采用"用户本地推理"范式的核心代价是:
"we have no means to check whether the model actually run by the user matches the user's claim."
恶意用户可替换模型或引入人工辅助(human-in-the-loop cheating),系统当前无技术手段防范。
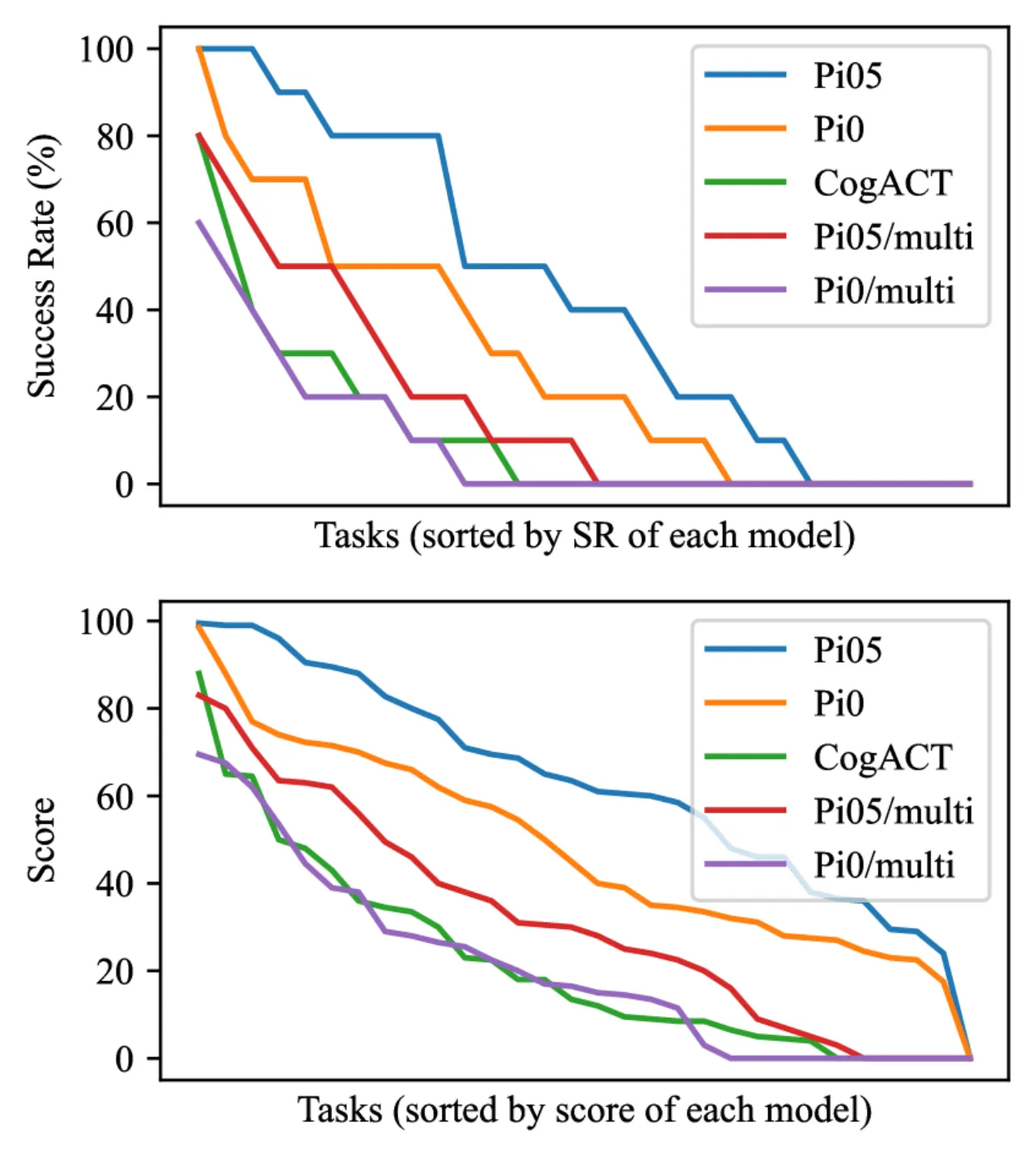
测试集过拟合风险(Test-set Overfitting)
固定的参考图像场景存在被针对性过拟合的风险。论文指出
"There is a chance that the model submissions 'overfit' to the particular reference test cases",
但实验中目前未观测到此现象。
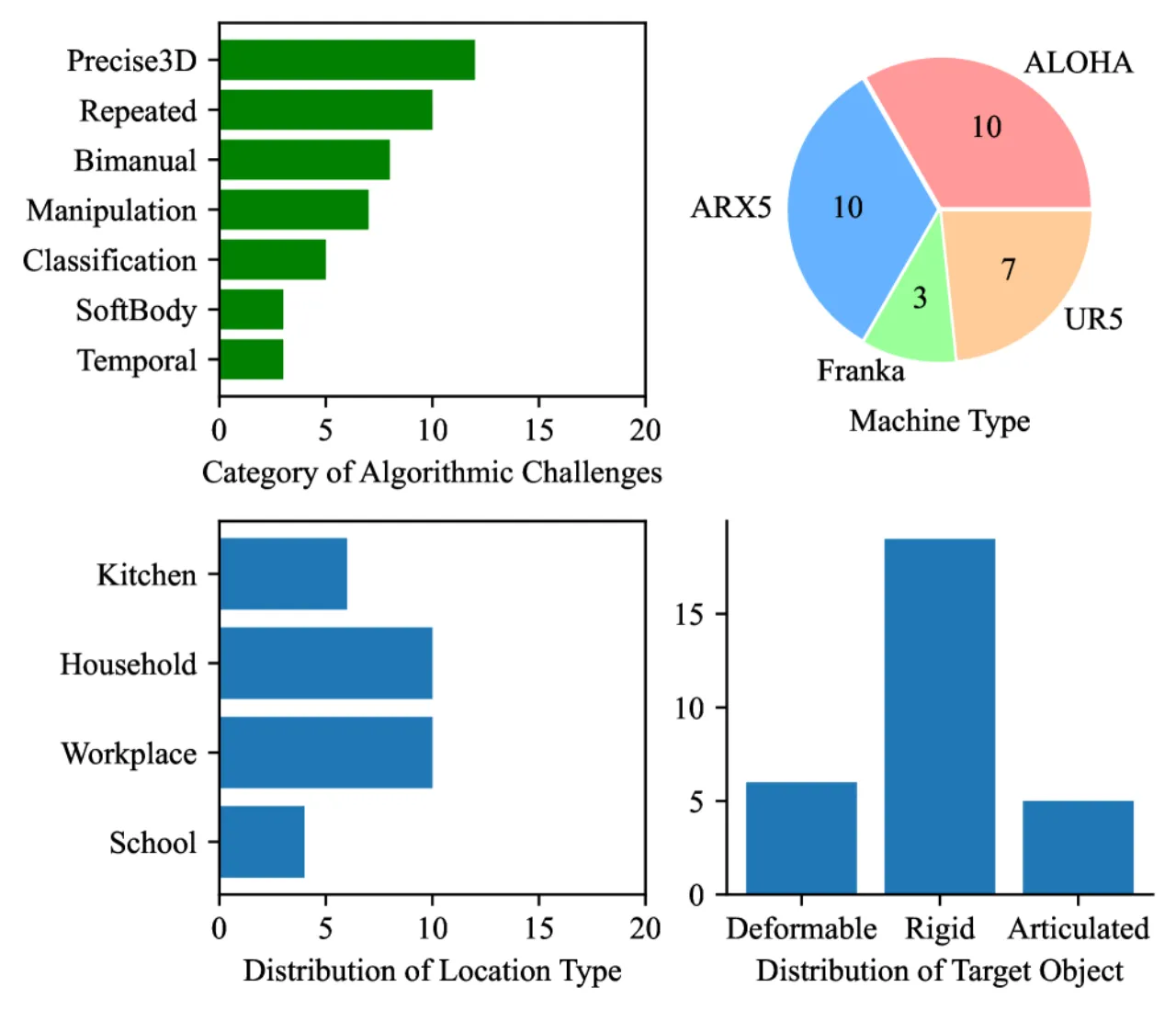
当前 VLA 均为单帧模型(Single-frame Models)
所有被测 VLA 均为 single-frame 推理,无法处理时序依赖任务
("identical images may be received on different stages"),
这直接导致 temporal dependence 类任务平均成功率仅 5%,是最大能力短板之一。
低分辨率输入限制精细操作(Low Resolution: 224×224)
被测模型均工作在 224×224 低分辨率下,对精细三维定位任务(precise 3D localization)
造成显著影响,该类任务平均 SR 仅 12%。