01 动机 Motivation
机器人操作算法的研究面临严峻的评估碎片化问题:现有基准要么任务数量有限(如 RoboTurk 仅 3 个任务)、 要么缺乏视觉观测、要么演示数据极难获取。研究者往往各自定义私有评估集,导致方法间横向对比几乎不可能。 与此同时,小样本学习、多任务学习等新兴范式也缺乏专门的机器人操作测试平台。
"We present RLBench, an ambitious large-scale benchmark and learning environment designed to facilitate research in a number of areas, including: reinforcement learning, imitation learning, multi-task learning, geometric computer vision, and in particular, few-shot learning. We believe it is important to find the potential and limits of these methods in a controlled, reproducible environment."

100完全独特的手工设计任务
∞运动规划器生成的专家演示
5支持的传感器模态(RGB/深度/分割等)
1st机器人领域首个大规模小样本挑战
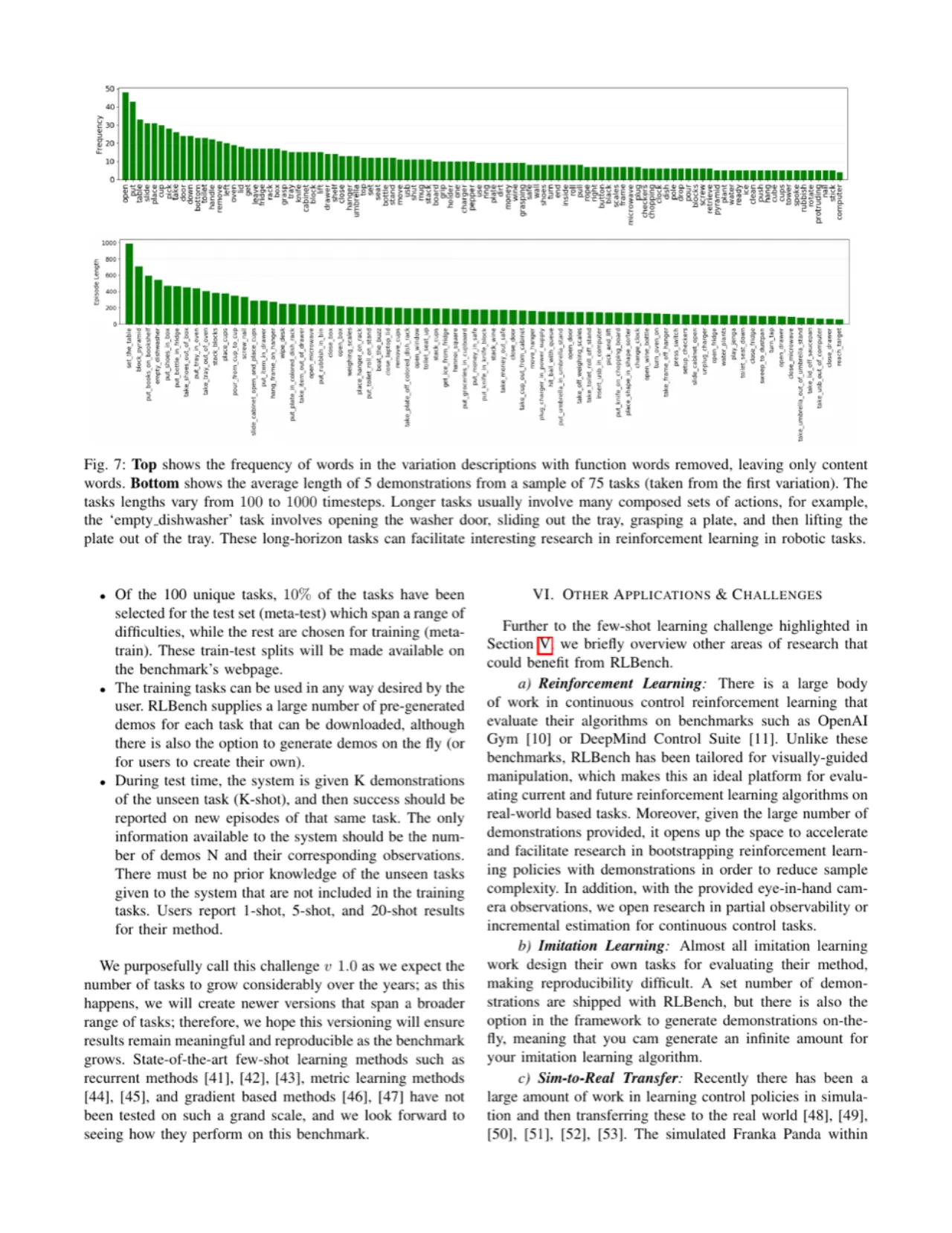
现有基准的不足
- 任务多样性不足:OpenAI Gym、DeepMind Control Suite 等主流基准任务数量极少, 以连续控制为主,缺乏视觉驱动的操作场景。
- 演示获取困难:Similate [29](Sim)等混合真实方案需要动作捕捉校准,耗时耗力; 纯仿真方案如 RoboTurk 仅有 3 个任务且需要众包操作员。
- 缺乏小样本评估:没有现成平台能在机器人场景下公平测试 N-way K-shot 元学习方法。
- 评估标准不统一:各研究组自定义评估集,跨论文横向比较几乎不可能。