01 动机
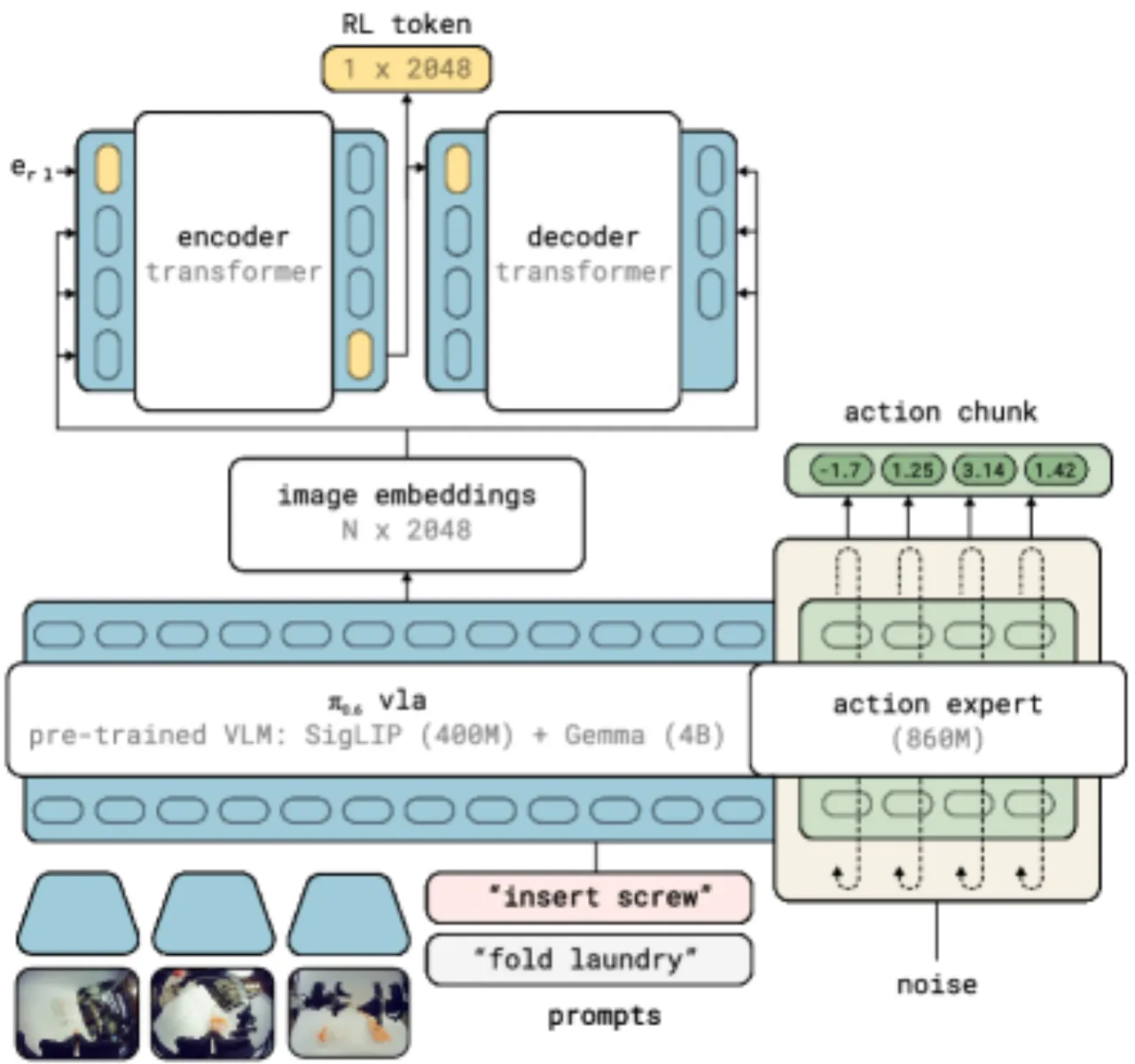
VLA 模型(如 π₀、OpenVLA 等)在多样化操作任务上展现出强大的泛化能力, 但面对需要毫米级精度的关键阶段(如螺钉安装、以太网插头插拔),其成功率往往不尽如人意。 强化学习(RL)理论上可以弥补这一差距,但真机 RL 面临严峻挑战:
"every episode takes time, every failure consumes effort and wear, and meaningful adaptation often has to happen within a few hours of practice."
现有方案的两难困境:
- 直接微调整个 VLA:参数量巨大,样本效率极低,难以在少量真机数据上收敛。
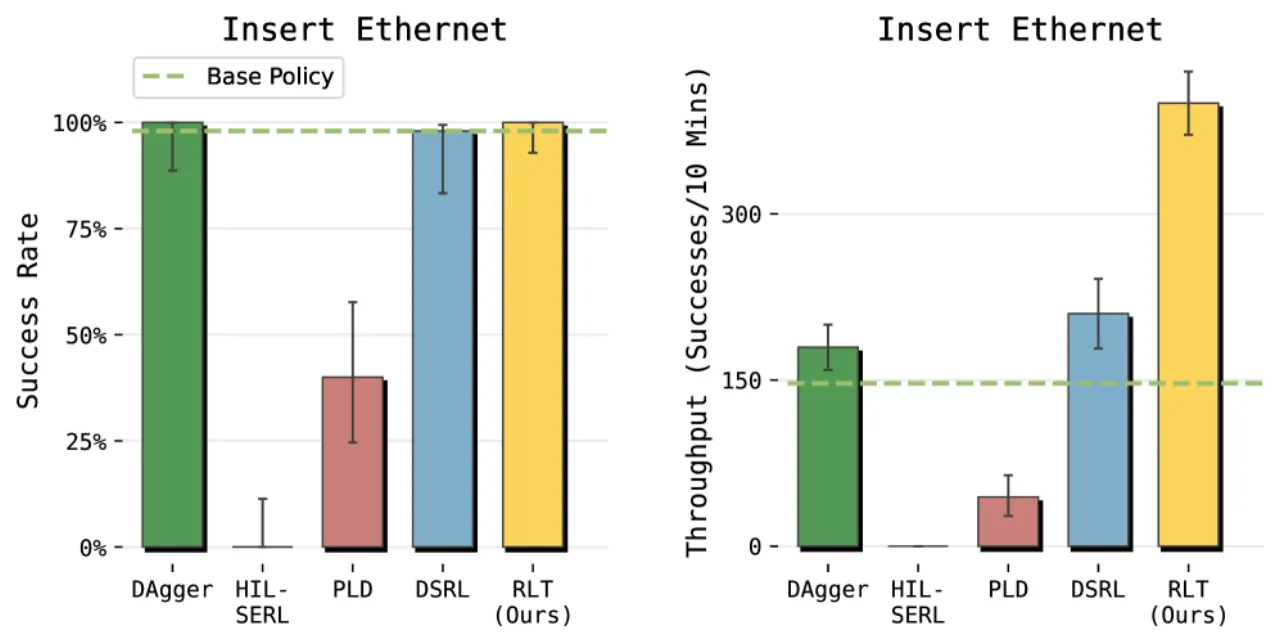
- 从头训练小型 actor-critic(如 HIL-SERL):丢弃了 VLA 预训练的感知与策略知识,探索空间大。
- 残差/蒸馏方案(如 PLD、DSRL):作用于单步动作或扩散噪声空间,未能充分利用 VLA 的完整表征。
核心问题:如何在保留 VLA 预训练知识的同时,让轻量级 RL 在极少量真机数据上高效工作?

3×关键阶段最大速度提升倍数
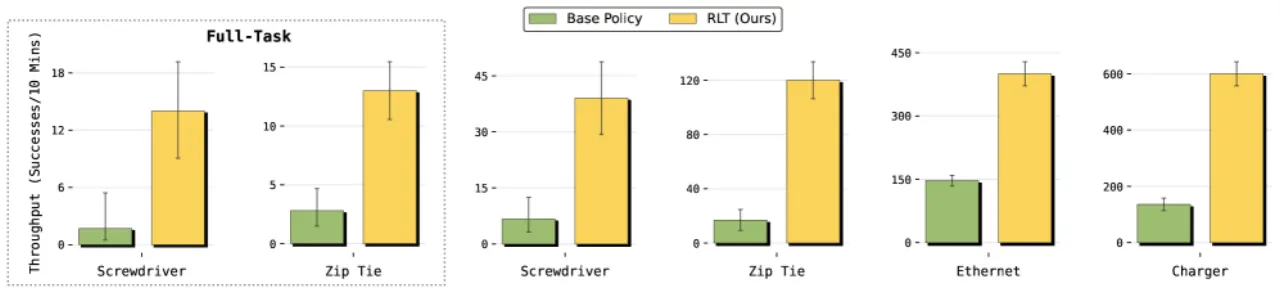
+45%螺钉任务成功率提升(20%→65%)
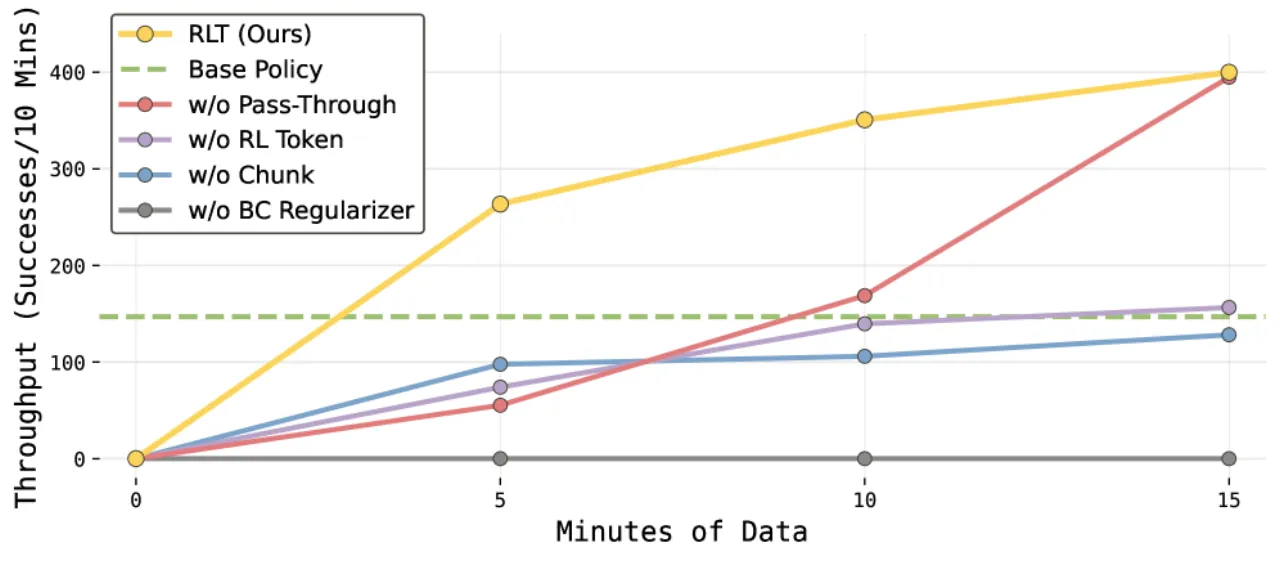
≤5h每任务真机 RL 训练数据量
4真实机器人操作任务