01 动机
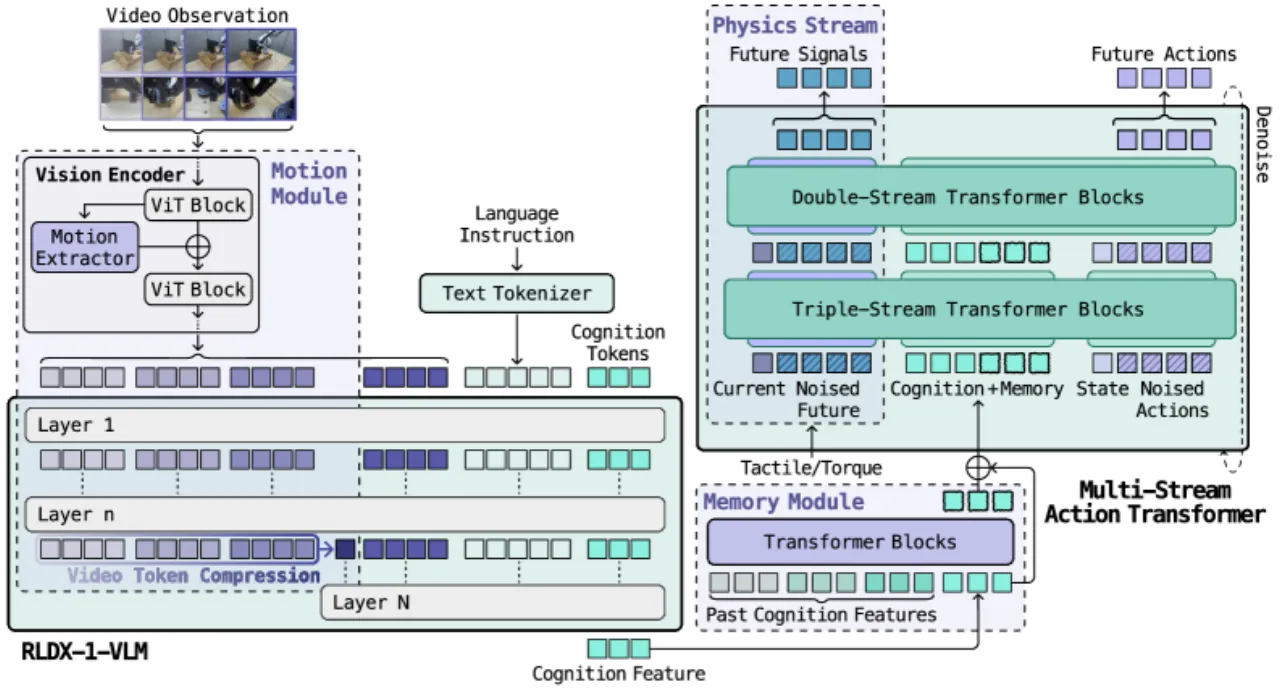
VLA 模型通过继承预训练 Vision-Language Model 的通用理解与语言条件泛化能力,在机器人操作领域取得了显著进步——但这种"通用智能"并不等于"灵巧操作所需的全部能力"。在动态环境(如传送带上的移动物体)、需要记住历史交互状态的任务、以及依赖触觉/力矩反馈的接触丰富场景中,现有 VLA 普遍失效。
"While Vision-Language-Action models (VLAs) have shown remarkable progress toward human-like generalist robotic policies through the versatile intelligence … they still struggle with complex real-world tasks requiring broader functional capabilities (e.g. motion awareness, long-term memory, and physical sensing)."

97.8%LIBERO 平均成功率
(超越 GR00T N1.6 的 96.7%)
(超越 GR00T N1.6 的 96.7%)
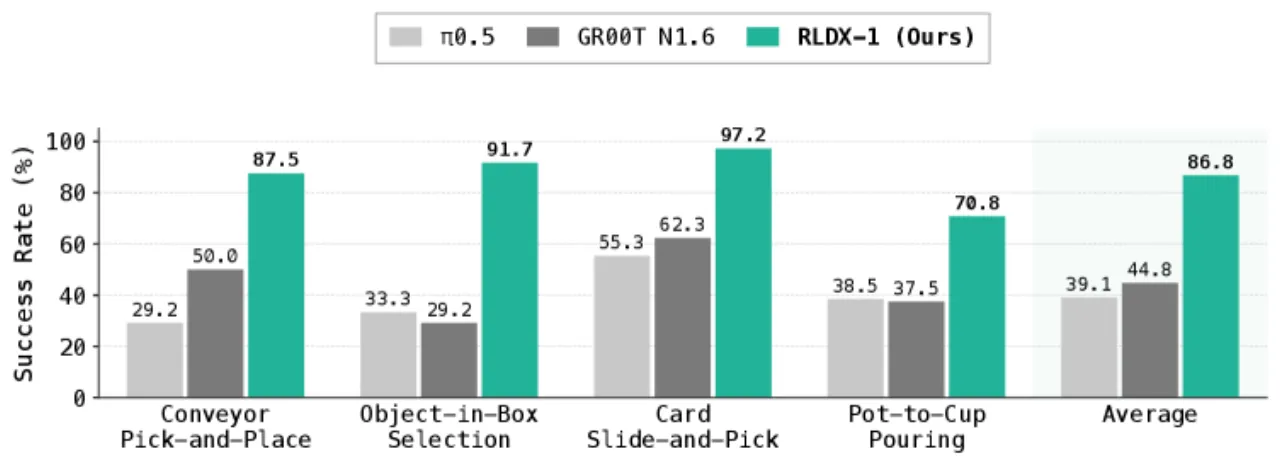
91.7%ALLEX 长时记忆任务
(Object-in-Box Selection)
(Object-in-Box Selection)
87.5%ALLEX 运动感知任务
(Conveyor Pick-and-Place)
(Conveyor Pick-and-Place)
1.63×推理加速比
(71.2ms → 43.7ms)
(71.2ms → 43.7ms)