01 动机
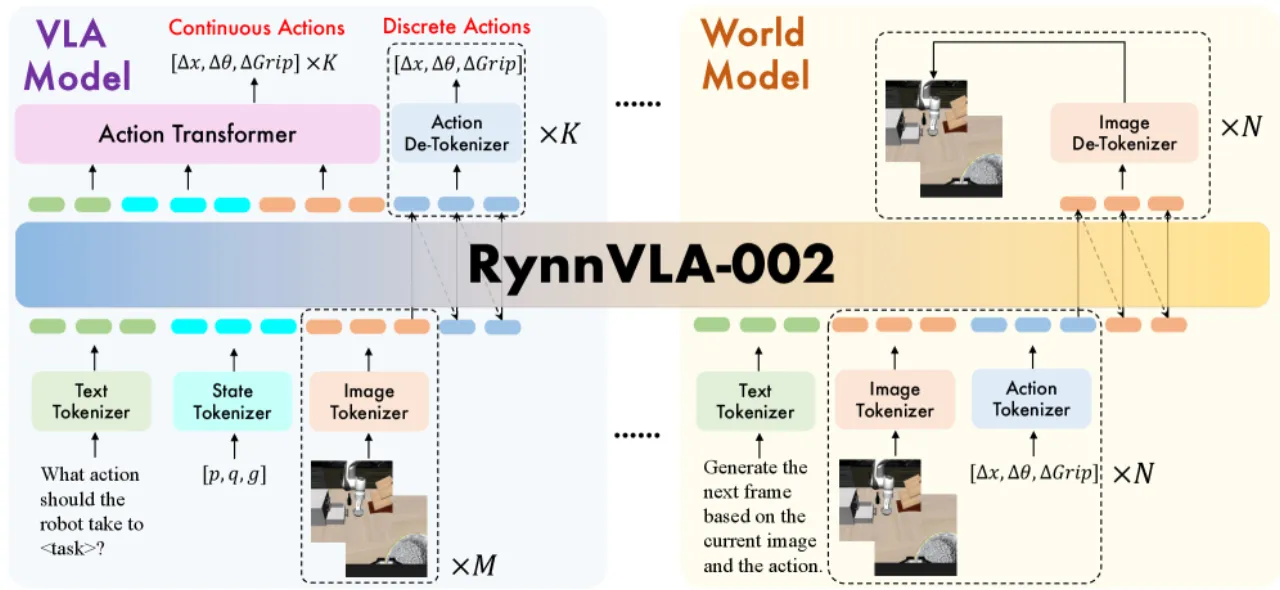
VLA 模型与 World Model 各有所长,却长期相互割裂:前者能生成动作,却缺乏对世界物理动态的内部"想象";后者能预测未来视觉状态,却无法直接输出控制指令。这种"功能鸿沟"限制了两类模型在真实机器人场景中的潜力。
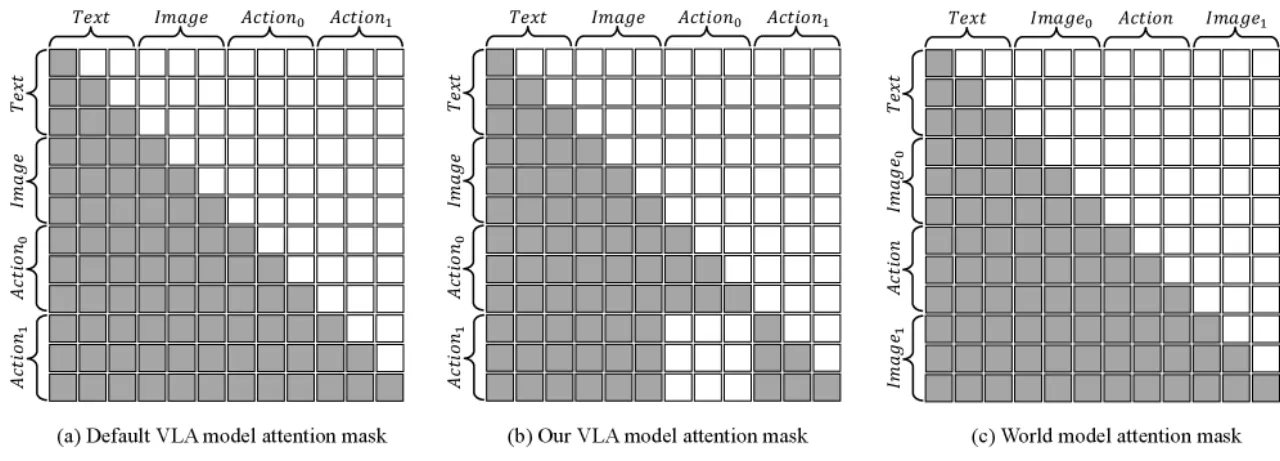
"RynnVLA-002 internalizes the VLA objective and the action-conditioned world-modeling objective in one Chameleon-style autoregressive backbone with a shared token space."
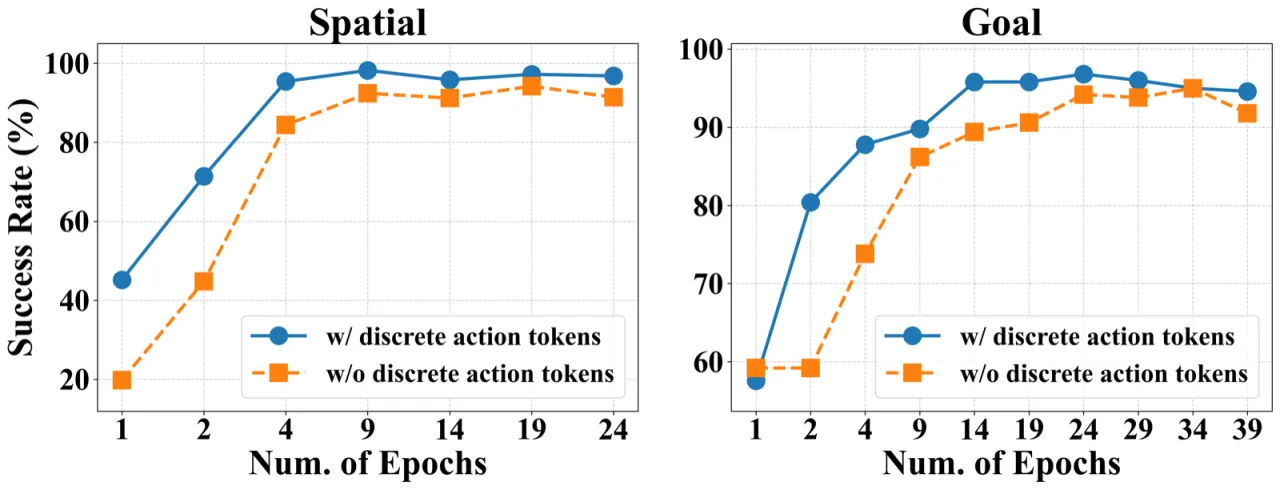
97.4%LIBERO 平均成功率(无预训练)
+50%真实机器人整体成功率提升
90.0%真实多目标 Place block 任务成功率
65,536统一词汇表 token 数量
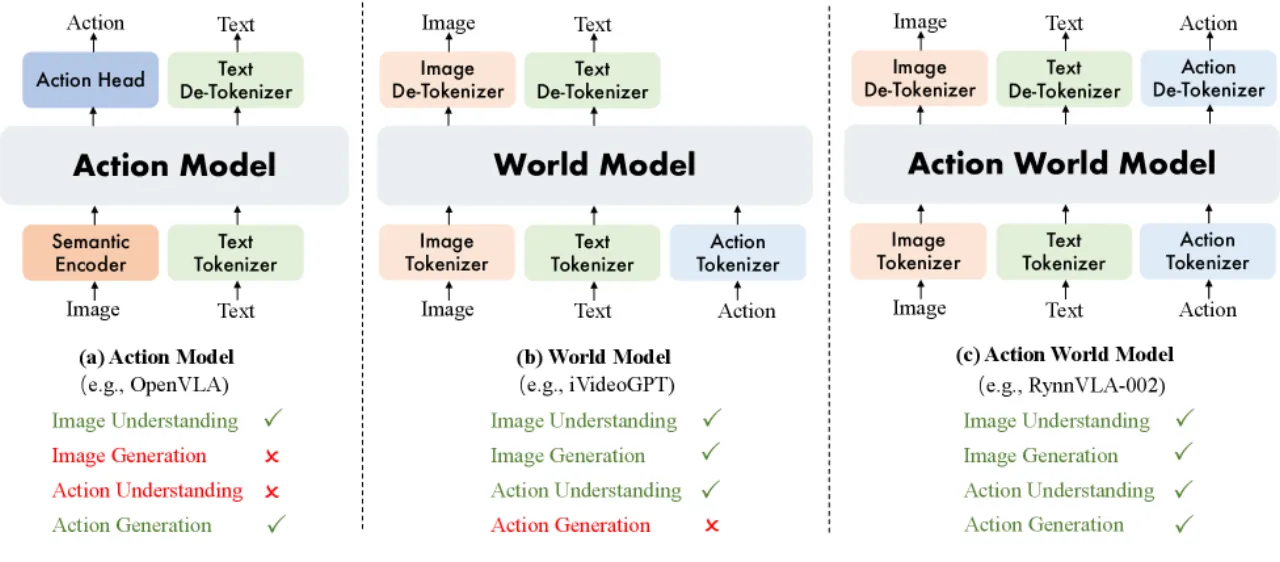
现有 VLA 方法(如 RT-2)将动作仅置于输出端,模型内部无法建立对动作效果的推理;而现有 World Model(如 Genie)只预测视觉状态,缺乏直接的机器人控制能力。RynnVLA-002 的核心洞察是:VLA 的精准动作能力可以改善 World Model 的视觉一致性,World Model 的预见性又能反哺 VLA 的动作决策,两者在同一主干内协同训练即可实现"1+1>2"的效果。