01 动机
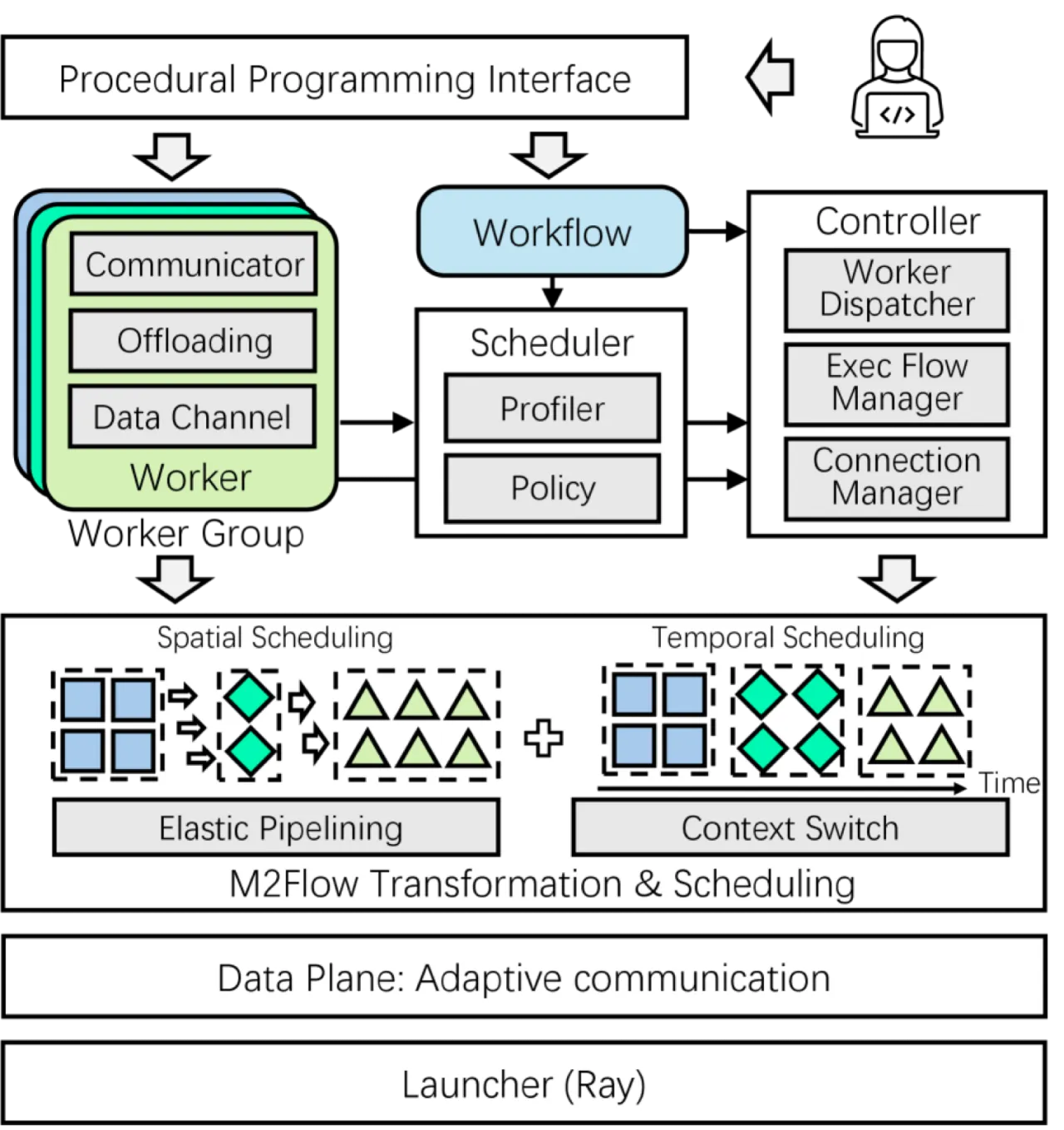
现代 RL 工作流高度异构且动态变化,现有训练系统受制于单一执行模式,GPU 利用率低、训练效率差。RLinf 发现系统灵活性不足是高效 RL 训练的核心障碍。
"The major roadblock to efficient RL training lies in system flexibility. Single execution mode of existing RL training systems fails to capture this diversity, leading to suboptimal efficiency."
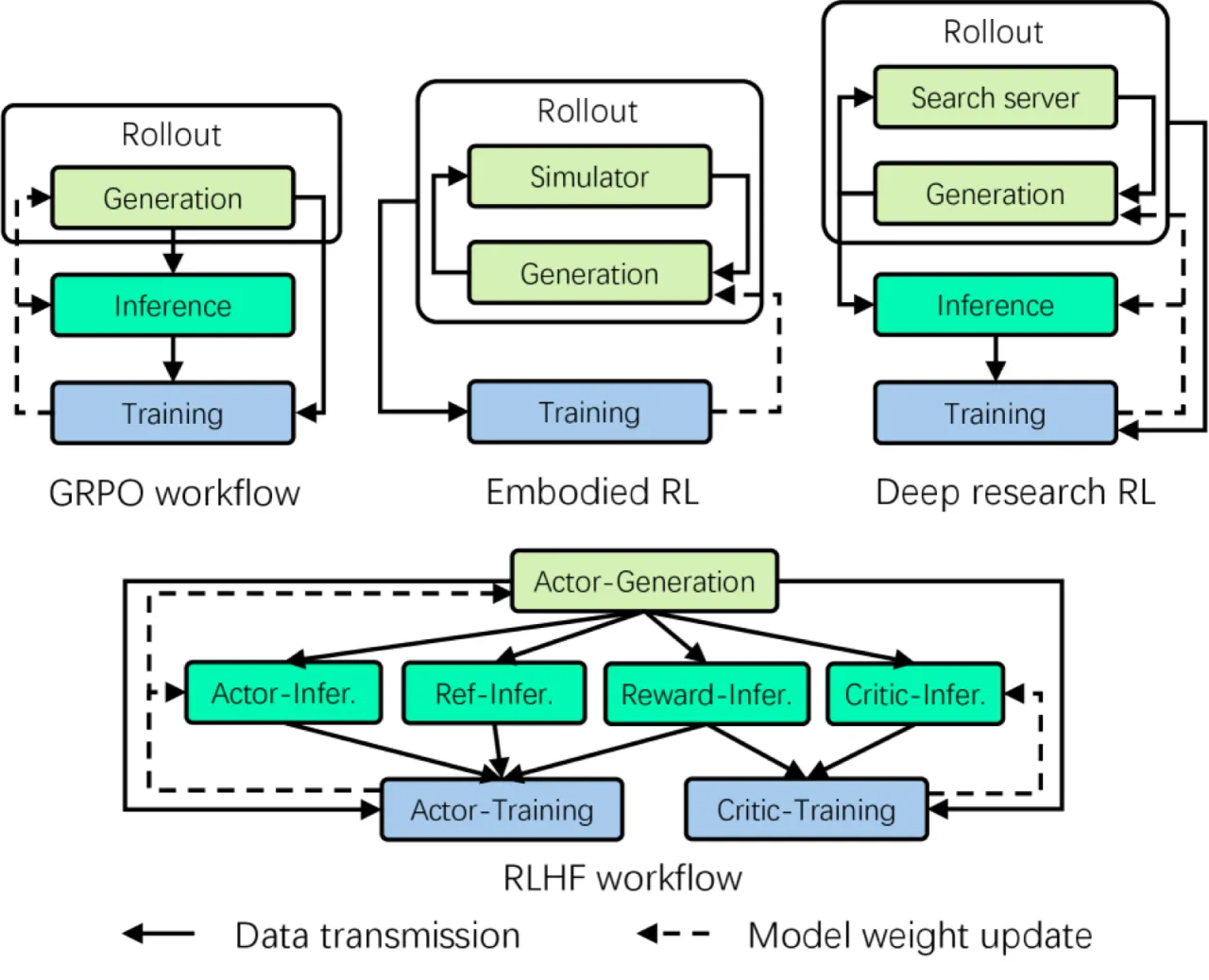
论文归纳了现有系统面临的三大核心瓶颈:
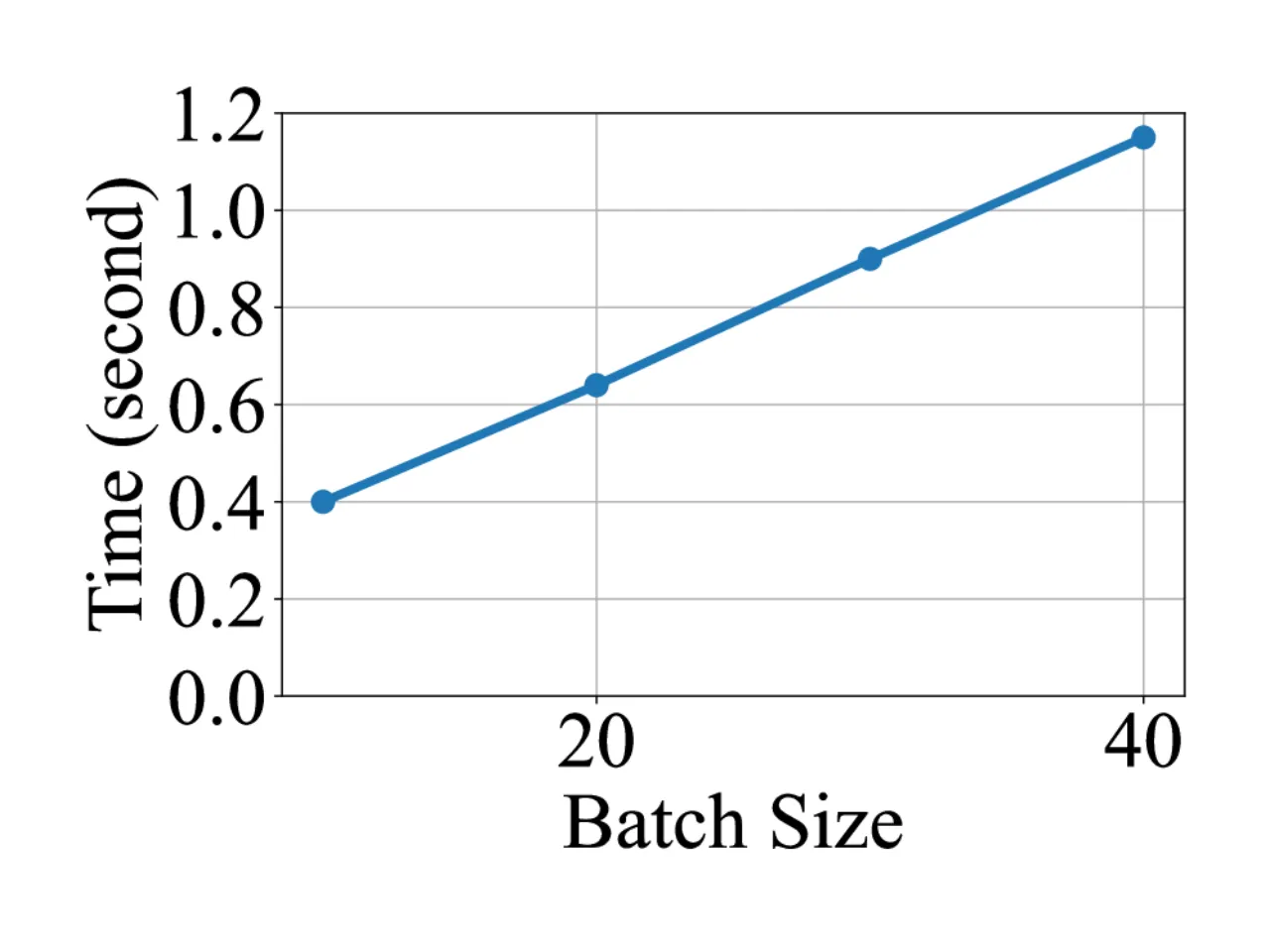
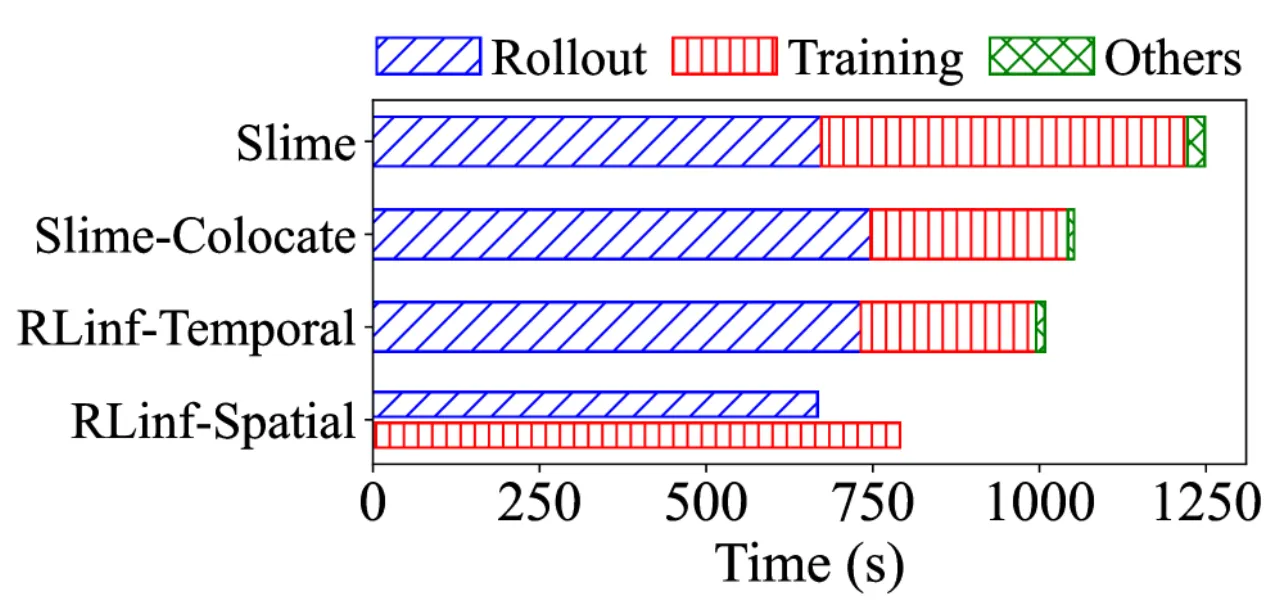
- 动态 rollout 长尾问题:生成阶段中响应长度高度可变,少量慢查询会阻塞整个 phase,使大量 GPU 处于空闲状态(long-tail problem)。
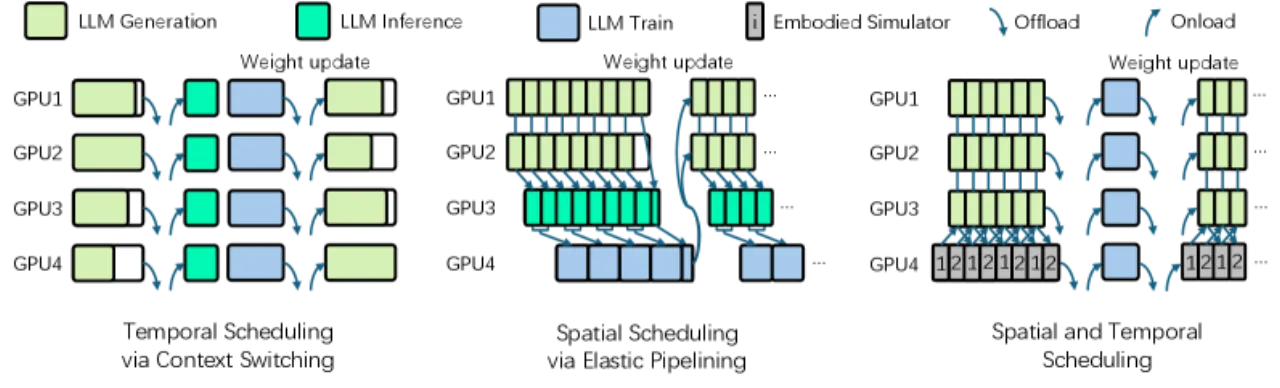
- 执行模式不兼容:Collocated(顺序共享设备)和 disaggregated(流水线并行)两种模式各有局限,没有单一模式对所有 RL 组件都最优。
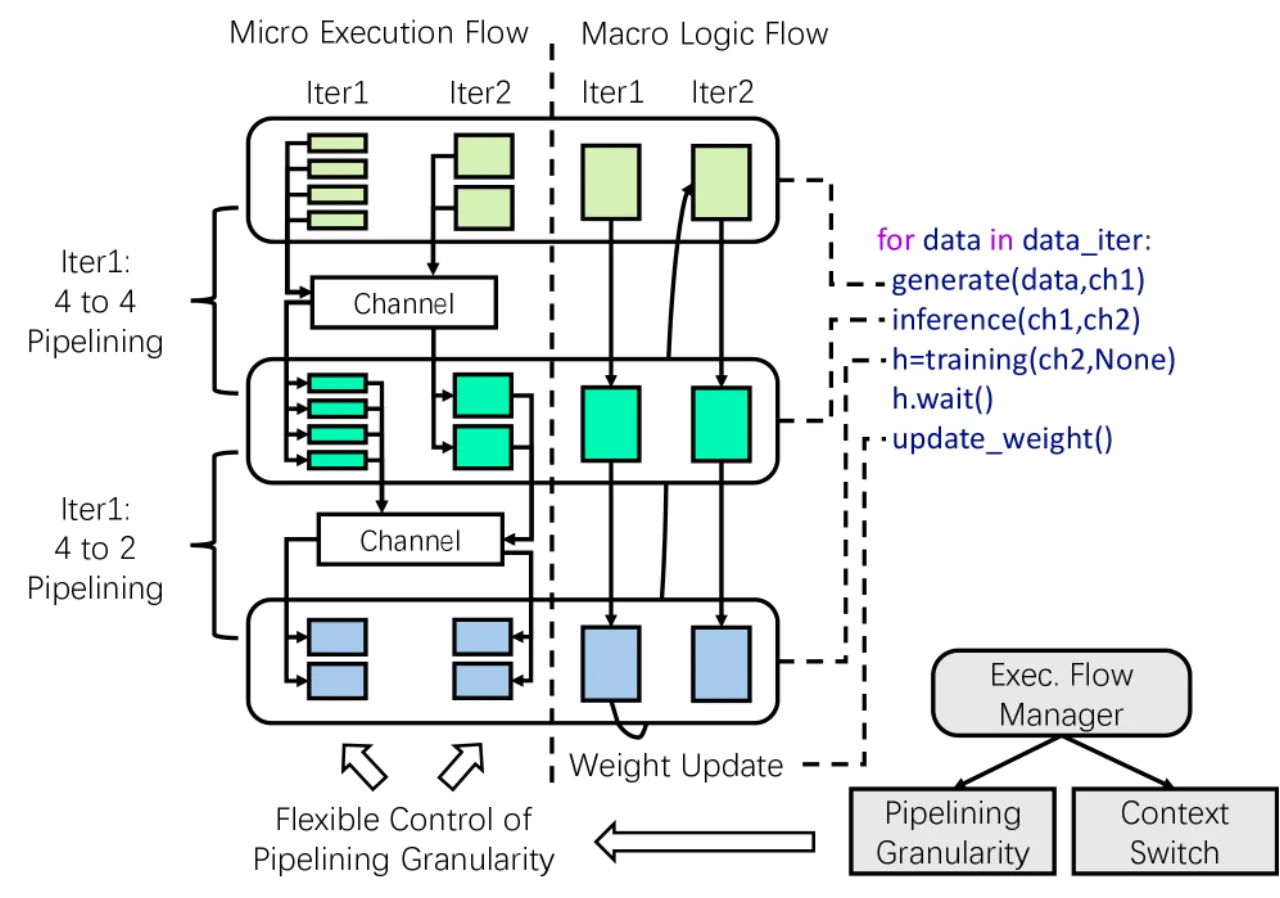
- 编排复杂度高:"Finding the most suitable orchestration for a given RL workflow is challenging, as the characteristics are diverse and the dependencies are complex."
1.07×–2.43×端到端训练吞吐量加速(vs. SOTA 系统)
81.93%ManiSkill 具身任务平均成功率(vs. 79.15% RL4VLA)
97.83%LIBERO 平均成功率(vs. 34.33% OpenVLA-OFT baseline)
<6 秒在 1024 GPU 集群上的调度策略搜索开销