01 动机
机器人在日常杂乱环境中操作,需要对三维场景进行精确理解,才能稳定可靠地抓取和放置物体,并避免碰撞。然而现实中往往只能获得单张RGB-D图像,场景中物体相互遮挡,且多为训练数据之外的新颖物体——这是当前三维场景重建方法面临的核心挑战。
"Careful robot manipulation in every-day cluttered environments requires an accurate understanding of the 3D scene, in order to grasp and place objects stably and reliably and to avoid colliding with other objects. In general, we must construct such a 3D interpretation of a complex scene based on limited input, such as a single RGB-D image."

先前方法的不足
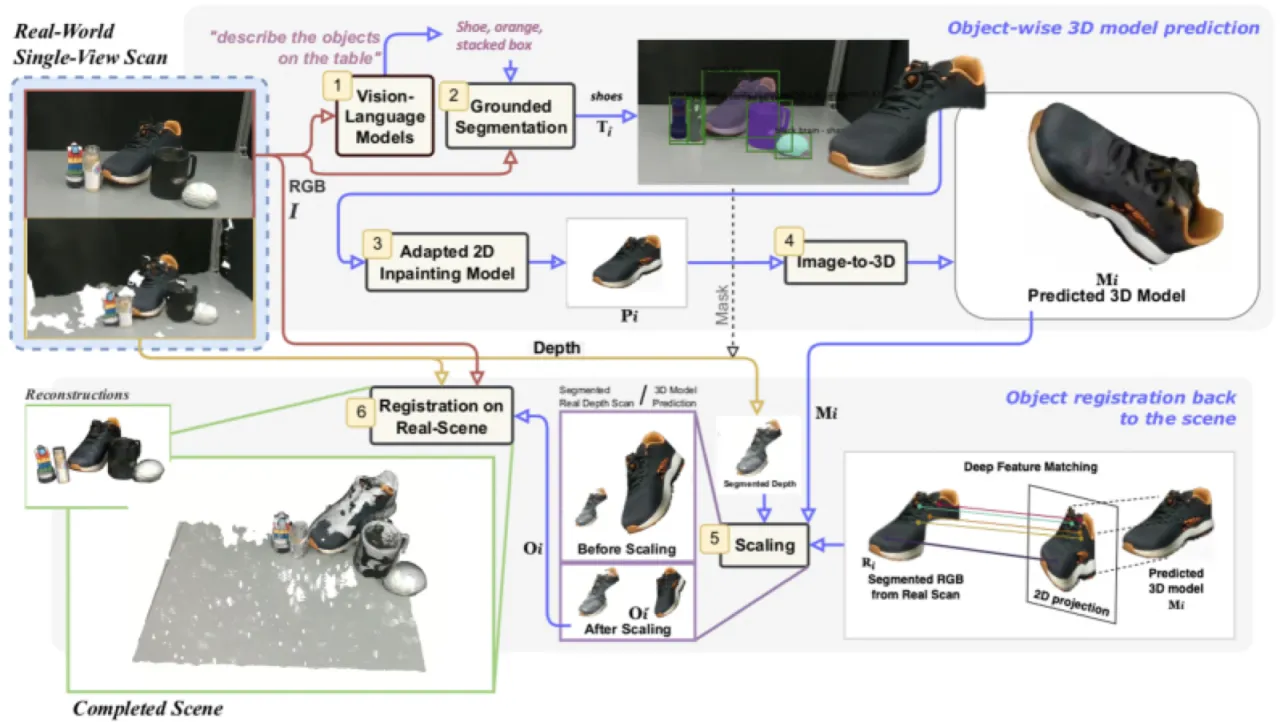
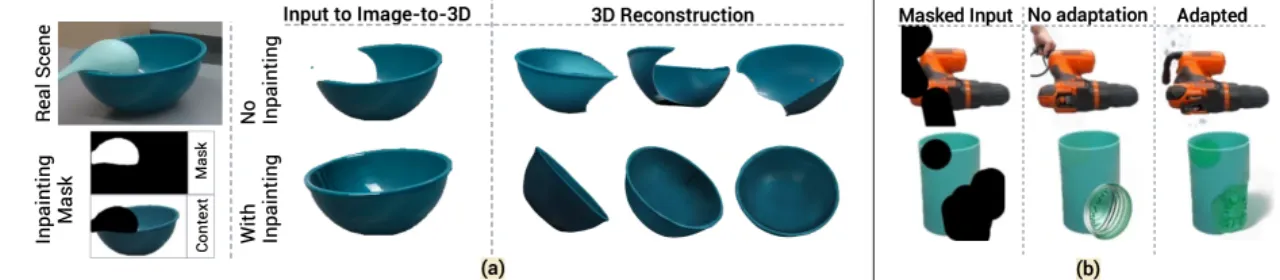
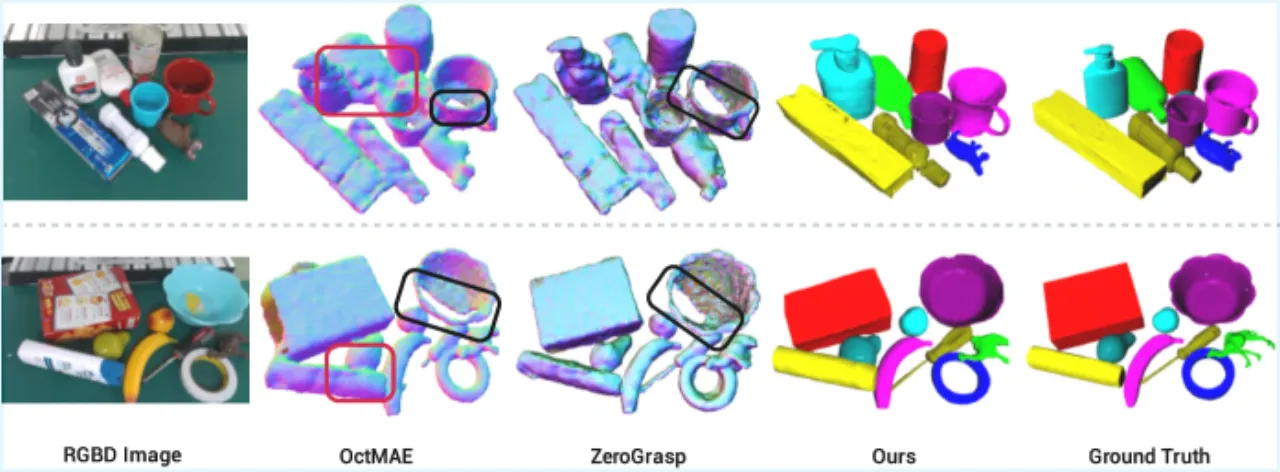
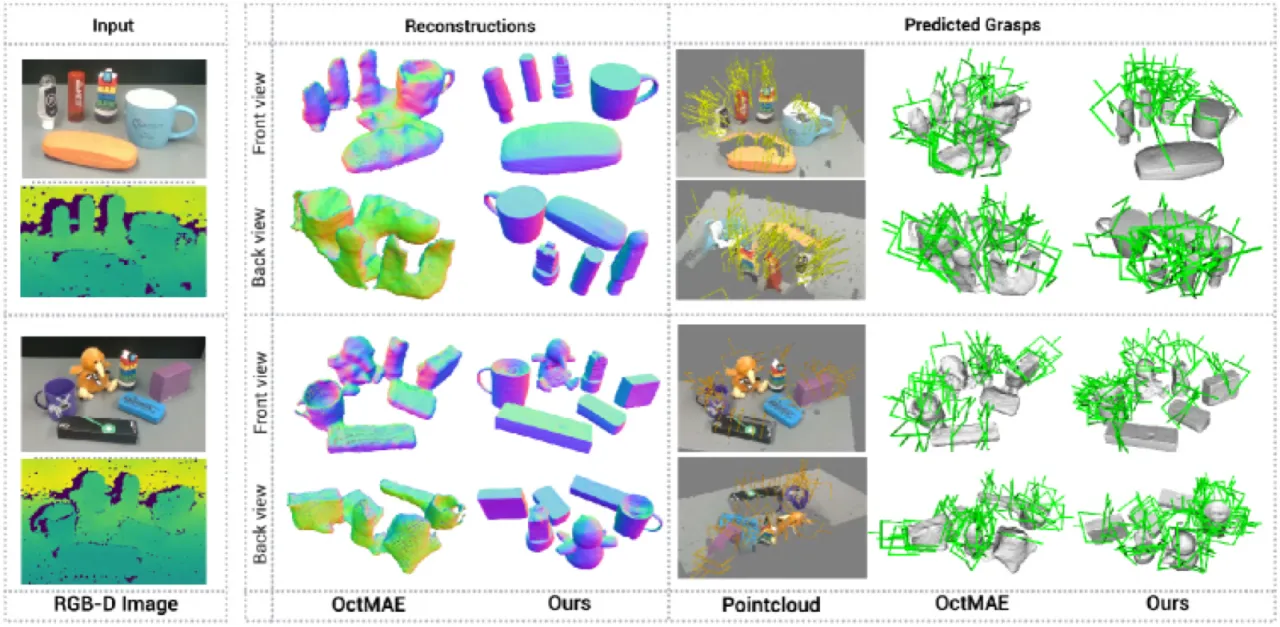
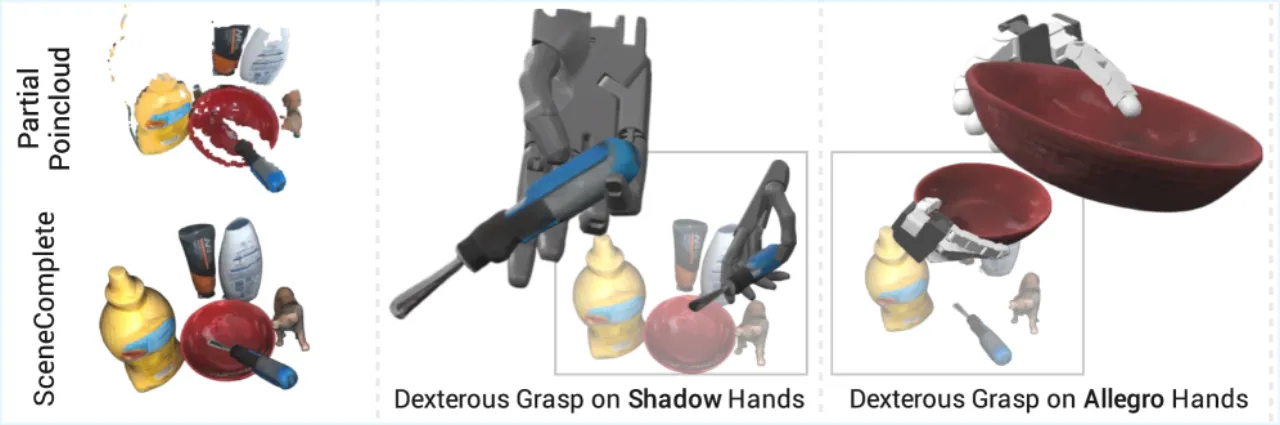
现有方法(如 PartialDecomp、OctMAE、ZeroGrasp)在开放世界场景下存在明显局限:要么仅能预测场景级占据值而无法给出精确物体网格,要么依赖有限的物体类别,难以泛化到真实杂乱环境中的新颖物体。SceneComplete 的核心思路是组合(composing)已有的大型预训练视觉模型,而非端到端训练一个新模型,从而天然具备开放词汇泛化能力,并能随基础模型的改进而不断提升。
0.478MIoU↑ (GraspNet-1B)
高于所有基线
高于所有基线
77%总体抓取成功率
(YCB-V, vs. 32% 基线)
(YCB-V, vs. 32% 基线)
73.3%真实机器人
抓取放置成功率
抓取放置成功率
1.54CD↓ (Chamfer Distance)
最低几何误差
最低几何误差