01 动机
计算机视觉长期依赖多视角几何来恢复 3D 结构,而人类凭借阴影、纹理乃至"熟悉物体"等图像线索便可从单张图片感知深度与形状。现有单视角重建方法(如 Trellis、HunyuanD3-2.1)在隔离合成对象上表现尚可,但在自然场景中面临严重遮挡与杂乱背景时却力不从心——根本原因在于大规模真实图像配对 3D 数据的匮乏。
"A fundamental challenge for learning such models is the lack of data: specifically, natural images paired with 3D ground truth are difficult to obtain at scale."

5:1真实物体人工偏好胜率(vs. 最佳基线)
6:1场景重建人工偏好胜率(vs. 最佳基线)
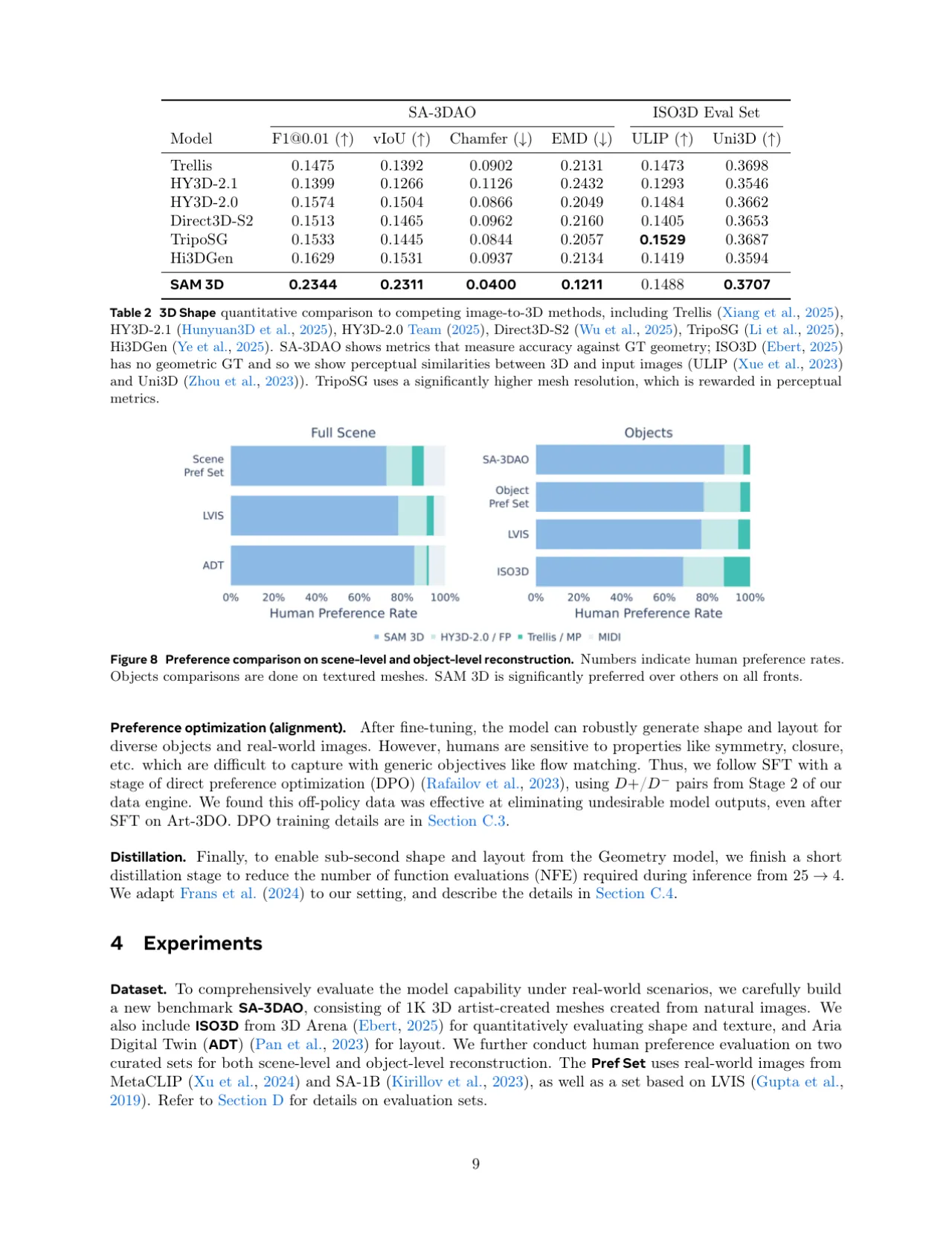
1,000SA-3DAO 基准:艺术家手工制作的 3D mesh
~3.14MMITL 数据引擎标注的无纹理 mesh 总量