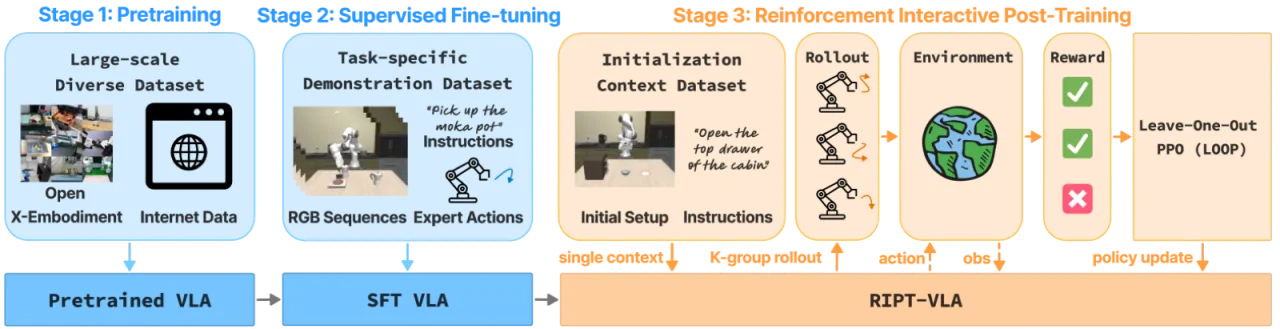
01 动机
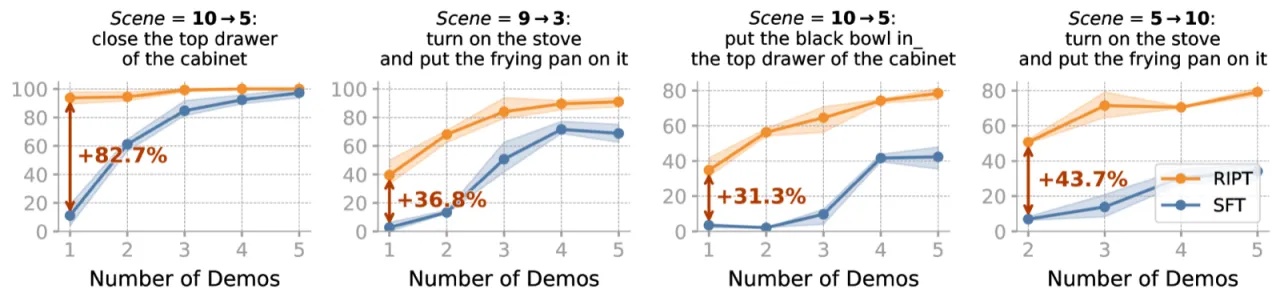
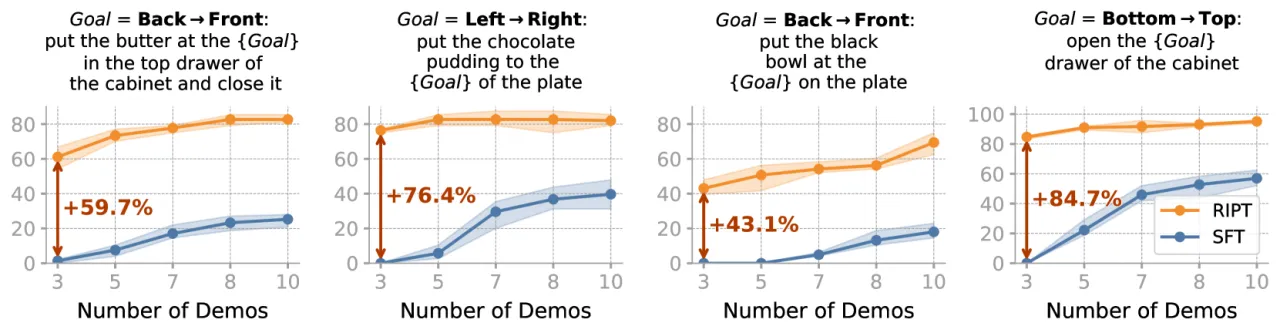
大型预训练 VLA 模型(如 OpenVLA、QueST)在离线监督微调(SFT)之后仍存在两大根本缺陷:模型从未体验过自身决策的环境反馈;任务特化微调又需要昂贵的大量专家演示。强化学习理论上可以弥补这两点,但将 RL 扩展到大规模多任务 VLA 时,面临奖励稀疏、信用分配模糊、多任务难度不均衡等挑战。
"Current VLA training paradigms operate on static offline datasets...models never experience the consequences of their own actions during training, and task-specific fine-tuning requires large quantities of expensive human demonstrations."
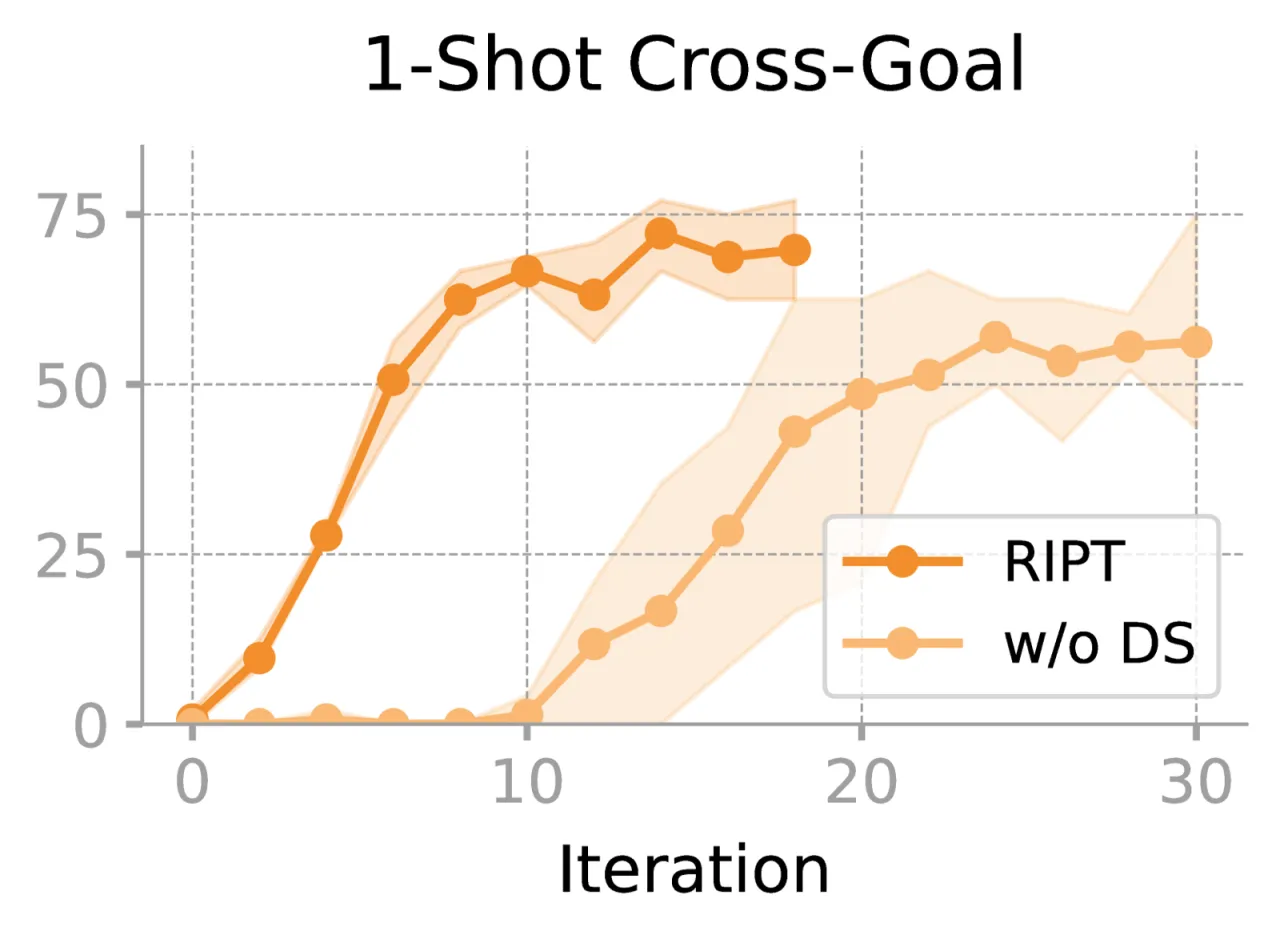
97%1-shot 场景下从 4% 到 97% 成功率(15 轮内)
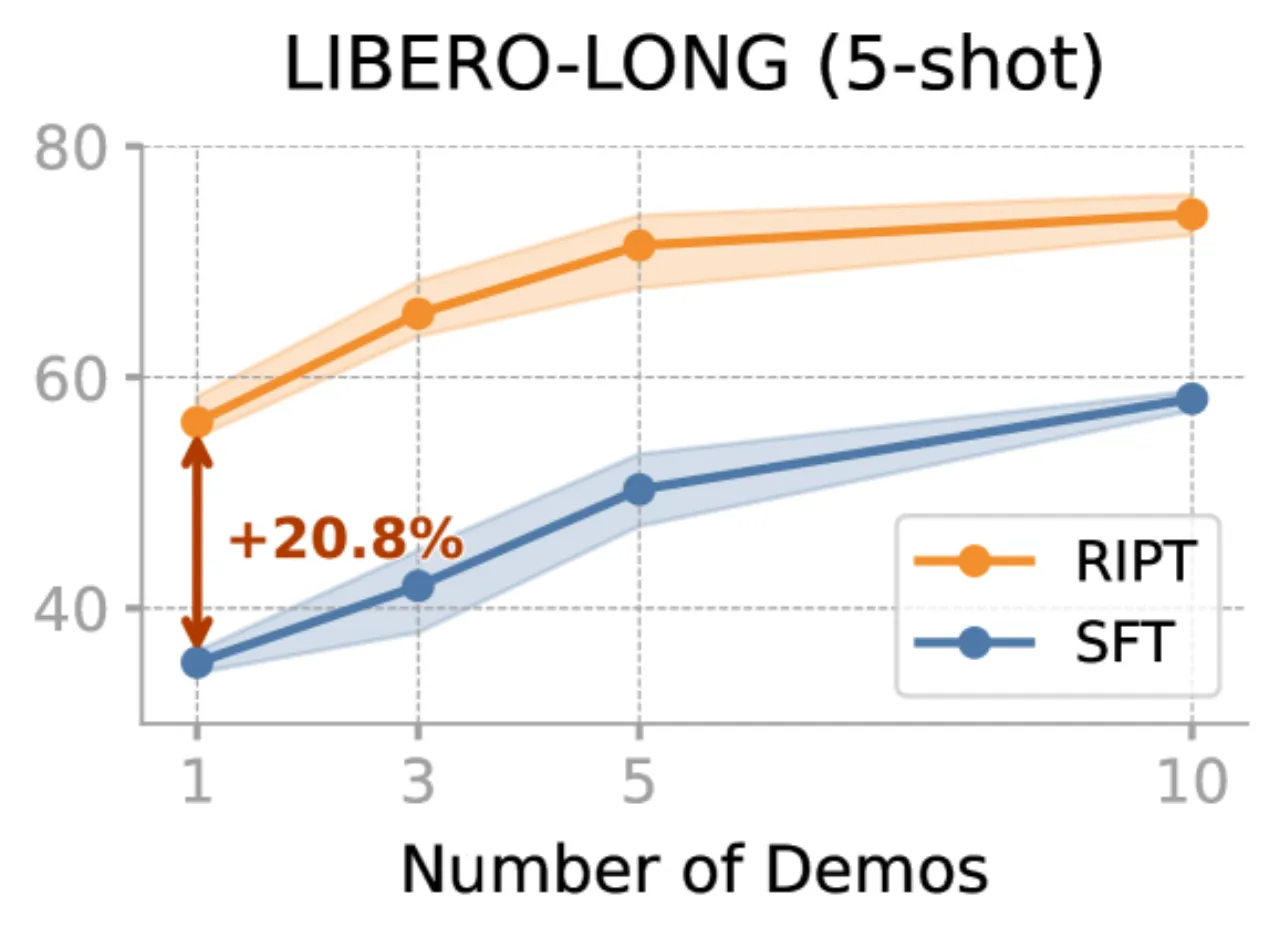
+21.2%LIBERO-LONG 5-shot 场景提升幅度
97.5%OpenVLA-OFT + RIPT 在 LIBERO 标准多任务成功率
+10.9%QueST 多任务平均成功率提升