01 动机
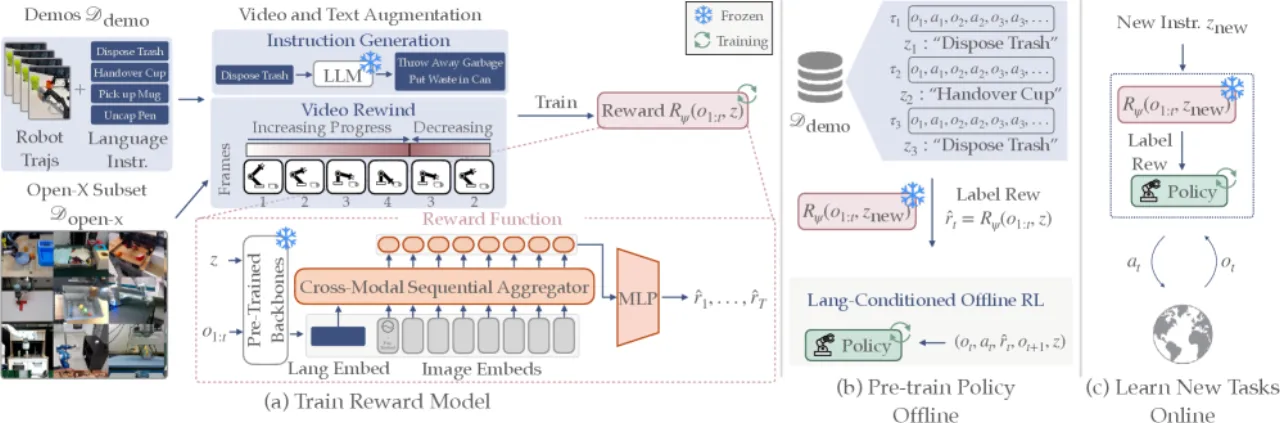
机器人学习长期面临两难困境:要么需要为每个任务人工设计奖励函数,要么需要大量专家示范数据。现有语言条件奖励学习方法往往依赖真值状态信息或数千条示范,难以推广到真实场景。
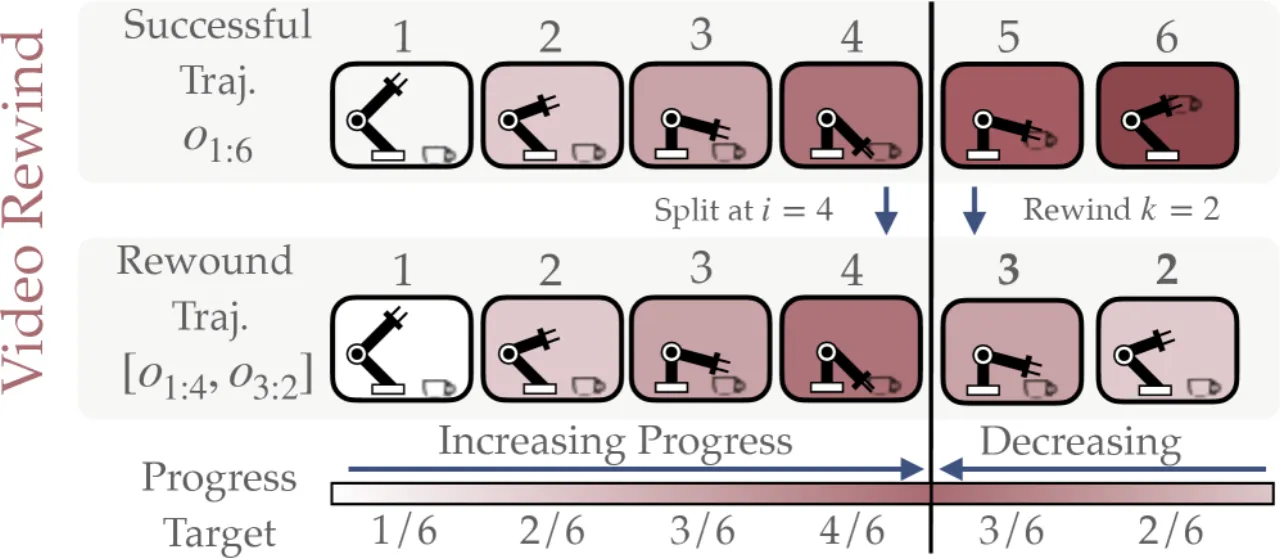
"我们的框架仅需少量示范(例如每个任务五条),便能让机器人通过语言指令学习未见过的任务变体,无需额外收集新示范。" —— 论文核心主张

2.4×奖励泛化提升(相对基线)
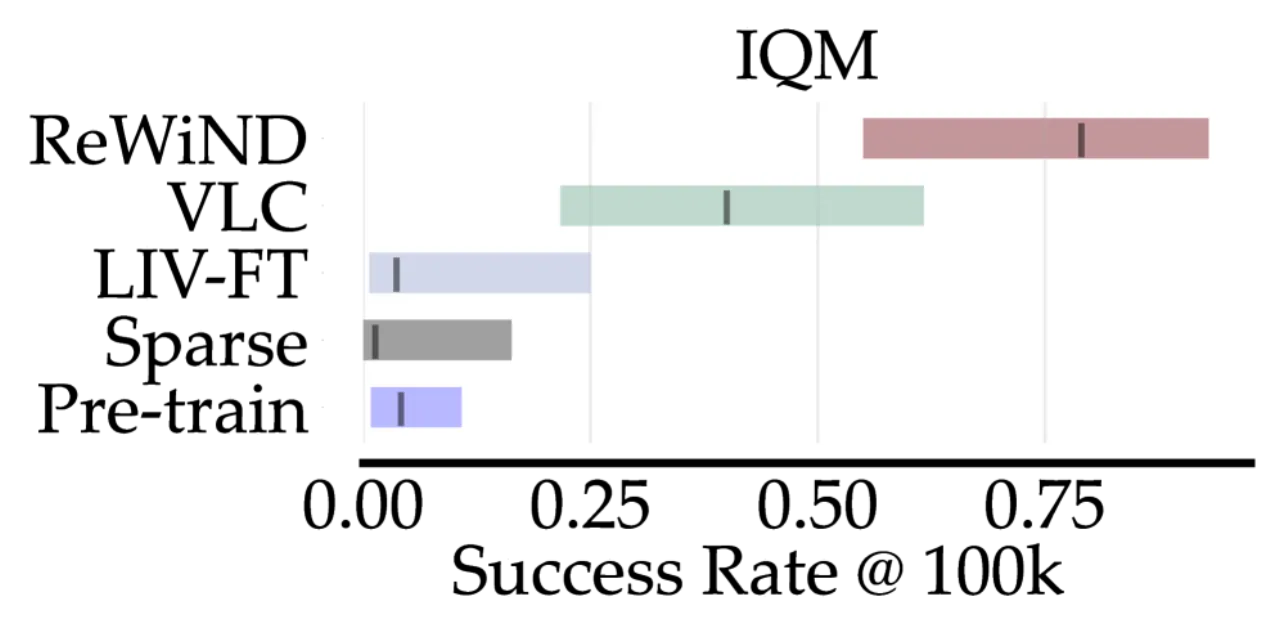
79%MetaWorld 仿真成功率(IQM)
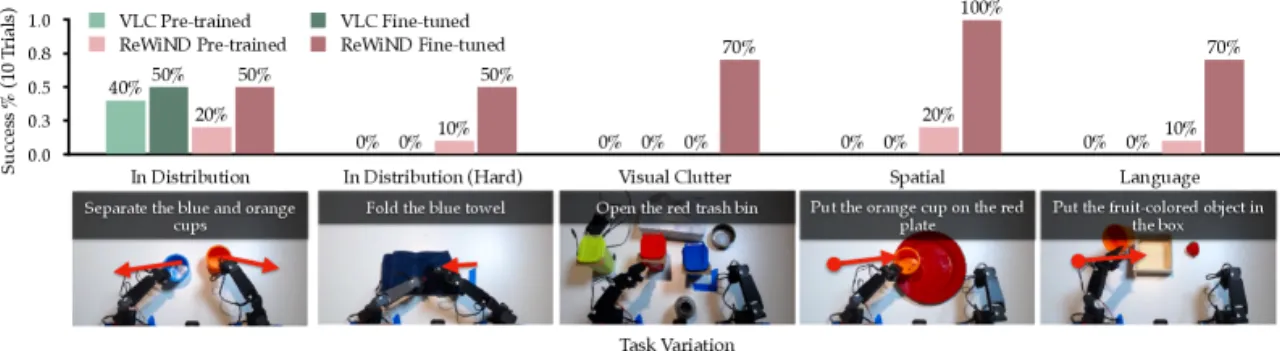
68%真实机器人微调后成功率
5×真实世界相对预训练策略提升
现有方法的不足
- 标准强化学习(RL):每个新任务都需要人工设计奖励函数,工程成本高昂。
- 模仿学习(Imitation Learning):依赖大量专家示范,采集成本高,且难以泛化到未见变体。
- 现有语言条件奖励方法(LIV、RoboCLIP、VLC、GVL 等):通常需要真值状态信息,或对数千条示范的需求,在真实机器人部署中不切实际。