01 Motivation
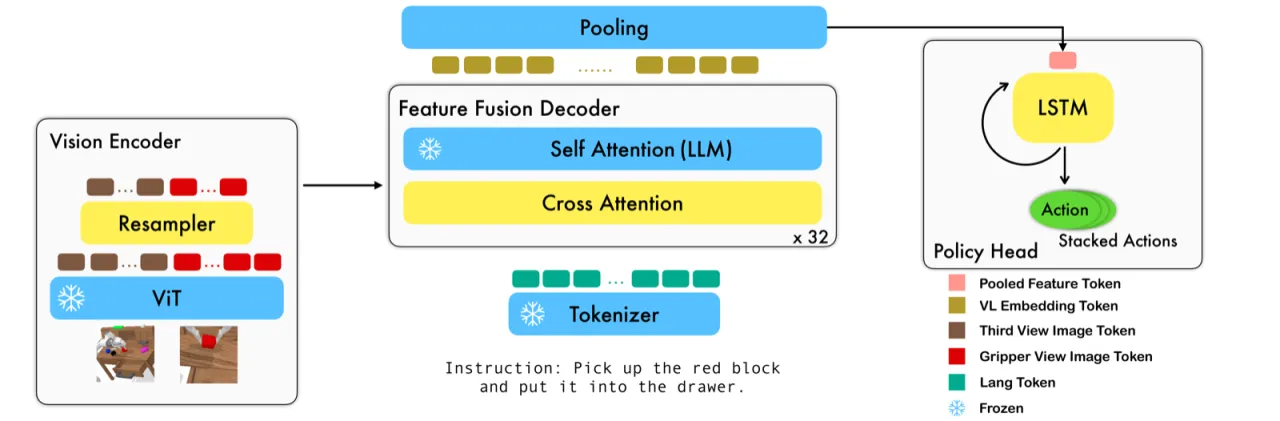
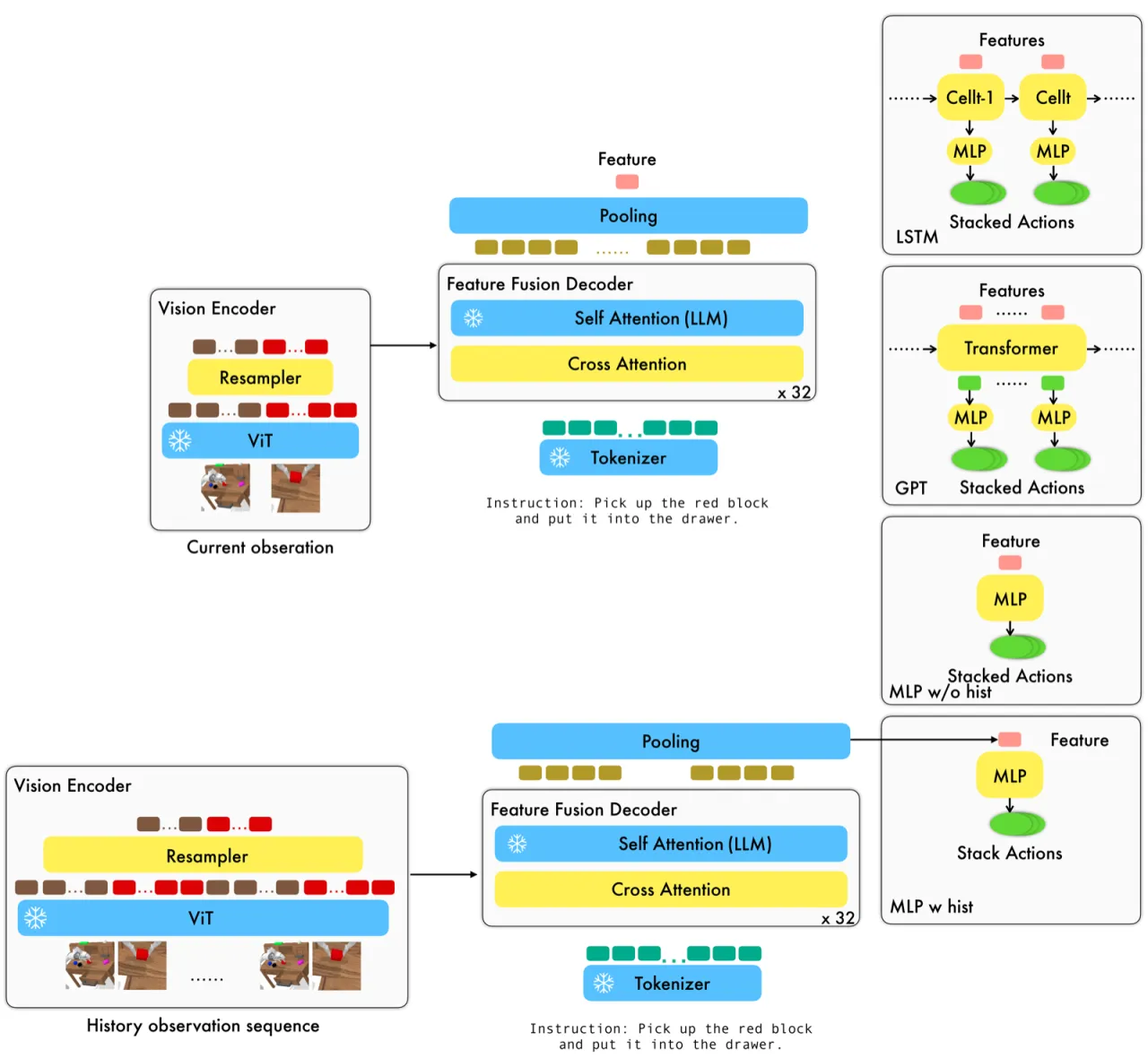
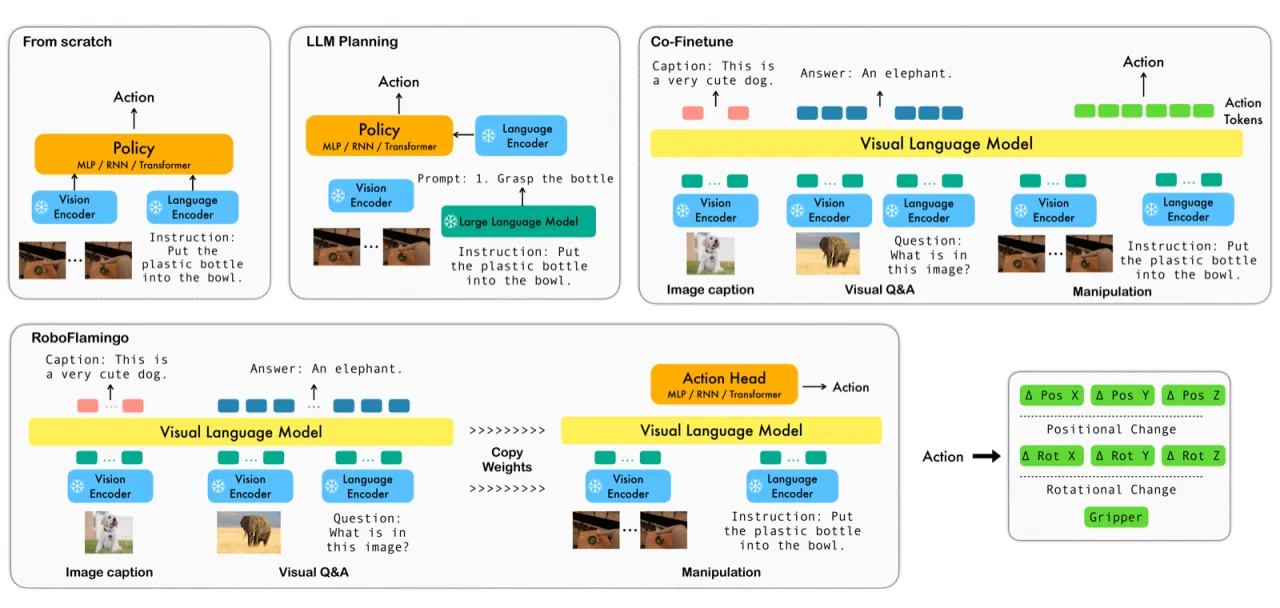
视觉-语言大模型(VLM)已展现出强大的多模态理解能力,但将其直接用于机器人低层控制仍面临三大挑战:① VLM 在静态图像-文本对上预训练,难以处理视频时序观测;② VLM 输出语言 token,而机器人需要连续动作信号;③ 现有高性能方案(如 RT-2)依赖私有模型与海量数据,无法被普通研究者复用。本文提出 RoboFlamingo,探索一种低成本、开源、可单卡运行的 VLM 机器人操作方案。
"We seek a straightforward way of making use of existing vision-language models (VLMs) with simple fine-tuning on robotics data. ... RoboFlamingo can be an effective and competitive alternative to adapt VLMs to robot control."
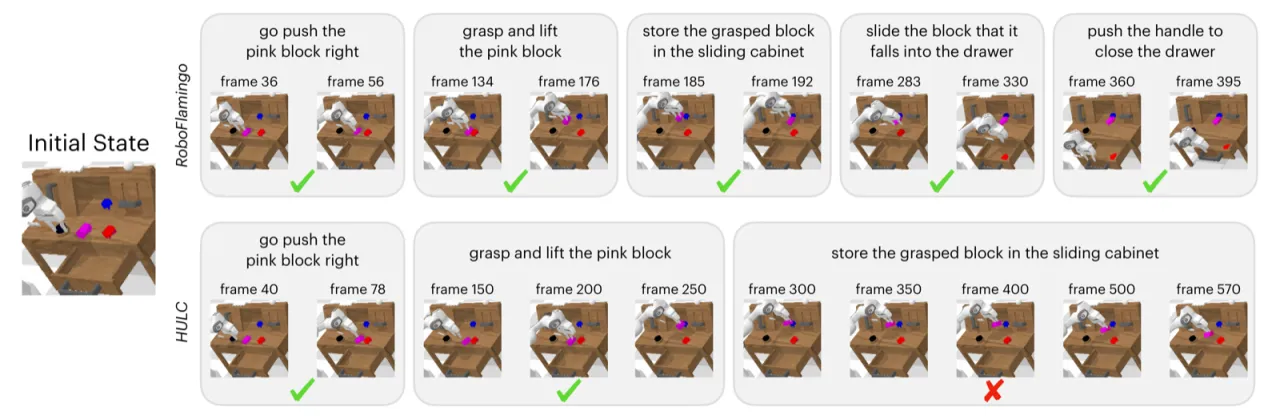
4.09Avg Len(ABCD→D,RoboFlamingo)
3.06Avg Len(ABCD→D,HULC 最优基线)
2×相对先前 SOTA 的性能提升
单张 GPU可完成训练与评估