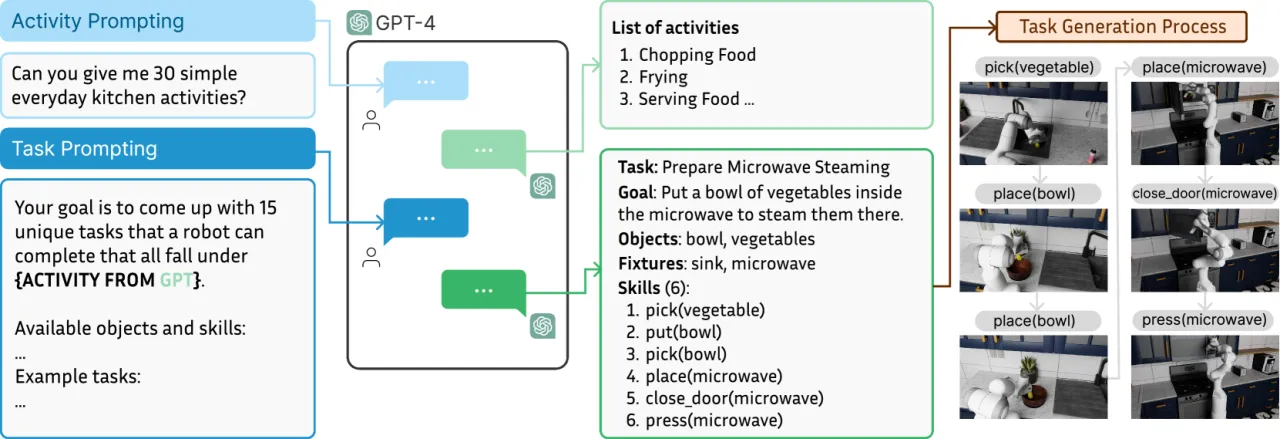
01 动机
训练通用机器人的最大瓶颈在于大规模、多样化数据集的匮乏。现实采集成本极高,而现有仿真环境场景单一、资产稀少,难以覆盖日常家务的复杂性。RoboCasa 旨在通过构建写实感强的大规模厨房仿真,结合 AI 生成工具(text-to-3D、text-to-image、LLM 任务生成),为机器人学习提供可扩展的合成数据源。
"We present RoboCasa, a large-scale simulation framework for training generalist robots in everyday environments. We focus on the kitchen as a setting that offers diverse challenges, including object diversity, spatial reasoning, and long-horizon task execution."
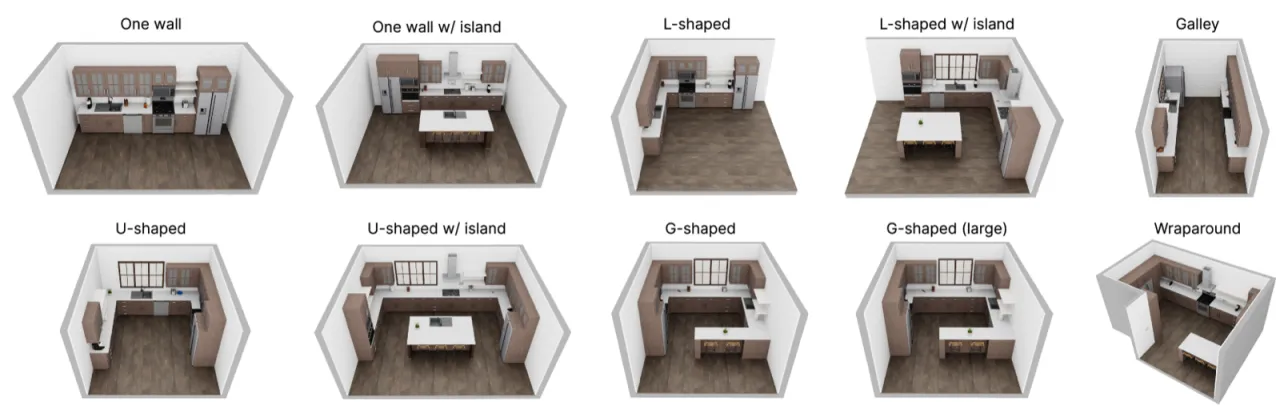
120厨房场景配置 (10 平面图 × 12 风格)
2,509高质量 3D 物体资产,涵盖 153 类别
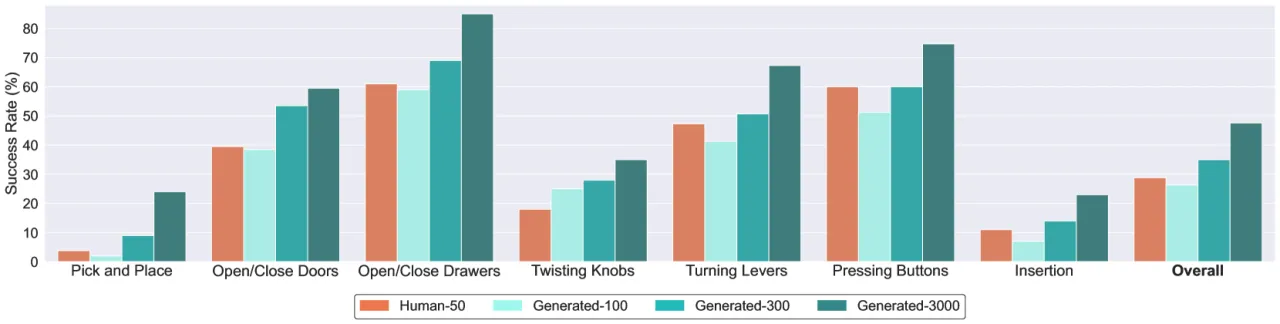
100任务总数 (25 原子 + 75 复合)
100K+合成轨迹数据量