但难以利用丰富的视觉先验;以视觉为中心的世界模型或表征预训练能捕捉丰富的视觉语义,却与最终动作预测存在鸿沟。如何将两者无缝融合,是本文要回答的核心问题。
"We propose an end-to-end framework called Predictive Inverse Dynamics Models (PIDM), which integrates conditional visual foresight and inverse dynamics prediction to close the vision-action loop."
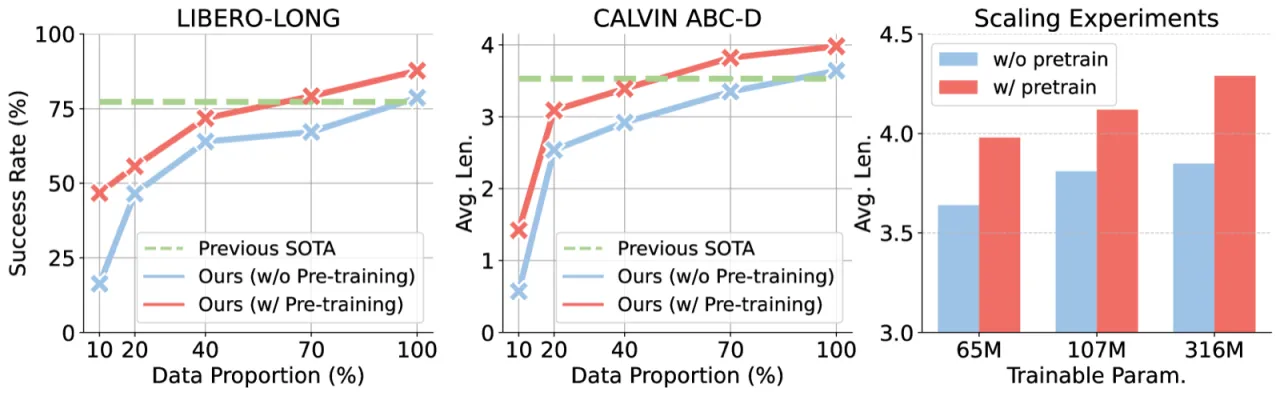
87.7%LIBERO-LONG 成功率
(+9% vs. 最强基线 MPI 77.3%)
(+9% vs. 最强基线 MPI 77.3%)
4.28CALVIN ABC-D 平均任务完成数
Seer-Large,SOTA
Seer-Large,SOTA
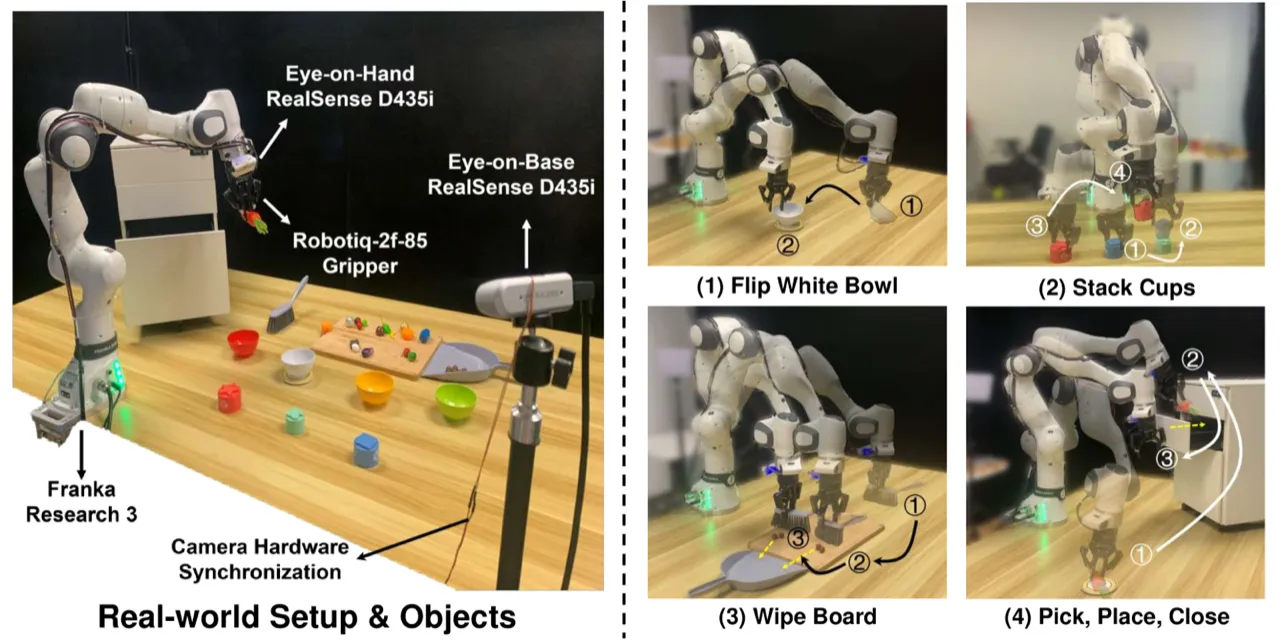
78.4%真实机器人平均成功率
(vs. 从零训练 60.0%)
(vs. 从零训练 60.0%)
187%仅用 10% 数据时
相对从零训练的 LIBERO 提升
相对从零训练的 LIBERO 提升