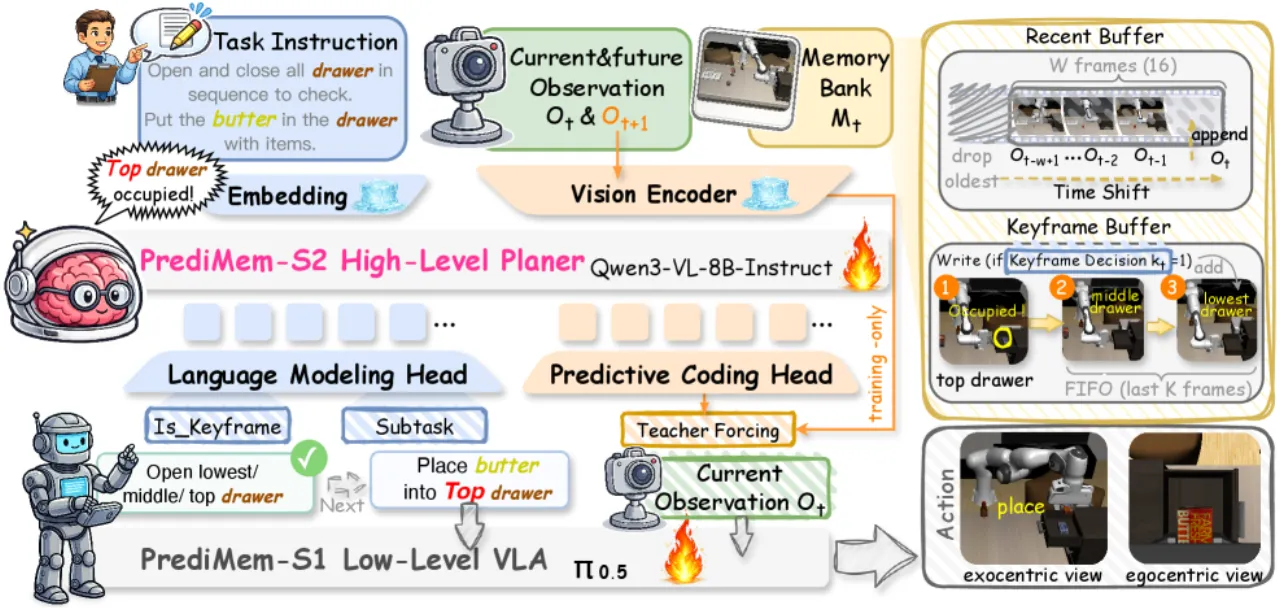
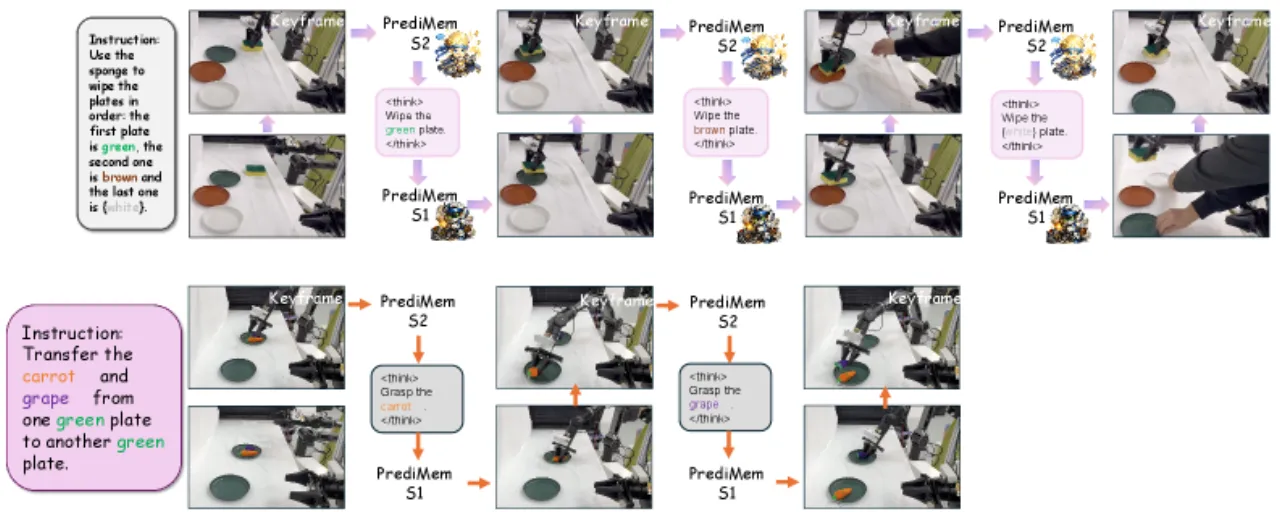
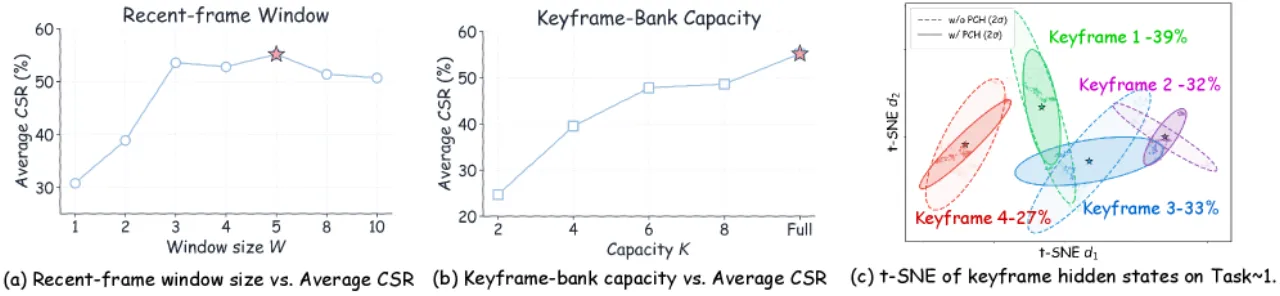
01 动机 / Motivation
现有机器人操作基准大多关注单步或短序列动作,对跨时间步记忆能力的评估严重不足。当物体被遮挡、状态发生改变、或任务依赖此前操作结果时,reactive 策略(仅依赖当前观测)将系统性失败——而这恰恰是真实操作场景中的常态。
"Existing robotic memory benchmarks suffer from...lack of multimodal annotations...limited task coverage...restricted to simulation."

26仿真任务
1000+平均轨迹步数
68.9%子任务依赖记忆
8领先于所有对比基准测试的评估维度

与已有基准的对比
论文在 14 个已有机器人基准上做了系统对比,RoboMemArena 是唯一同时满足以下全部 8 项标准的基准:长时域(>1000 步平均)、自动指令生成、原子子目标、可扩展生成、自主抓取(AnyGrasp)、状态 oracle、原生 keyframe、真实世界评估。