01 动机 Motivation
自监督预训练在视觉和语言领域带来了巨大突破,但在机器人学习领域尚未得到充分探索。机器人操作需要同时处理多模态感知(图像、本体感知)和动作序列,直接从零训练样本效率低、难以在任务间迁移。
"We ask: can we learn good sensorimotor representations from robotic trajectories? Our key hypothesis is that if the robot can predict the missing content it has acquired a good model of the physical world."

20K真实机器人轨迹(预训练数据集规模)
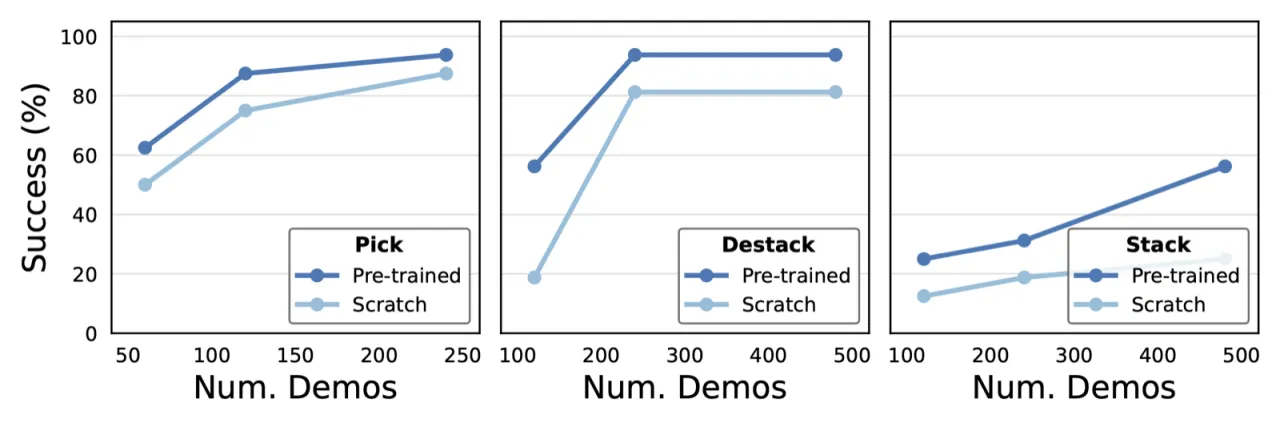
2×堆积任务成功率相对从零训练的提升
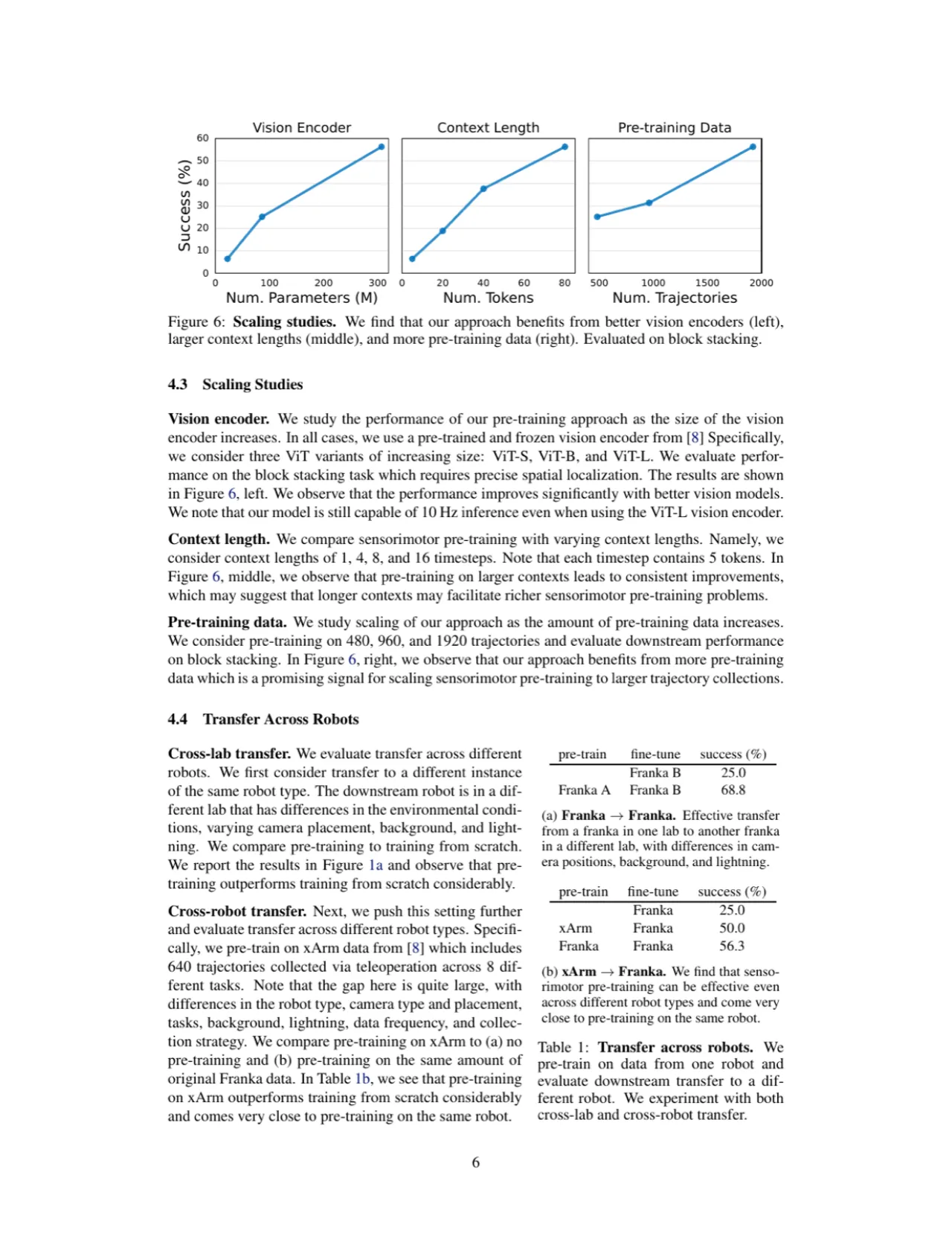
300M模型参数量(可在真实机器人 10 Hz 推理)
9 mo.数据采集历时月数
在机器人操作这一数据稀缺场景中,预训练能否帮助模型学到可迁移的物理世界模型?这是 RPT 试图回答的核心问题。与视觉预训练(ViT、MAE)不同,RPT 预训练的对象是跨模态、跨时间步的感知运动序列,旨在捕捉动作与感知之间的因果依赖关系。