01 动机
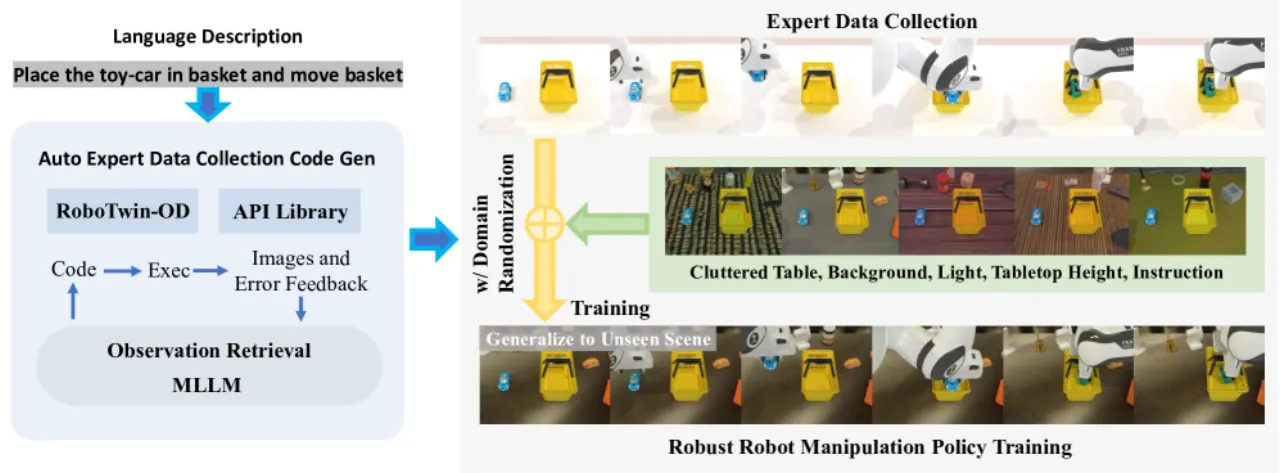
双臂机器人操作需要海量高质量轨迹数据,而现有合成数据管线在自动质量控制、场景多样性和跨机器人平台泛化三方面存在根本缺陷。
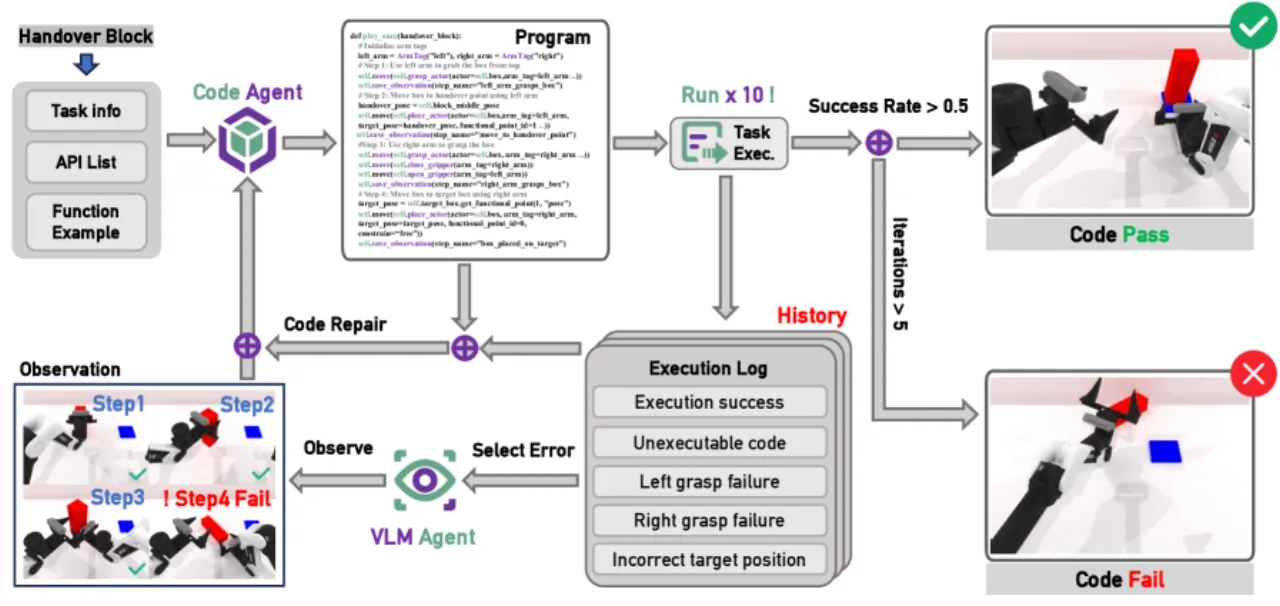
"lack of automated quality control: without an expert-level validation loop, many generated trajectories include execution failures or suboptimal grasps; domain randomization is often superficial, yielding overly clean and homogeneous scenes; overlooking cross-embodiment variation: different bimanual platforms can differ substantially in their kinematic capabilities."
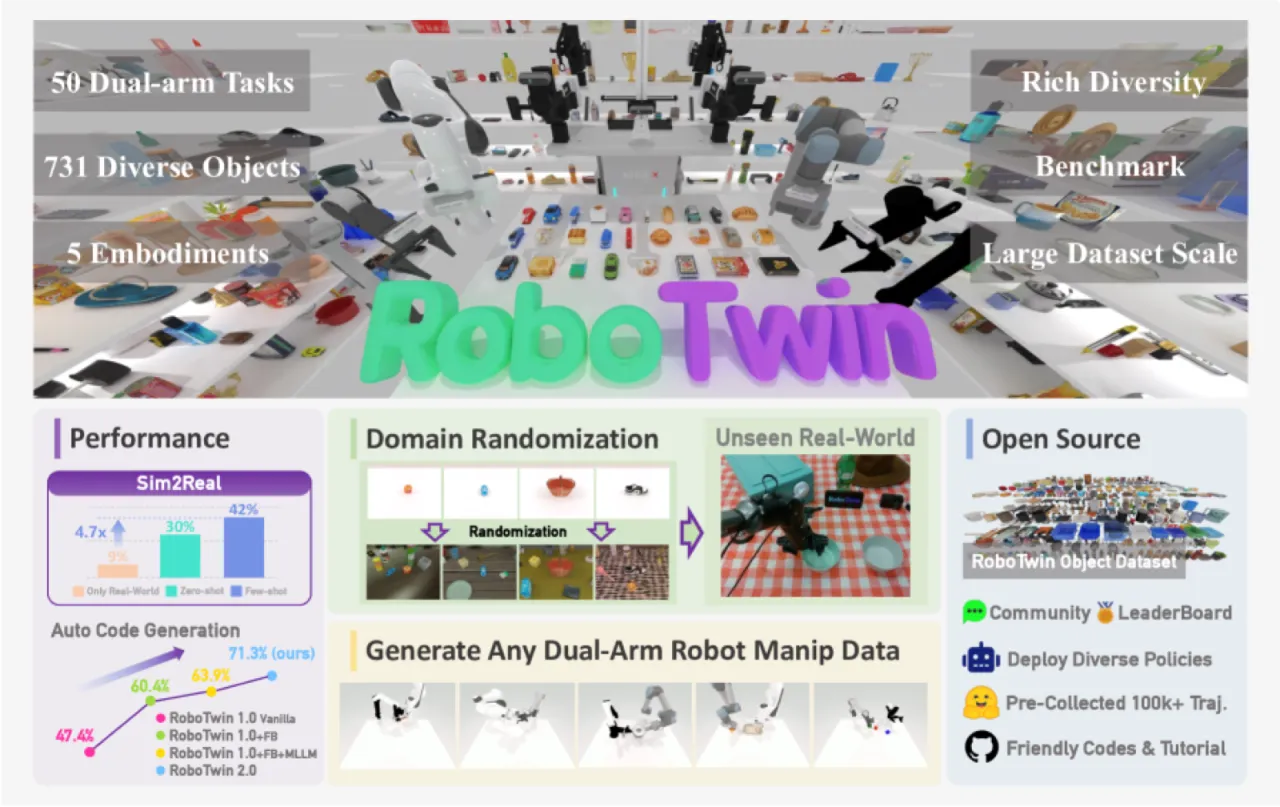
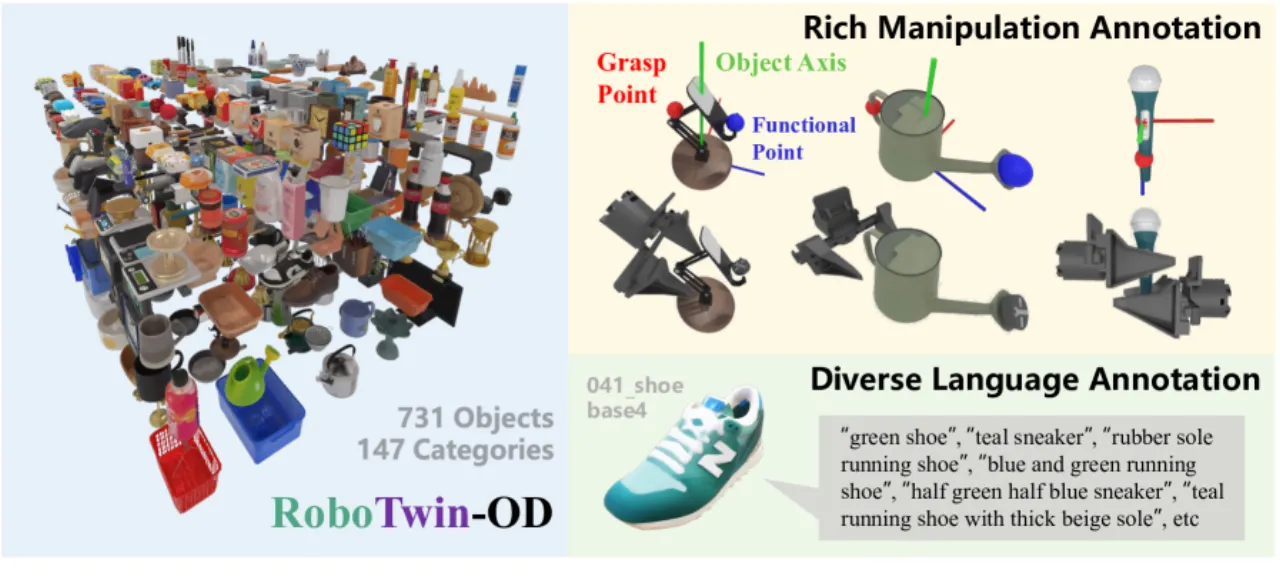
731操作物体数量(147 类别)
50双臂操作任务基准
5支持的机器人平台
367%10 条真实样本相对增益(vs. 纯真实数据基线)
真实数据采集成本高昂且难以规模化,而直接使用合成数据训练的策略往往因 sim-to-real 差距而失败。RoboTwin 2.0 通过三个相互协同的组件来解决上述问题:自动化专家数据生成、全面的域随机化,以及机器人本体感知自适应,从而生成 "high-quality, diverse, realistic, and interaction-rich datasets for bimanual manipulation"。