01 Motivation
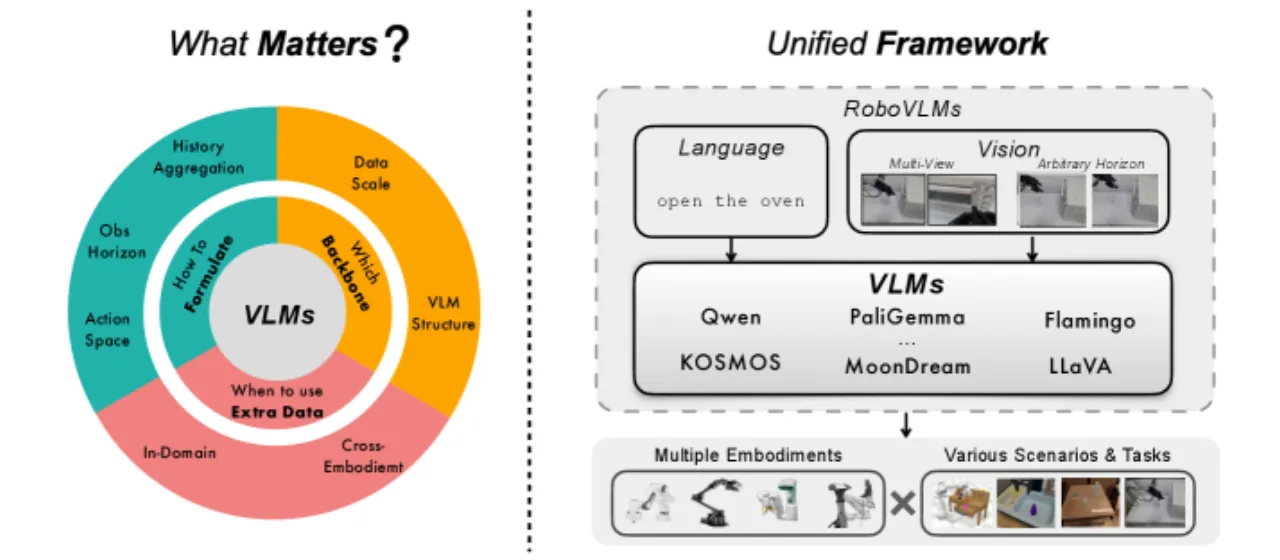
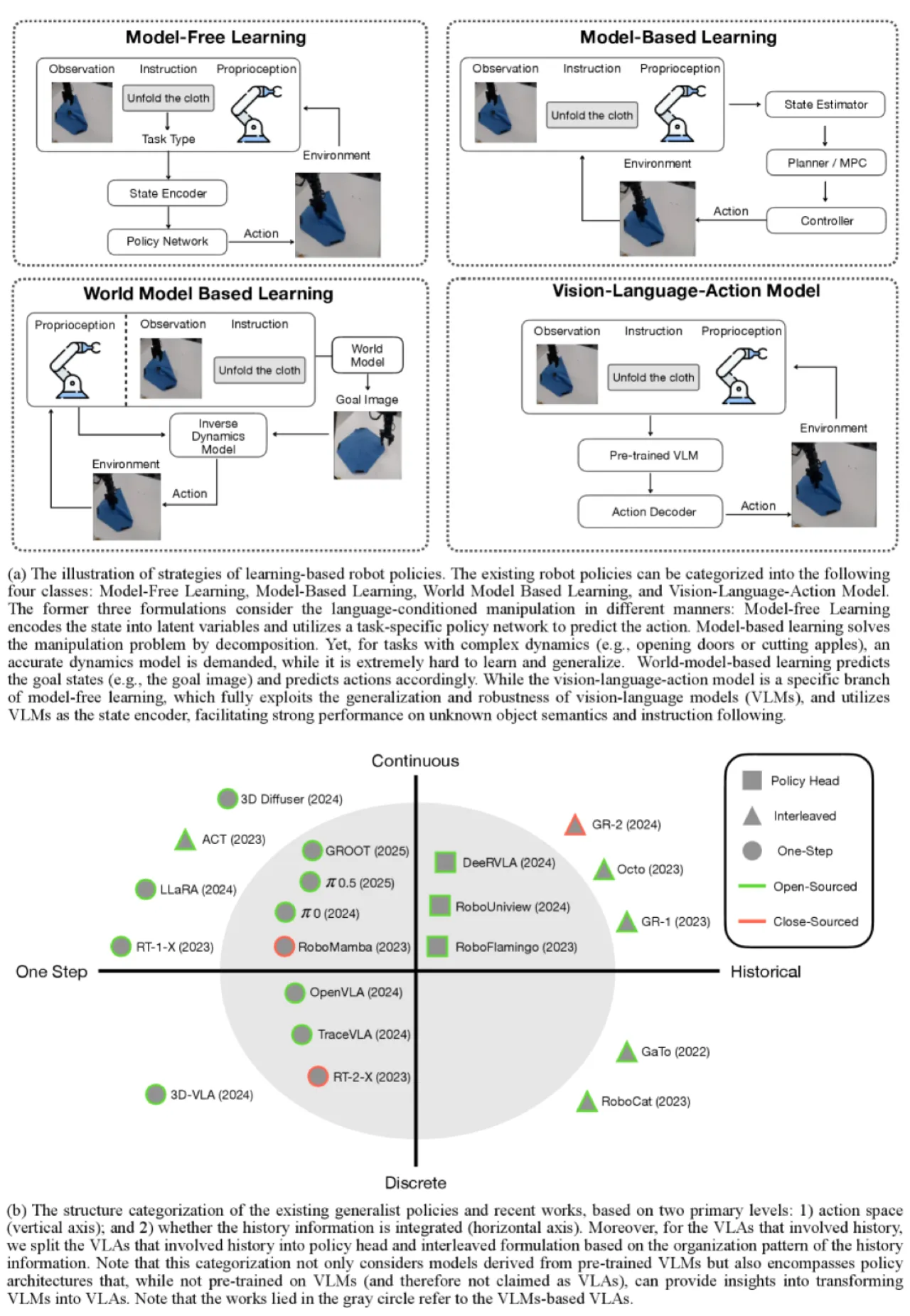
大型视觉语言模型(VLM)为通用机器人策略带来了新的可能,但如何将其转化为高效的 VLA 模型,业界缺乏系统性的实证研究——现有工作各自选择不同的 backbone、架构和数据策略,难以进行公平比较,也无法给出可推广的设计原则。
"We observe a significant gap between the performance of VLAs and expected performance of generalist robots, while the community lacks a systematic study covering all key design factors."
600+精心设计的对照实验
8+VLM backbone 横向对比
4策略架构类型
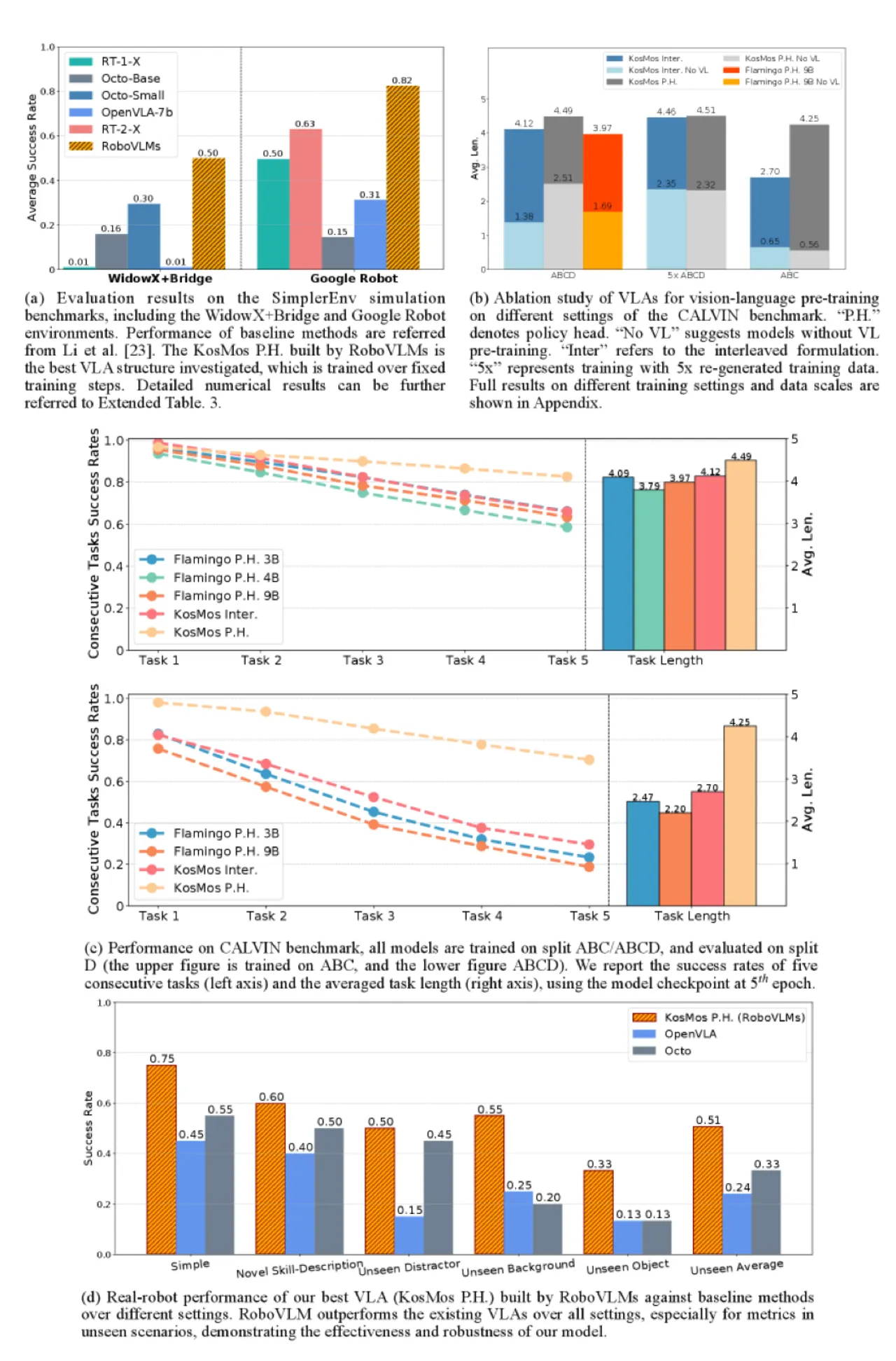
+30.3%5-task 连续执行绝对提升(vs. GR-1)
研究聚焦三个核心问题:
- 哪种 VLM backbone 最适合机器人策略?——预训练质量与规模的影响。
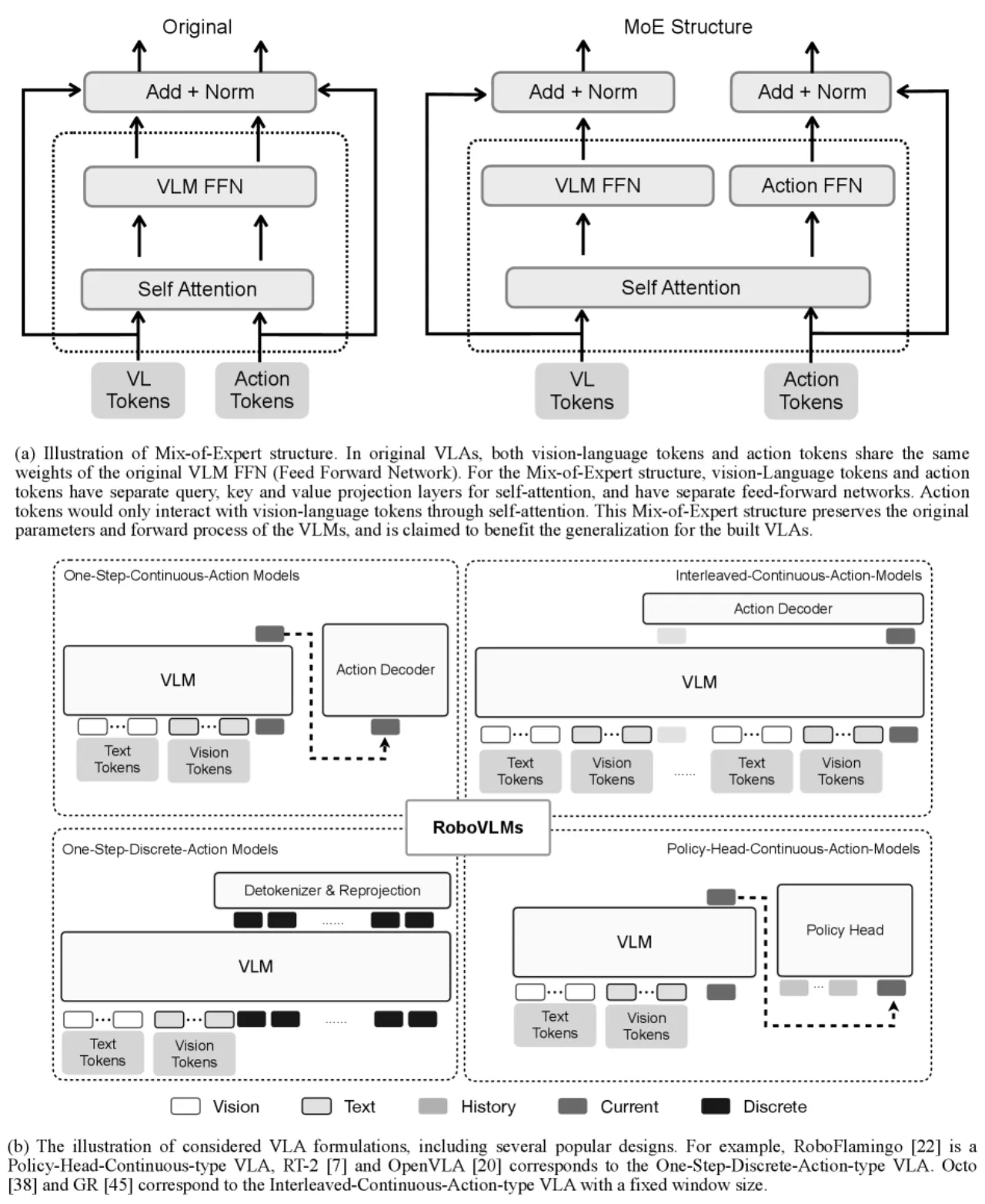
- 如何制定 VLA 架构?——one-step / interleaved / policy-head,离散 vs. 连续动作,训练目标(MSE+BCE、Flow Matching),以及 MoE 结构。
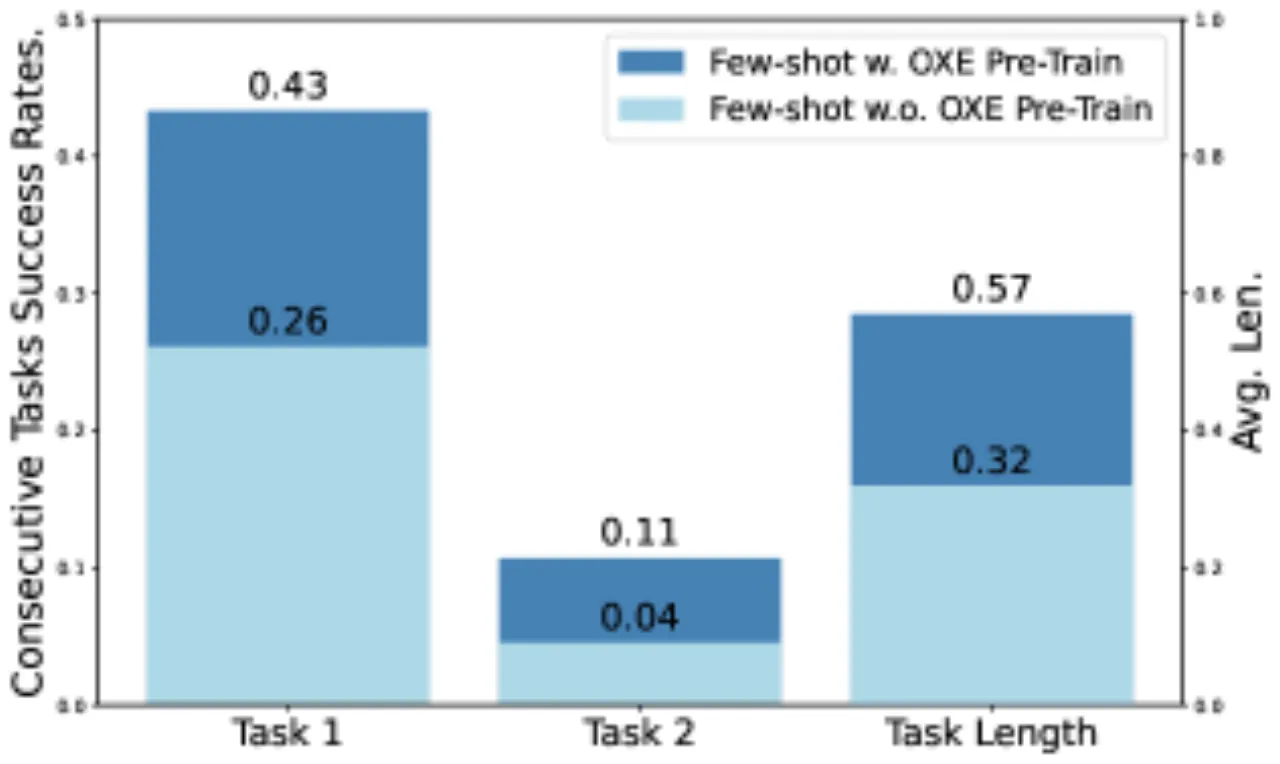
- 何时、如何利用跨机体数据?——co-training 与 post-training 的区别。