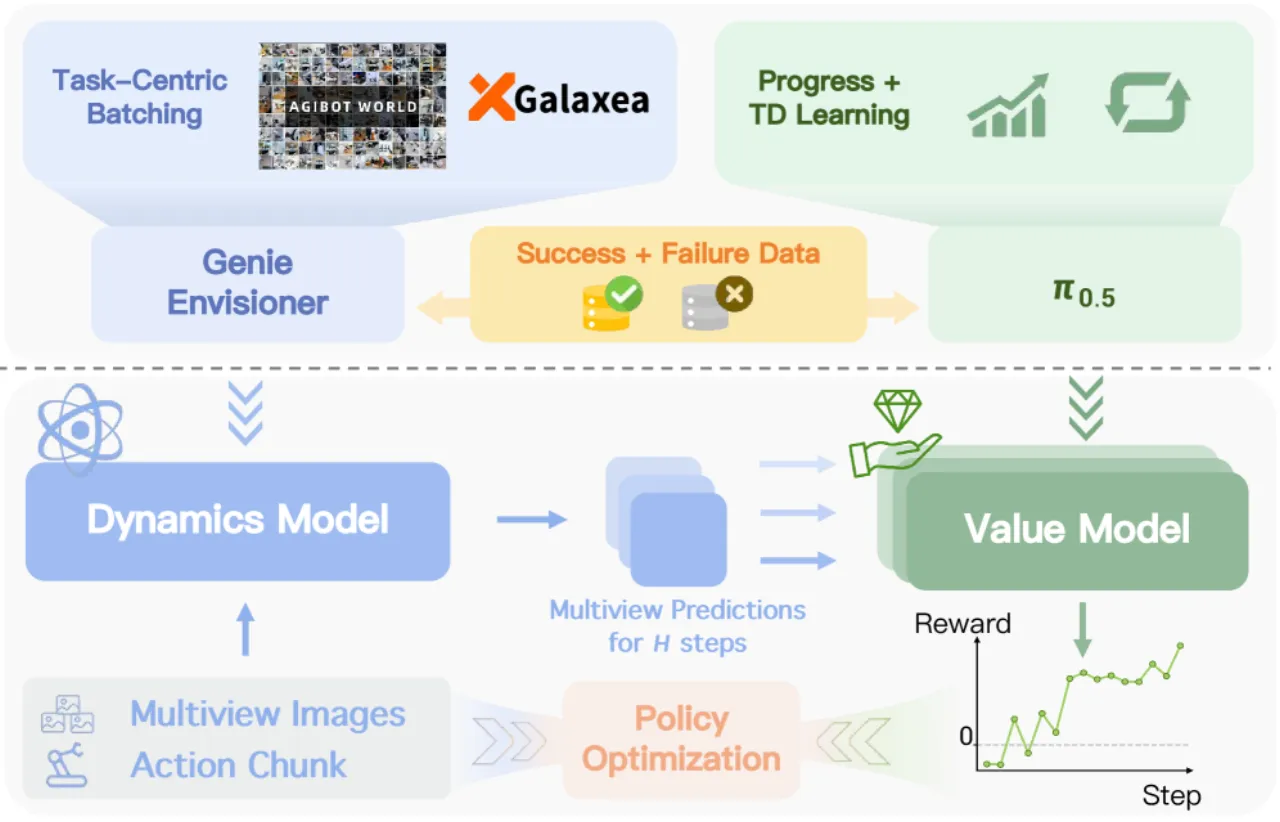
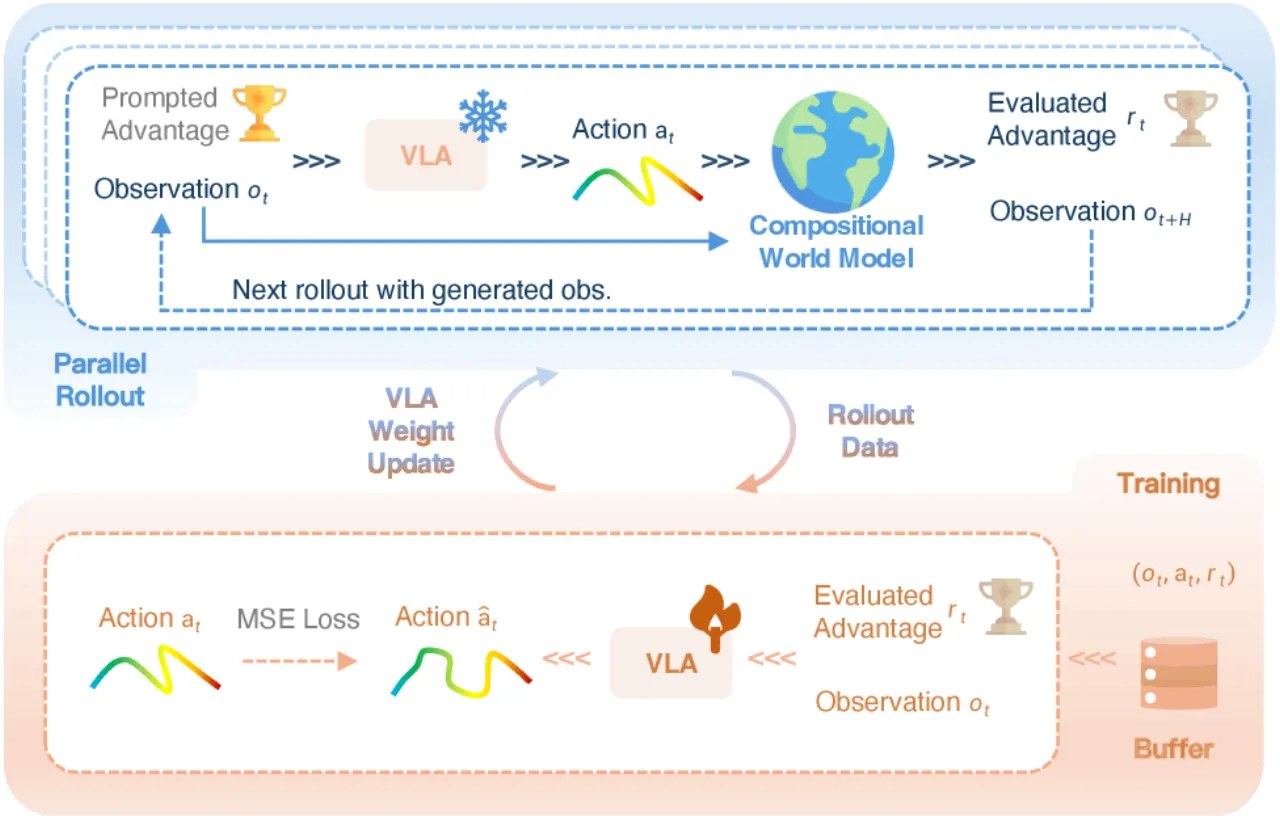
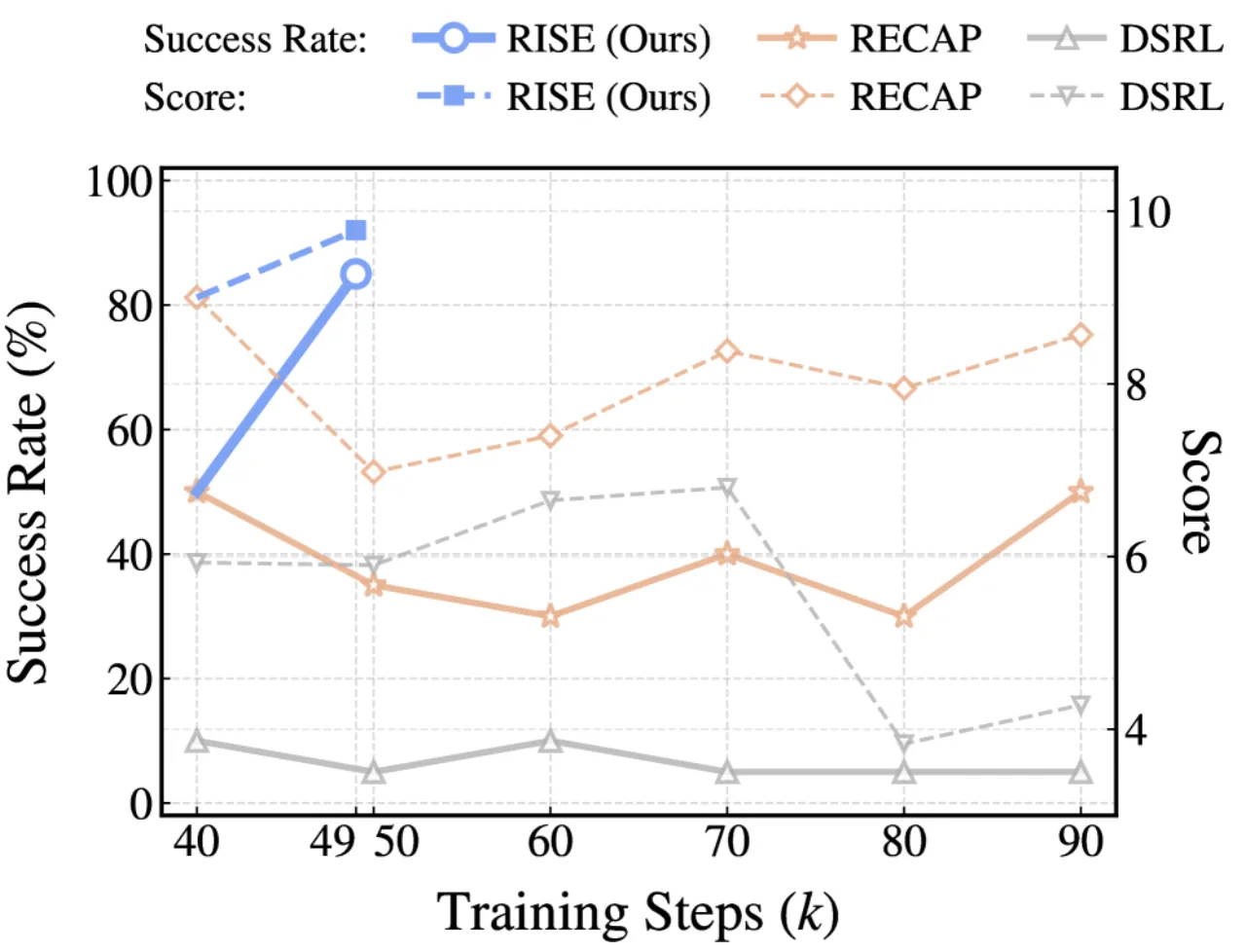
01 动机 Motivation
Vision-Language-Action(VLA)模型在接触密集型操作任务中表现脆弱,而在物理世界中直接跑 on-policy RL 受制于硬件成本、安全风险和环境重置的高昂代价。如何在无需大量真实物理交互的情况下,持续提升机器人 policy 的鲁棒性?
"While reinforcement learning (RL) offers a principled path to robustness, on-policy RL in the physical world is constrained by safety risk, hardware cost, and environment reset."
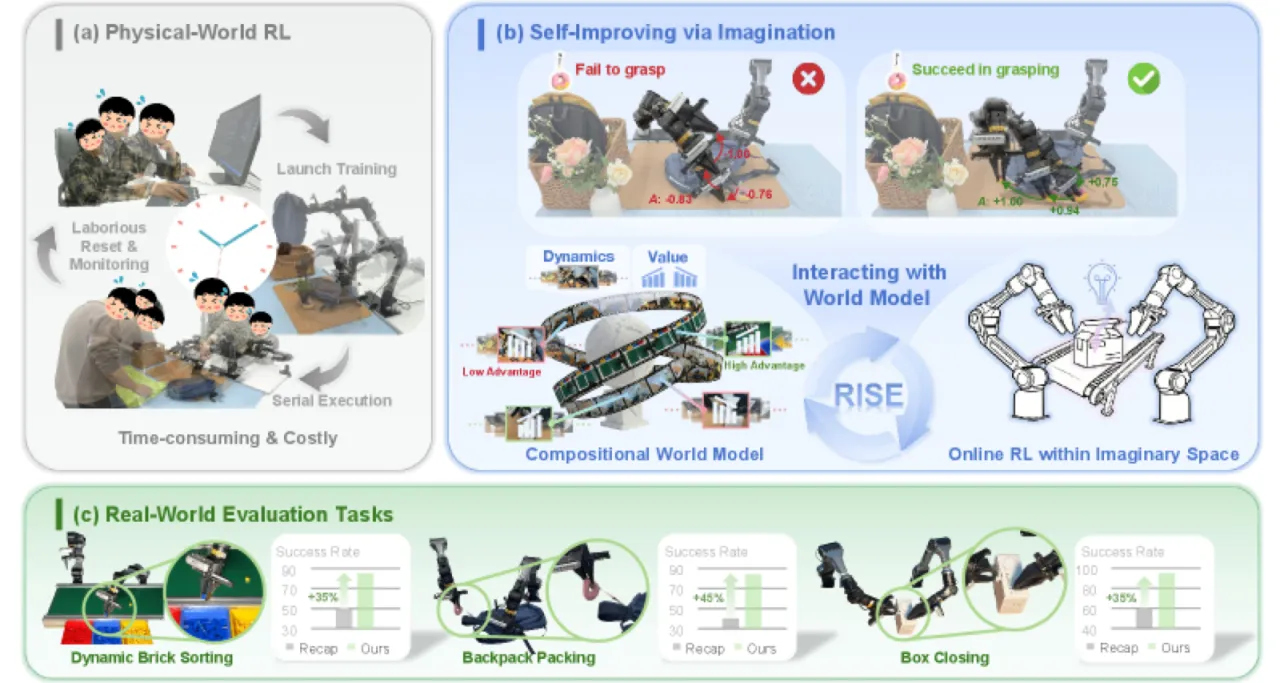
+35%Dynamic Brick Sorting
绝对成功率提升
绝对成功率提升
+45%Backpack Packing
绝对成功率提升
绝对成功率提升
+35%Box Closing
绝对成功率提升
绝对成功率提升
95%Box Closing
RISE 最高成功率
RISE 最高成功率