cs.RO · arXiv 2506.18123
RoboArena
Distributed Real-World Evaluation of Generalist Robot Policies
Pranav Atreya, Karl Pertsch, Tony Lee, Moo Jin Kim, Arhan Jain, Artur Kuramshin, Clemens Eppner, Cyrus Neary, Edward Hu, Fabio Ramos, Jonathan Tremblay, Kanav Arora, Kirsty Ellis, Luca Macesanu, Marcel Torne Villasevil, Matthew Leonard, Meedeum Cho, Ozgur Aslan, Shivin Dass, Jie Wang, William Reger, Xingfang Yuan, Xuning Yang, Abhishek Gupta, Dinesh Jayaraman, Glen Berseth, Kostas Daniilidis, Roberto Martin-Martin, Youngwoon Lee, Percy Liang, Chelsea Finn, Sergey Levine(七所机构联合)
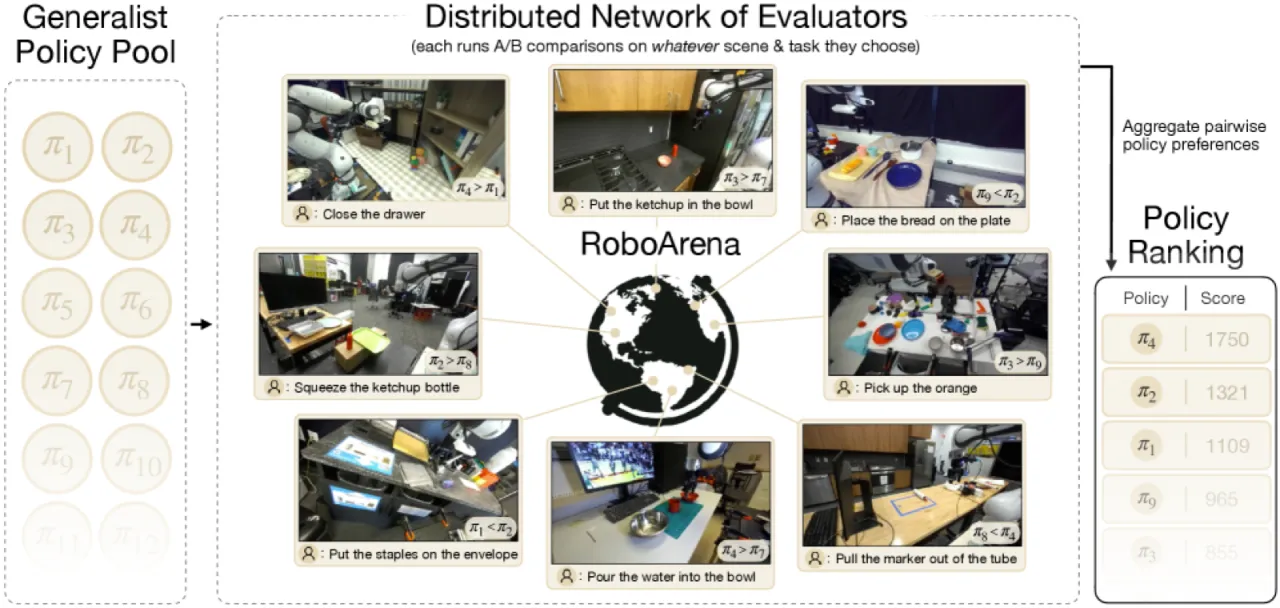
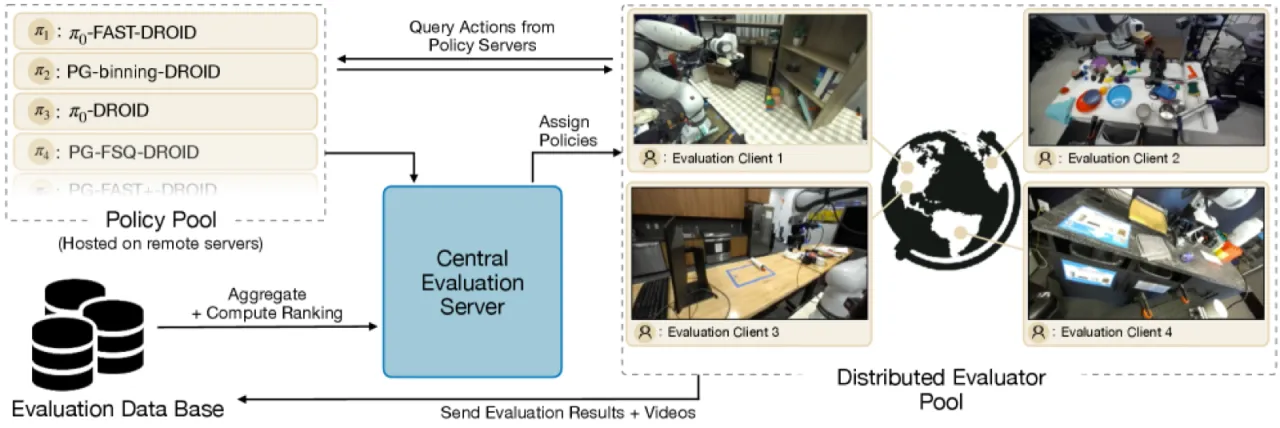
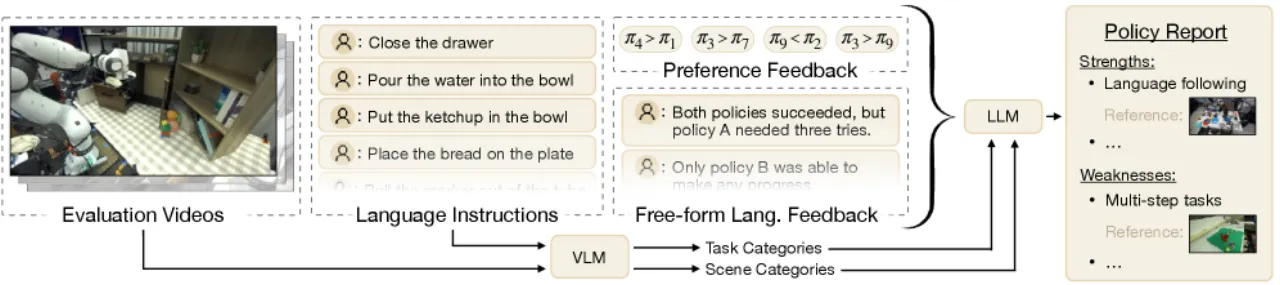
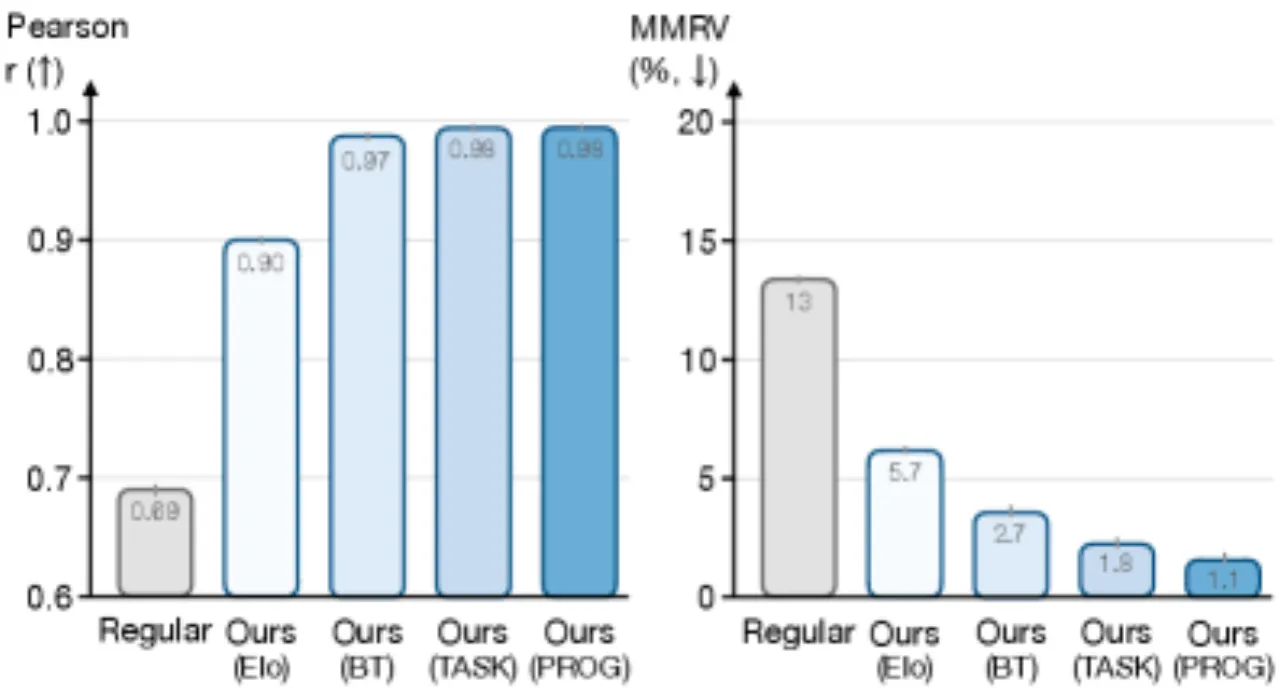
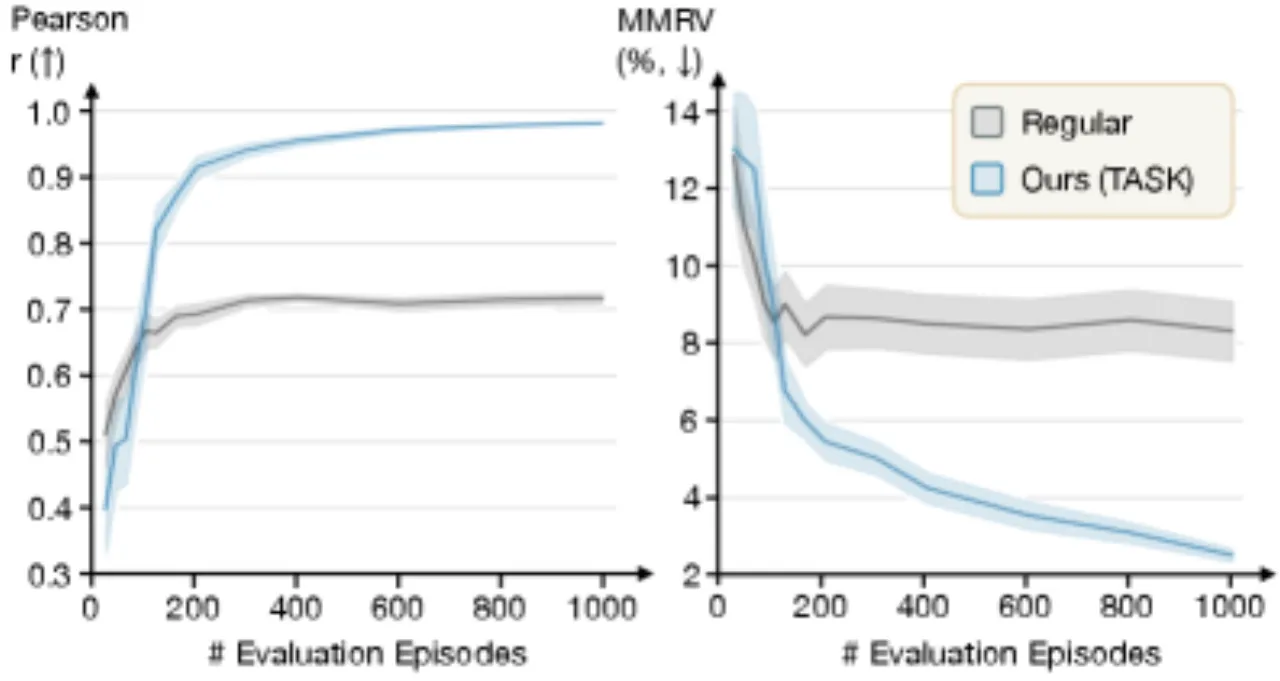
RoboArena 借鉴语言模型评测中的 Chatbot Arena 思路,通过分布式、双盲的成对策略比较,在真实机器人上对通用策略进行可扩展评估。跨越七个机构超过 600 次成对真实机器人评测,RoboArena 的排名结果比传统集中式评测方法更准确地反映策略的真实能力。
机器人评测
generalist robot policy
pairwise evaluation
Bradley-Terry model
distributed benchmark
策略排名
real-world robotics
crowdsourced evaluation