Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, Sergey Levine · UC Berkeley / Google Brain
"SAC as presented in [haarnoja2018soft] can suffer from brittleness to the temperature hyperparameter… a sub-optimal temperature can drastically degrade performance."
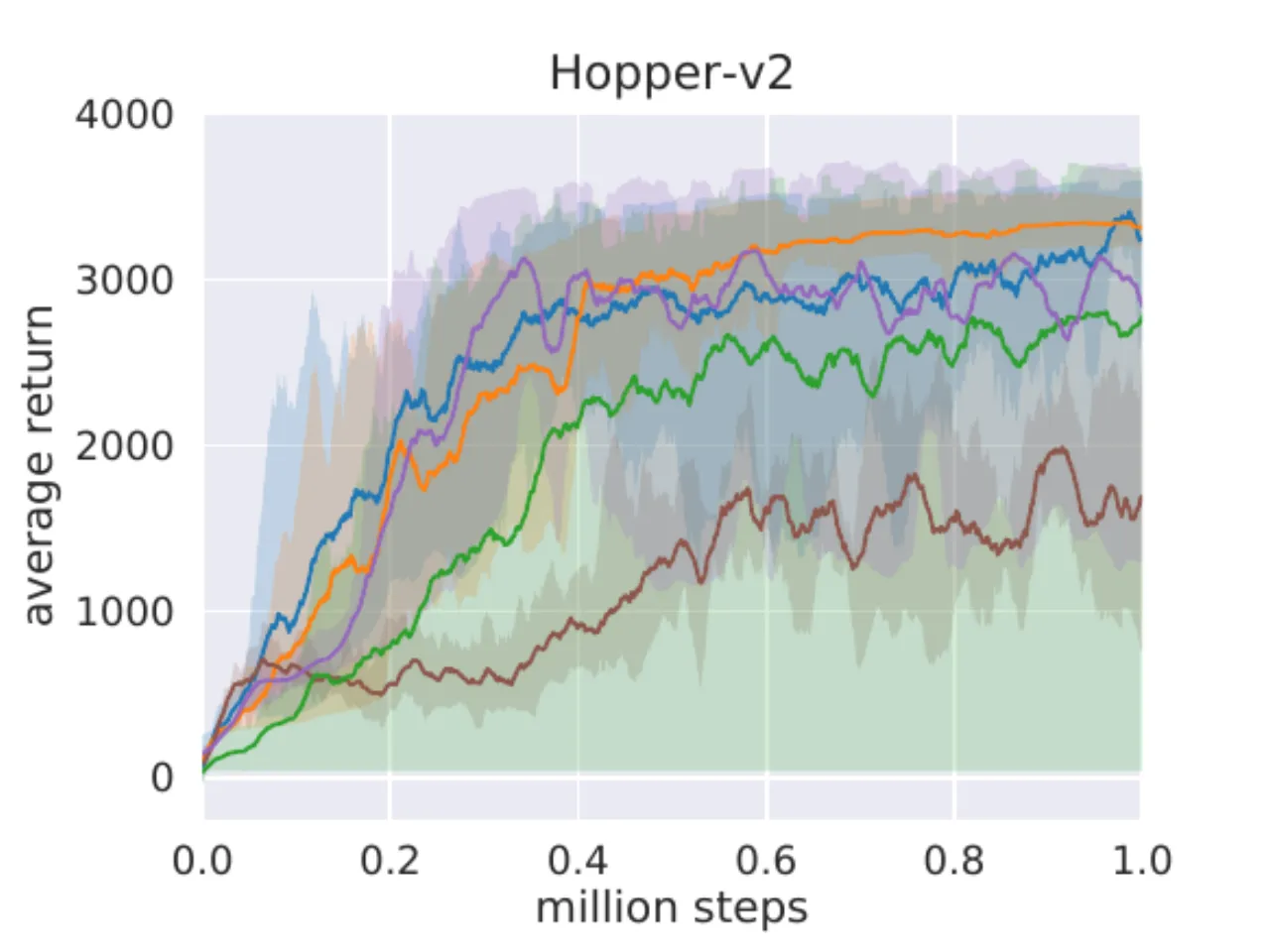
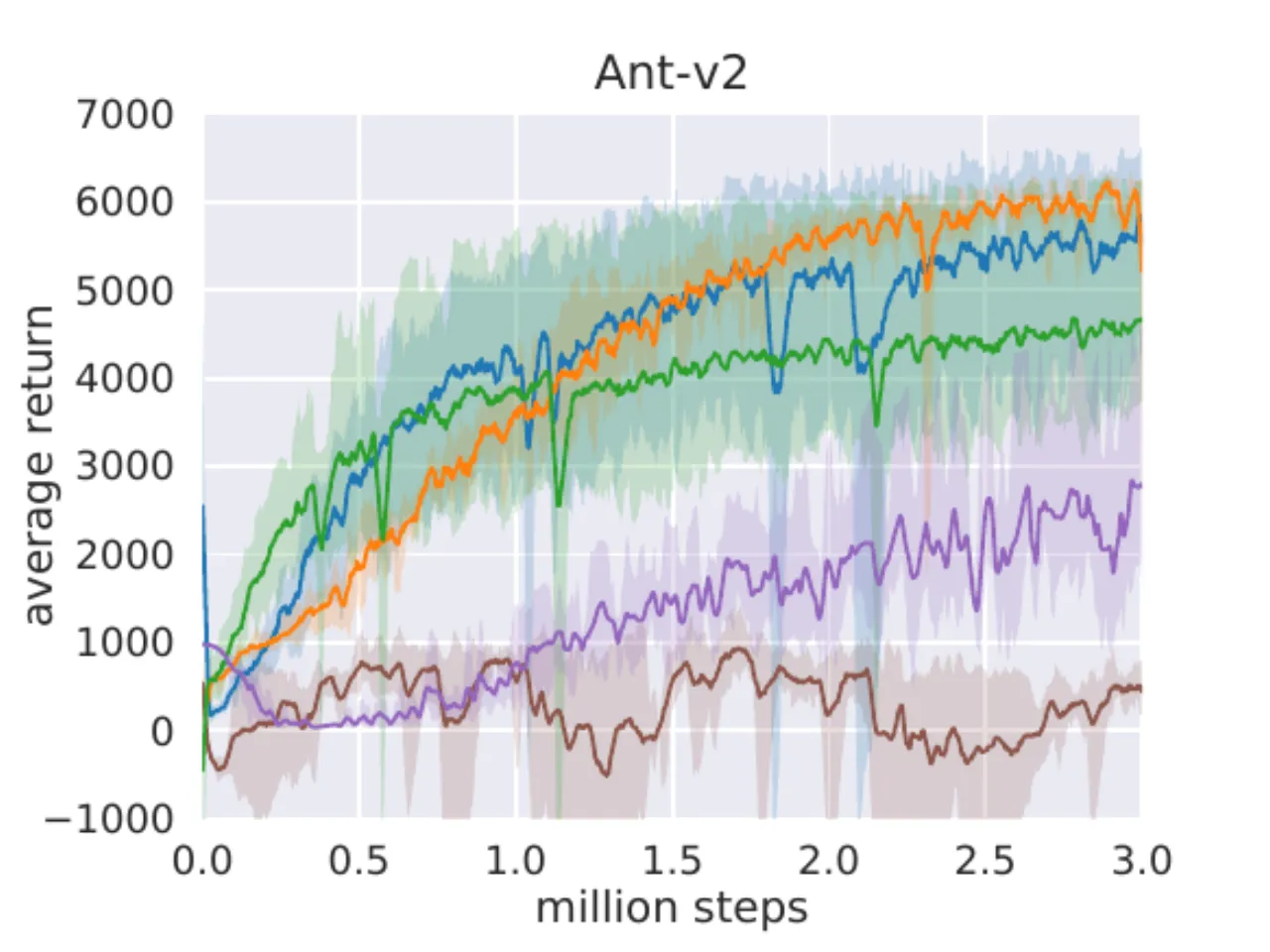
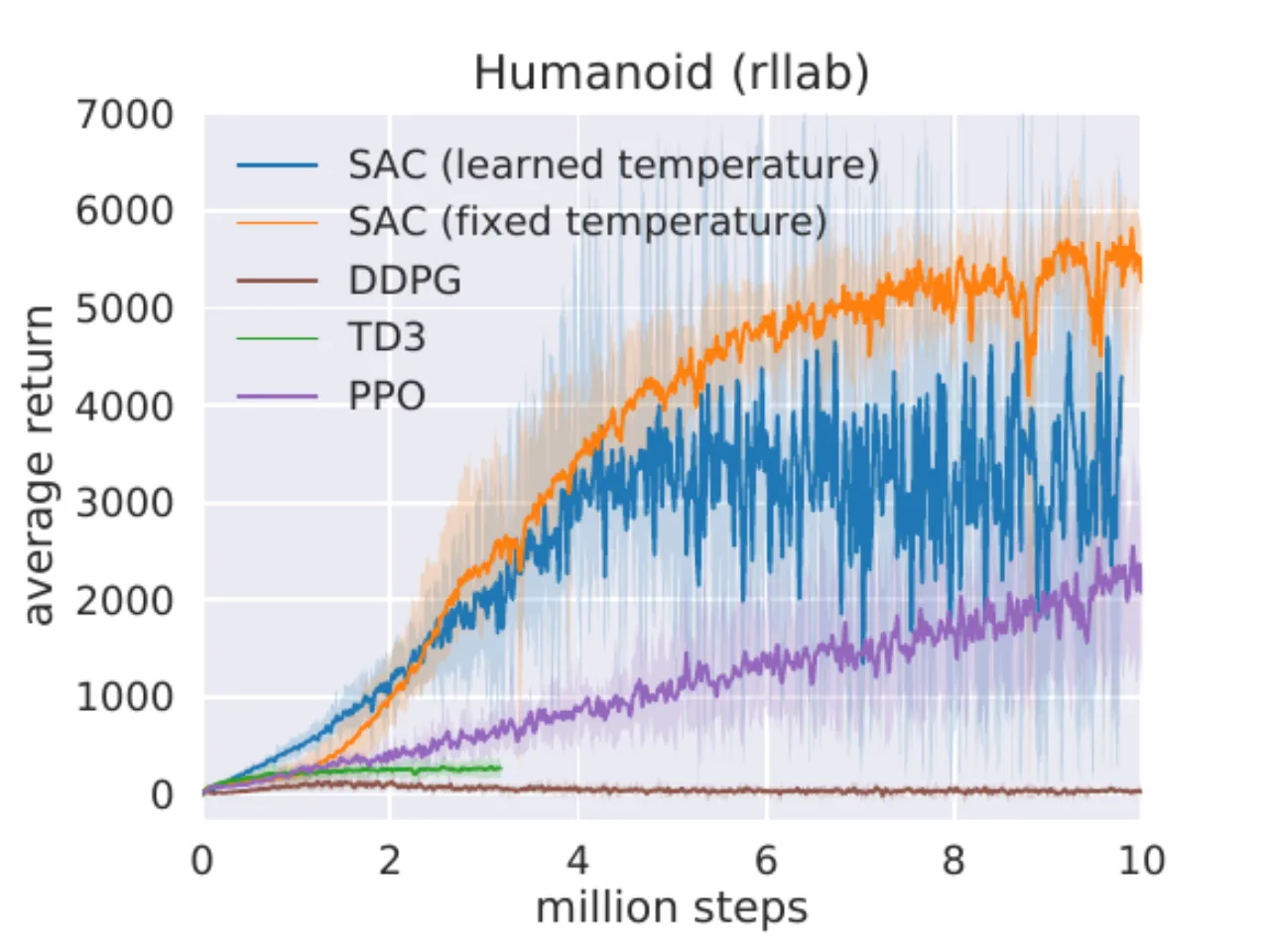
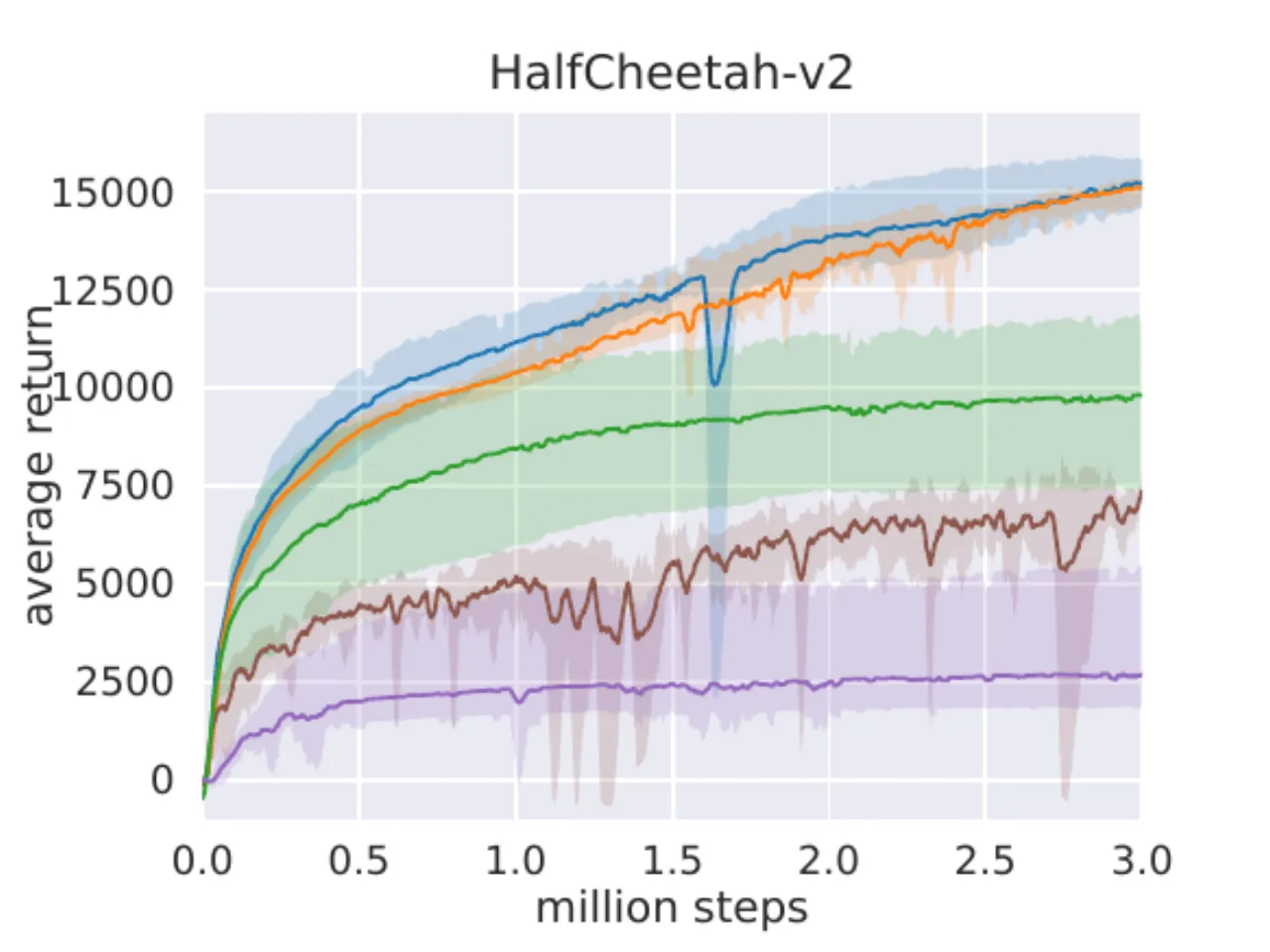
"SAC performs comparably to the baseline methods on the easier tasks and outperforms them on the harder tasks with a large margin, both in terms of learning speed and the final performance."
DDPG 在 Ant-v1、Humanoid-v1 和 Humanoid(rllab)上完全失败(与 prior work 一致);
SQL 能学会所有任务但收敛更慢且渐近性能更差;
SAC 自动温度版(蓝)与固定温度版(橙)表现相当,验证自动调节的有效性。
真实机器人:Minitaur 四足行走
Minitaur(8 个直驱电机,腿部可在矢状面运动)在平地上的学习帧序列。
策略在约 160k 环境步数(约 2 小时真实训练时间)后学会行走。
论文还测试了斜坡(slope)、木块障碍(obstacles)、台阶(stairs)——
均无需额外训练即可泛化,"due to entropy maximization at training time, the policy can readily generalize to these perturbations."
图源:论文 Figure 3。
"Although this algorithm will provably find the optimal solution, we can perform it in its exact form only in the tabular case."
神经网络函数逼近引入的误差不在理论保证范围之内,实践中的收敛依赖于近似对偶梯度下降的启发性论证。[stated]