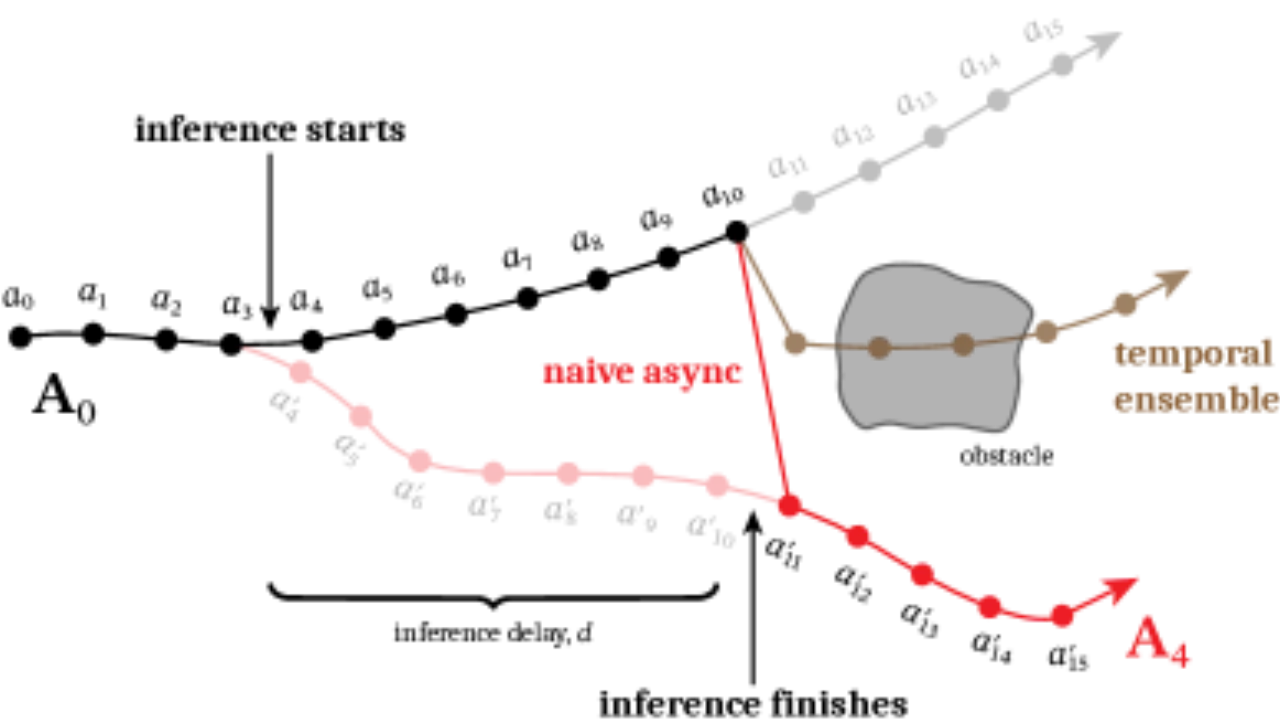
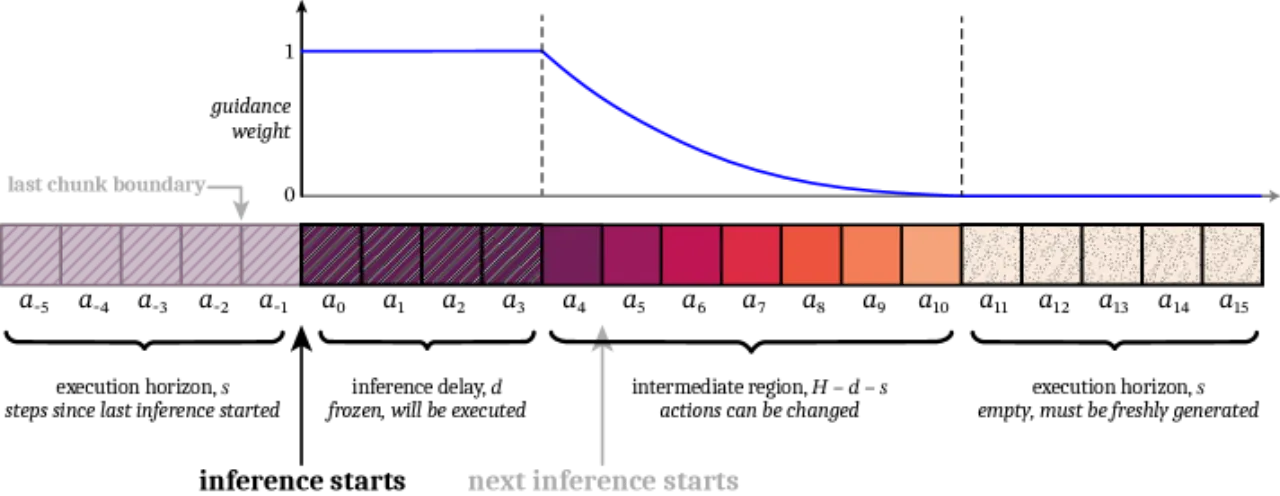
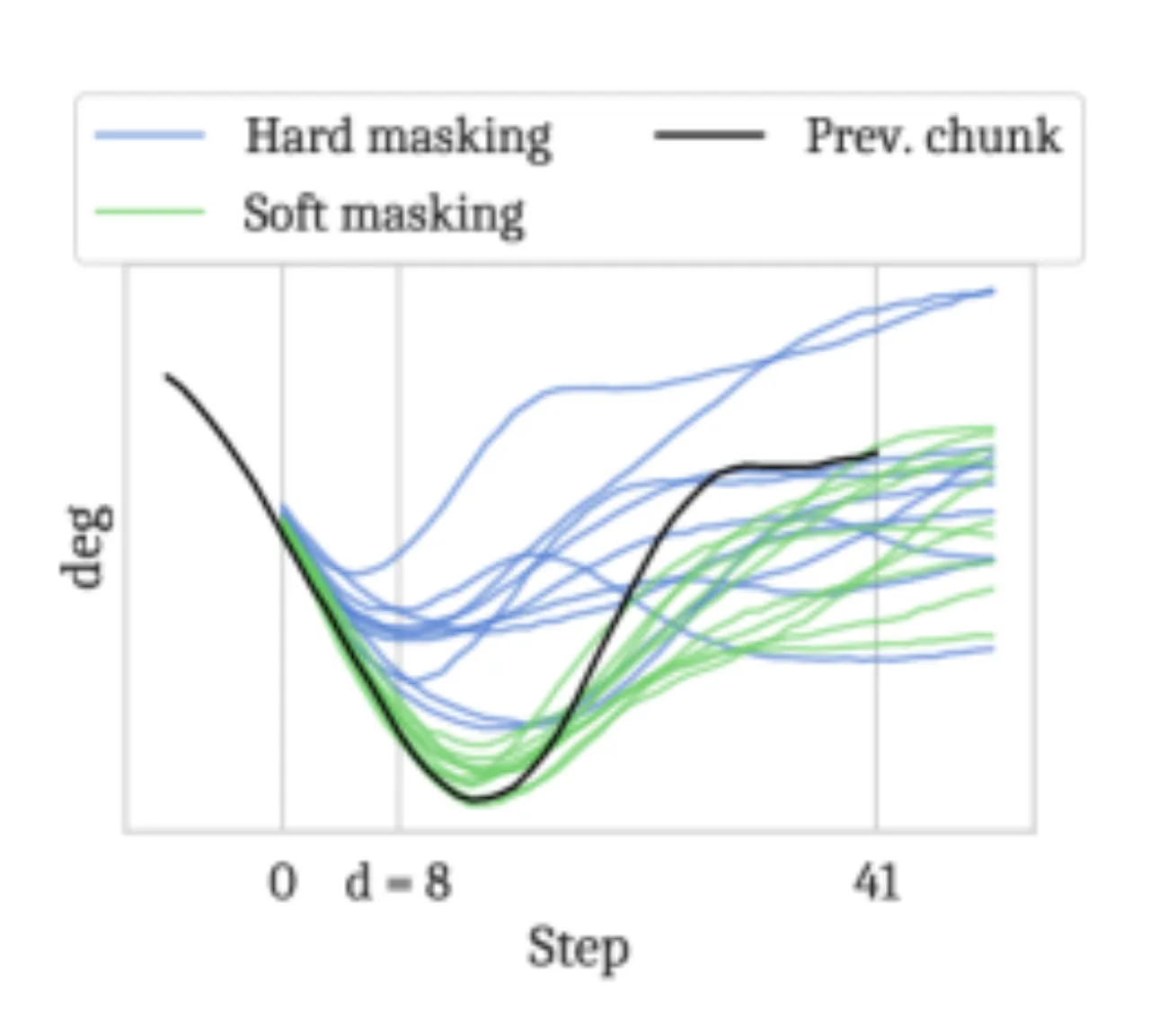
"While action chunking has enabled temporal consistency in high-frequency control tasks,
it does not fully address the latency problem, leading to pauses or out-of-distribution jerky
movements at chunk boundaries."
使用 π0.5(H=50,Δt=20 ms,n=5 denoising steps)在双臂系统(两个 6-DoF 臂 + 并联夹爪)上评测。
基准推断延迟约 d≈6(LAN 推断含 10–20 ms 网络延迟);
额外注入 +100 ms 和 +200 ms 延迟,分别对应 d≈11 和 d≈16,模拟更大模型或远程云推断场景。
任务
说明
Synchronous
TE (dense)
RTC
Light candle
点火(5 子步,40s 限时,无重试)
最低成功率
+100/+200ms 触发 protective stop
最高最终得分,显著优势
Plug ethernet
插以太网线(6 子步,120s)
线性降级
+100/+200ms 不可运行
完全不受延迟影响
Make bed (mobile)
移动床上毯子和枕头(3 子步,200s)
最难任务,易失败
+100/+200ms 不可运行
更早完成更多子步
Shirt folding
衬衫折叠(1 步,300s)
基线
+100/+200ms 不可运行
更快达成
Batch folding
取衣物 → 展平 → 折叠 → 堆放(4 步,300s)
基线
+100/+200ms 不可运行
吞吐量最佳
Dishes in sink (mobile)
移动 4 件餐具进水槽(8 步,300s)
基线
+100/+200ms 不可运行
任务吞吐最佳
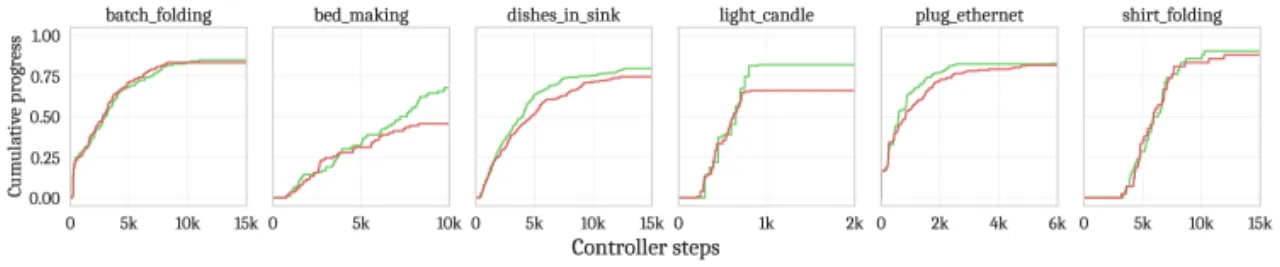
综合指标为 average throughput(任务完成比例/总时长的均值)。
RTC 在所有推断延迟下均达到最佳 throughput,且在 +100 ms 和 +200 ms 条件下差异具有统计显著性。
RTC 对注入延迟完全鲁棒,无性能下降;synchronous 随延迟线性退化;
两种 TE 变体在 +100 ms / +200 ms 注入延迟下因震荡过大触发机器人 protective stop,完全无法运行。
Figure 6(右):推断延迟 vs. 平均任务吞吐量(所有真实任务汇总)。
RTC 在全部延迟条件下均为最优,且完全不随延迟增加而退化。
两种 TE 变体在 +100 ms 和 +200 ms 时因激烈振荡触发 protective stop 而无法执行(标注为缺失)。
Error bars ± 1 SEM。
延迟测量(Table 1 — π0.5 on NVIDIA RTX 4090, bfloat16, n=5)
Note: 以下局限性均为论文作者在 Section 6(Discussion and Future Work)中明确陈述(stated by authors)。
额外计算开销显著
RTC 需要在每个 denoising step 中对 frozen prefix 做反向传播以计算引导梯度,
"it adds significant computational overhead compared to methods that sample directly from the base policy."
尽管绝对延迟增幅较小(约 0.5 ms),但对资源受限的边缘设备或更大模型而言仍是挑战。
仅适用于 diffusion- 和 flow-based 策略
"it is applicable only to diffusion- and flow-based policies."
基于自回归解码(如 OpenVLA)或向量量化(如 RT-2、ARP)的策略无法直接使用 RTC 的 inpainting 机制。
真实世界实验未覆盖腿足式移动场景
"while our real-world experiments cover a variety of challenging manipulation tasks,
there are more dynamic settings that could benefit even more from real-time execution.
One example is legged locomotion, which is represented in our simulated benchmark but not our real-world results."
当前真实世界评测局限于双臂操作,对步行机器人等需要更高频率闭环控制的平台尚未验证。