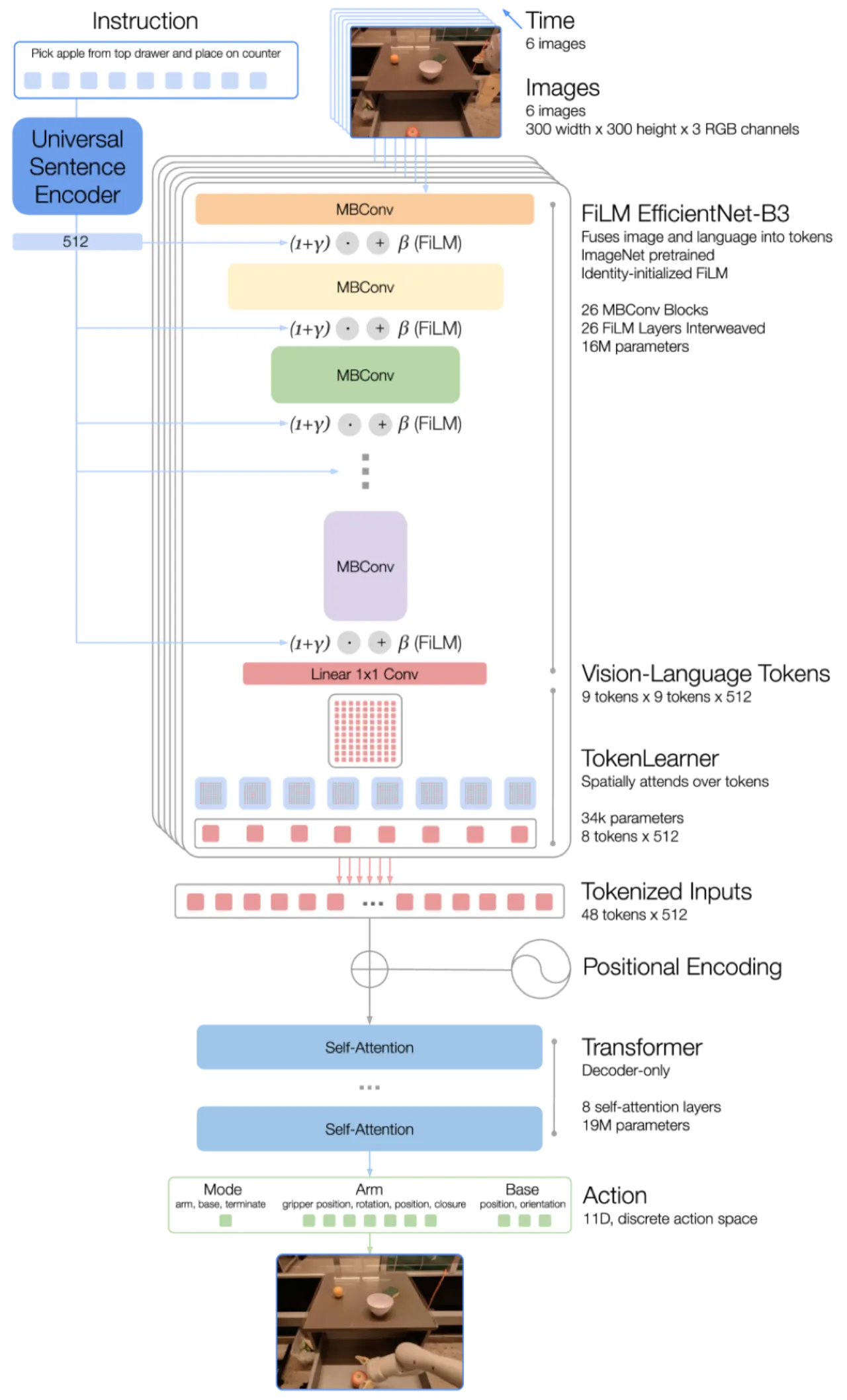
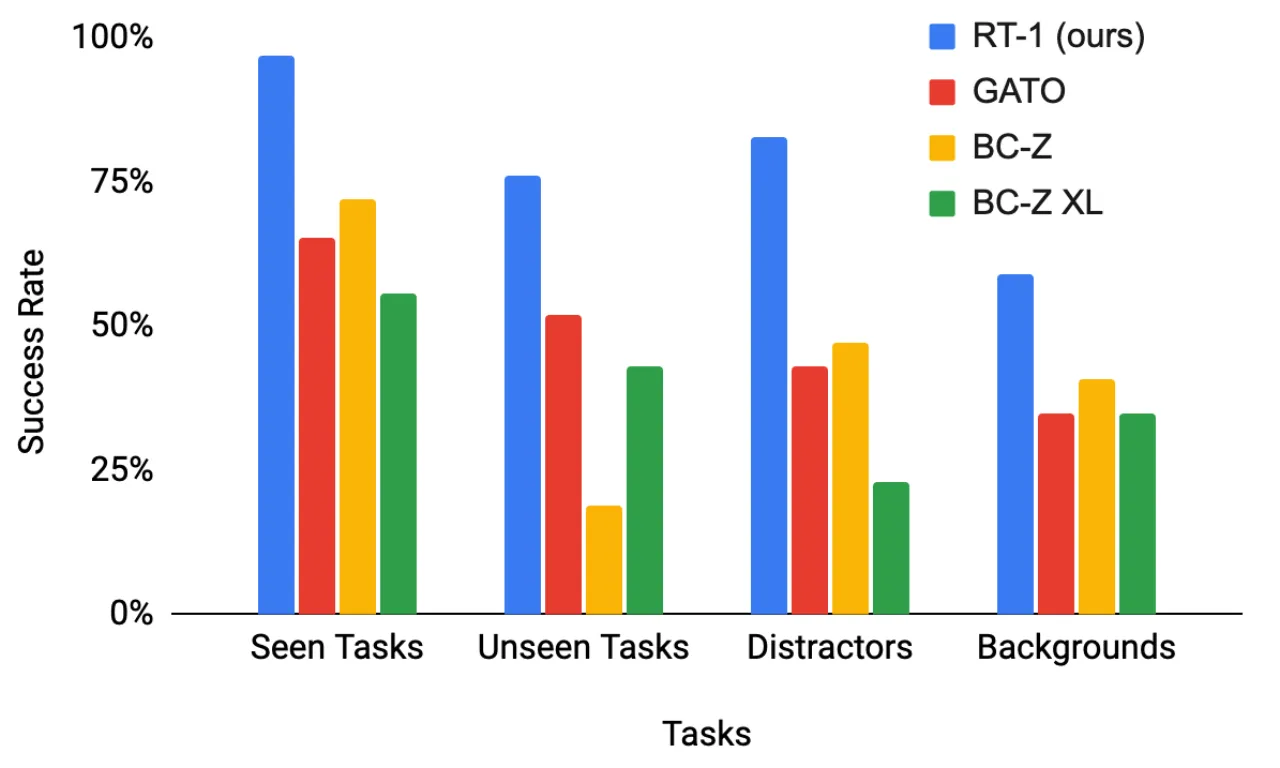
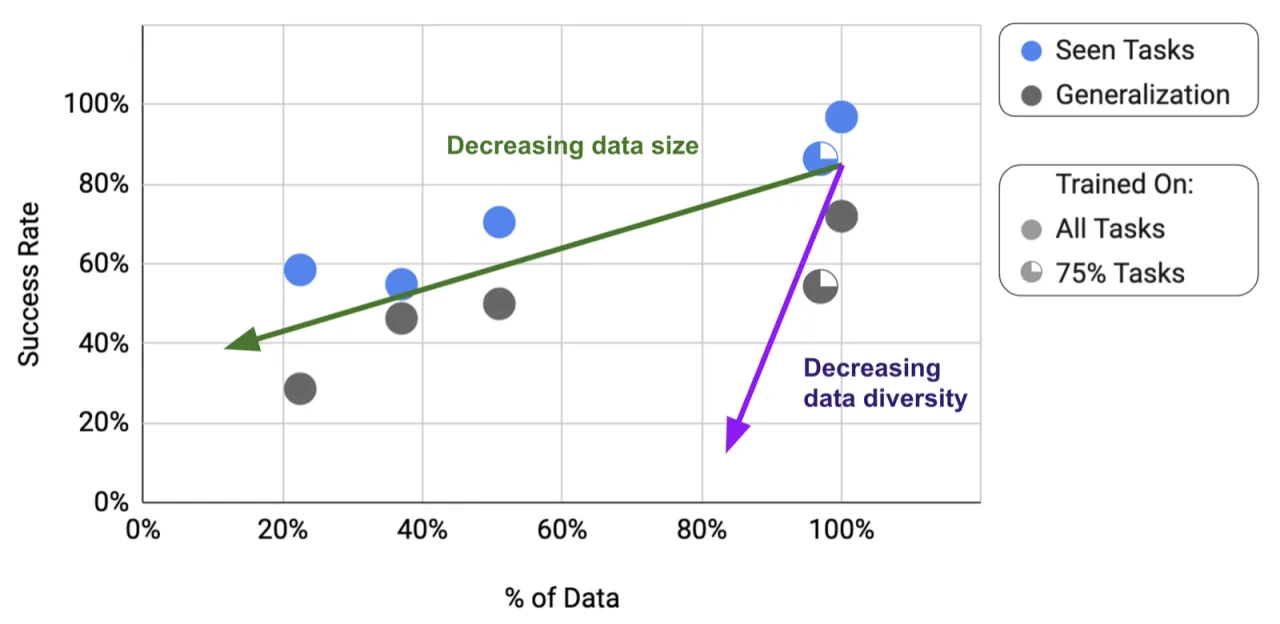
"Open-ended task-agnostic training, combined with high-capacity architectures" enables models to
effectively learn from varied robotic data — just as large language and vision models benefit from
scale and diversity.
多机器人混训:将 Everyday Robots 与 Kuka 数据混训后,bin-picking 任务成功率从 22%(单机器人训练)提升至 39%(提升 77%)。
04 局限性
Note: 以下局限性均由论文作者明确陈述(stated),非推断。
受限于 Imitation Learning 的上限
作者明确指出:"It may not be able to surpass the performance of the demonstrators."
模型本质上是在复刻人类演示者的行为,难以超越演示者的操作水平,也无法通过探索发现更优策略。
泛化仅限于已见概念的新组合
"Generalization to new instructions is limited to combinations of previously seen concepts" — 模型能够组合已学的技能与物体,但无法泛化到训练中从未出现过的全新动作或物体类别。
仅适用于非精细操控任务
RT-1 适用于 "a large but not very dexterous set of manipulation tasks",对精细化抓取(如插针、装配)等高灵巧度任务的适用性有限。
背景与环境鲁棒性有待提升
作者承认:"robustness to backgrounds and environments could be further improved by greatly increasing the environment diversity."
当前数据来自相对固定的厨房场景,对更广泛环境的适应性仍受限。