01 动机
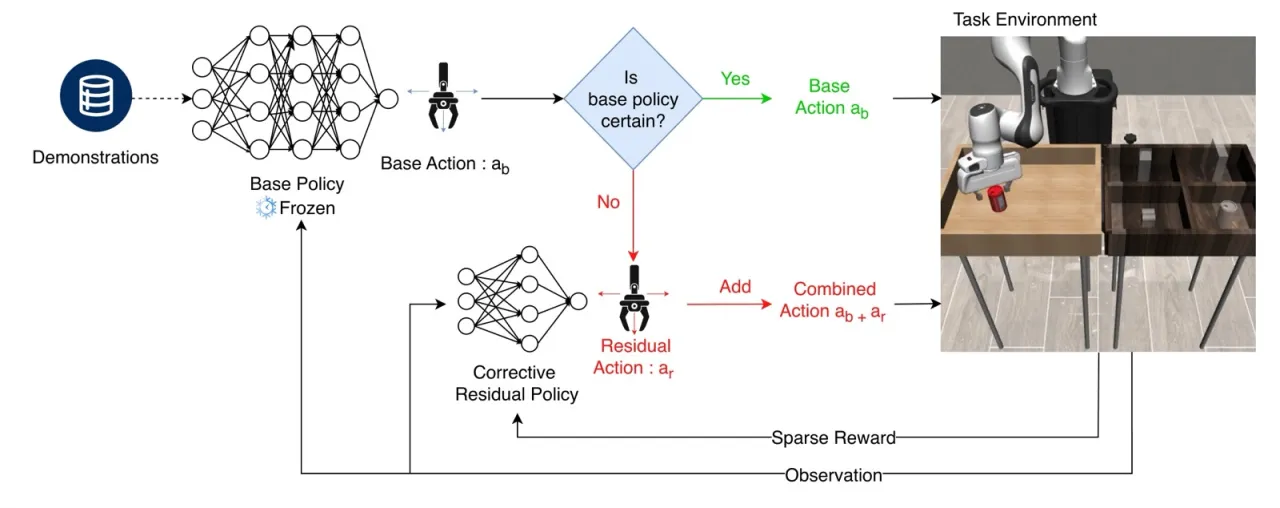
Residual RL 是将预训练策略与强化学习结合的流行范式——只训练一个输出"修正量"的小策略,而不是重新训练整个网络。但两个关键瓶颈制约了其实用性:
问题一:低效探索
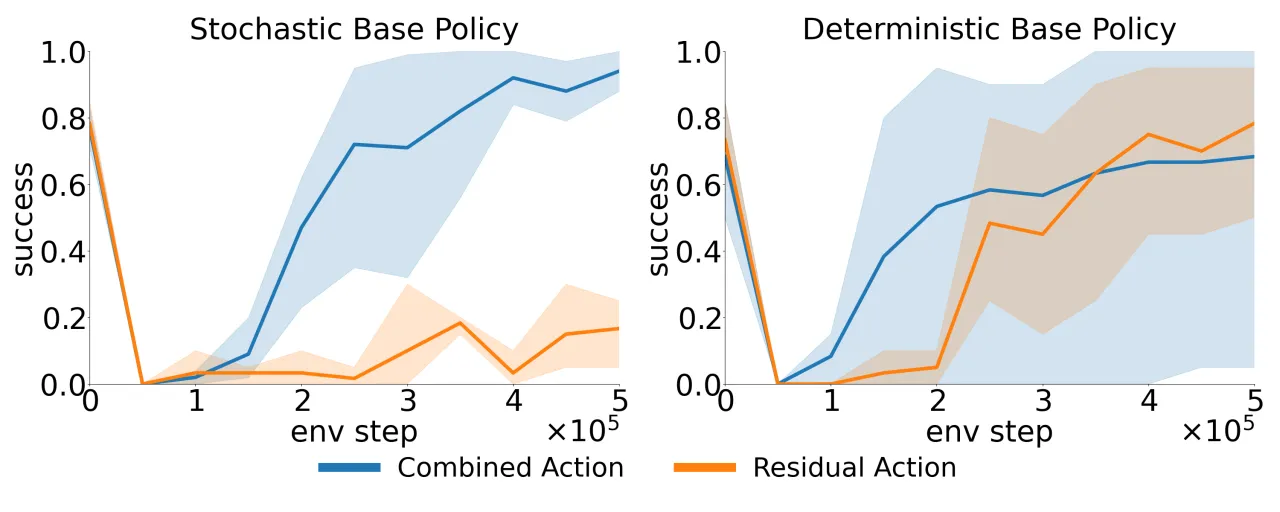
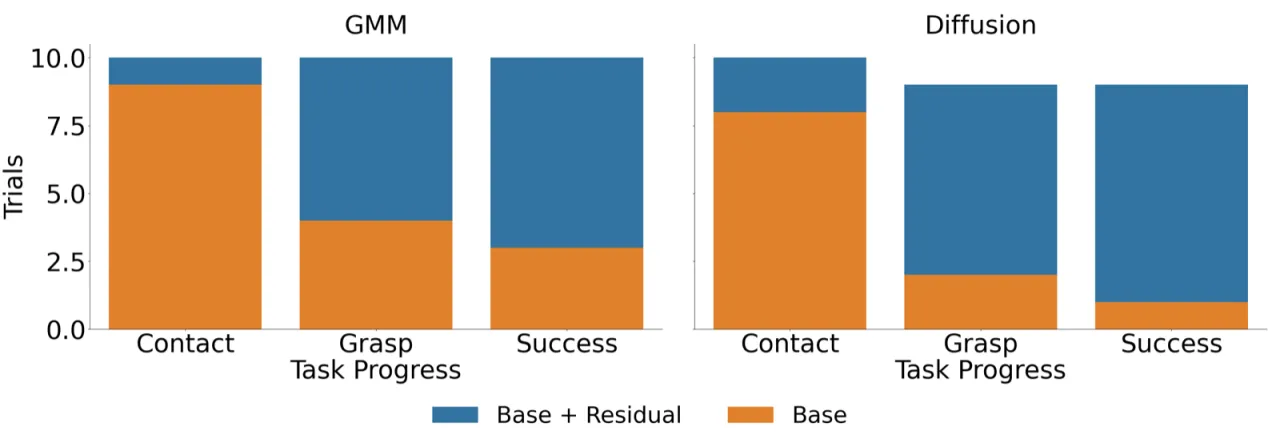
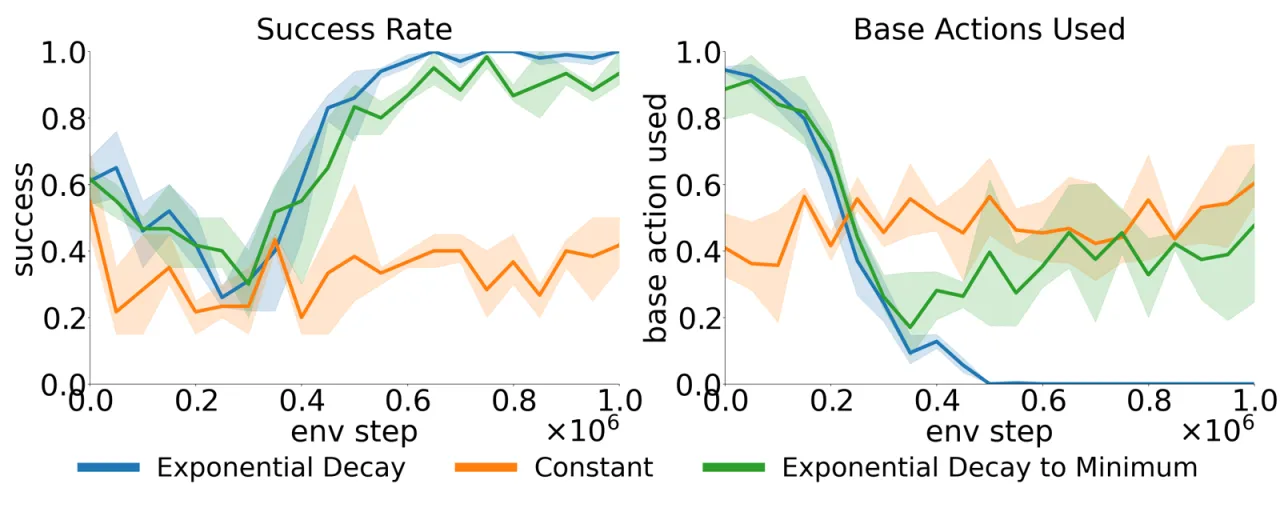
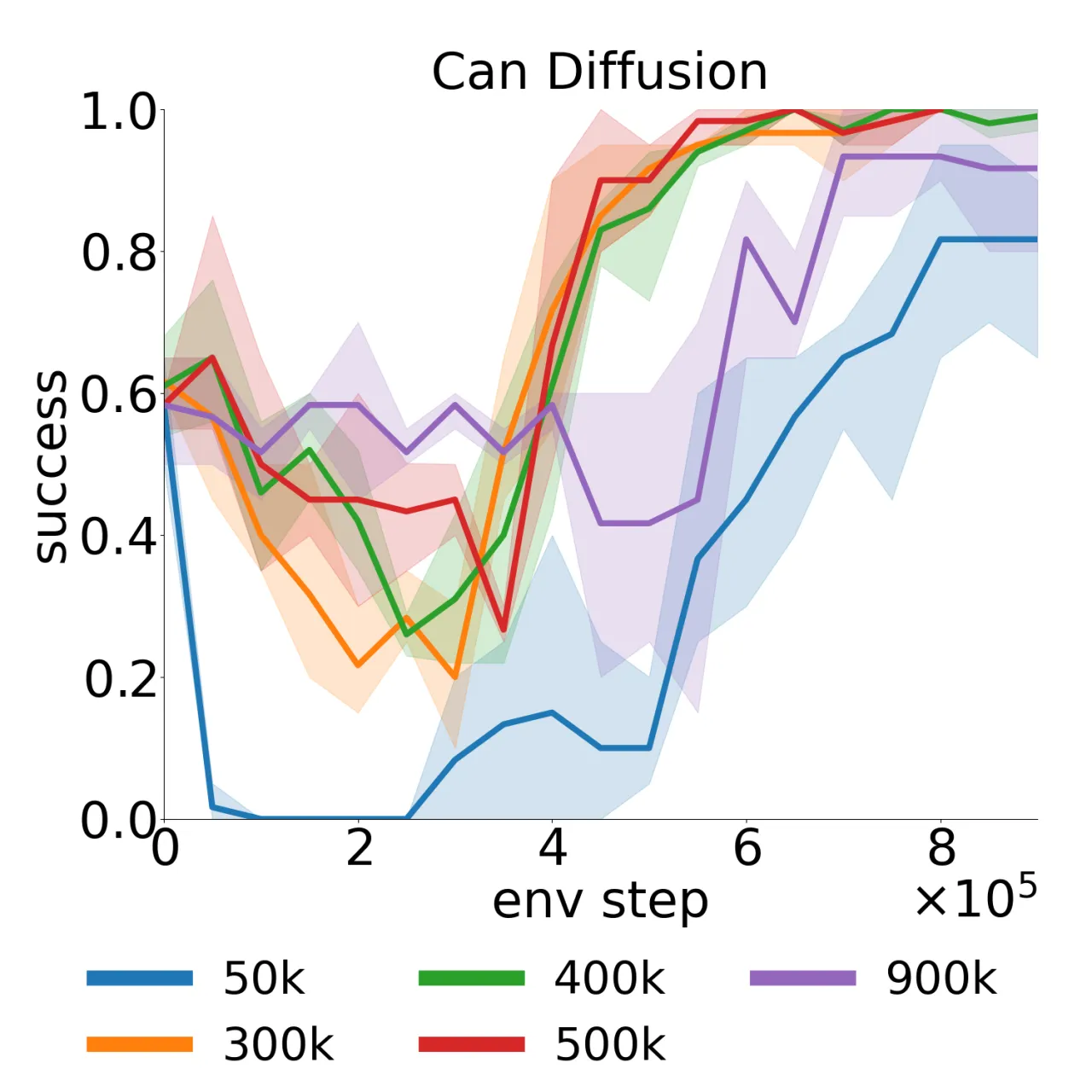
残差策略在整个状态空间均匀随机探索,而在基础策略已经表现良好的区域浪费大量样本。在稀疏奖励环境下,这一问题尤为突出。
问题二:仅支持确定性策略
现有 off-policy Residual RL 方法(如 TD3+BC、SAC)假设基础策略是确定性的。对于 GMM 或 Diffusion Policy 等随机基础策略,动作空间的随机性使 Q 函数训练失效。
"Residual RL is a popular approach for adapting pretrained policies by learning a lightweight residual policy that provides corrective actions. While Residual RL is more sample-efficient than finetuning the entire base policy, existing methods struggle with sparse rewards and are designed for deterministic base policies."
6测试任务数
(Robosuite + D4RL + 真实机器人)
(Robosuite + D4RL + 真实机器人)
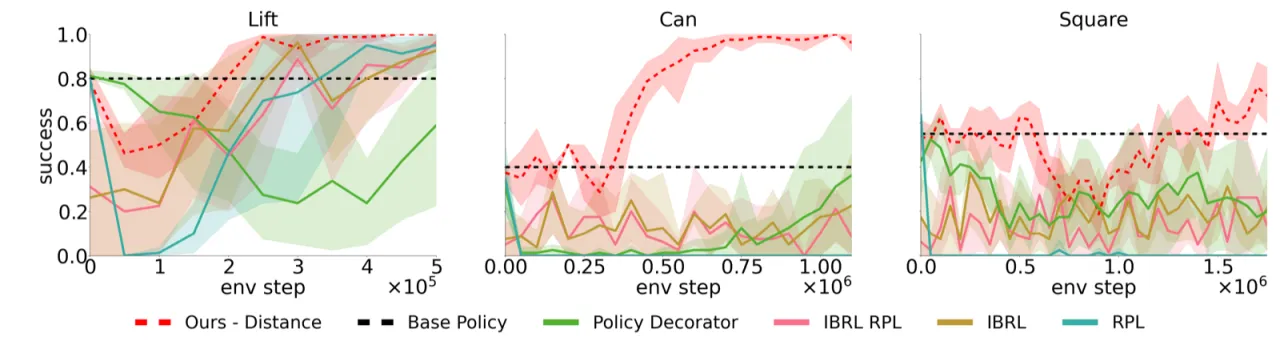
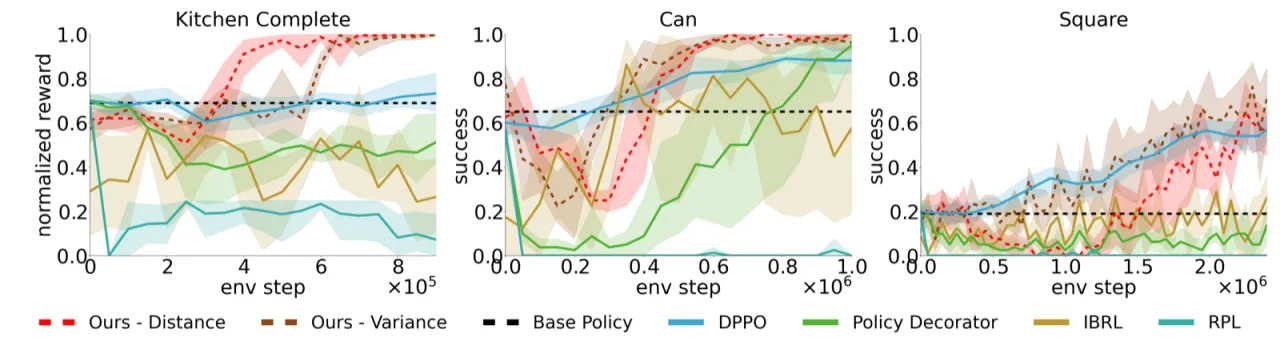
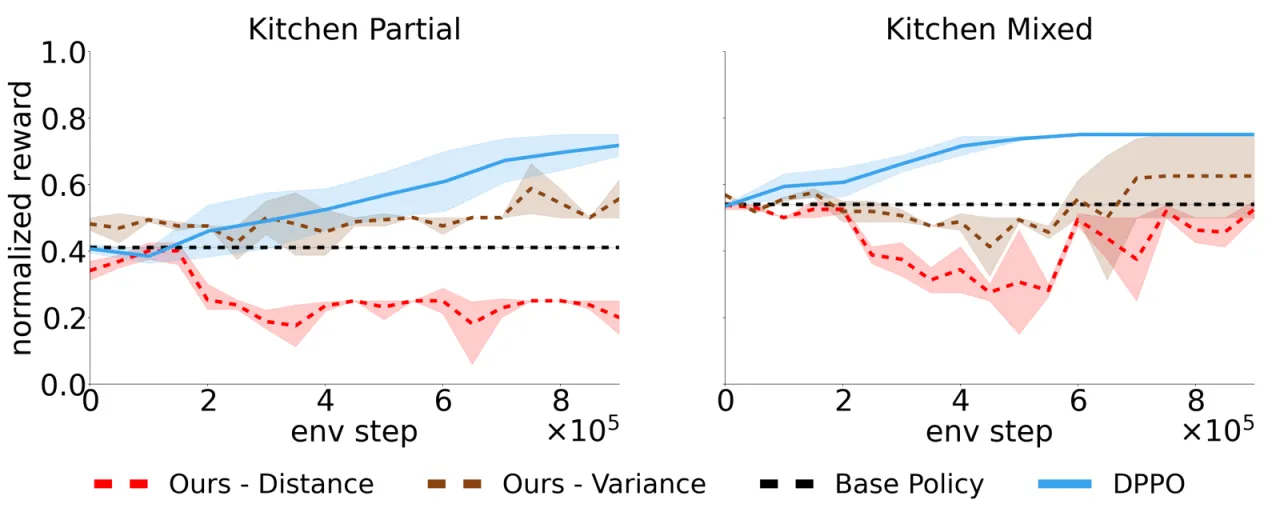
4+对比基线方法
(DPPO, IBRL, Policy Decorator, 标准 Residual RL)
(DPPO, IBRL, Policy Decorator, 标准 Residual RL)
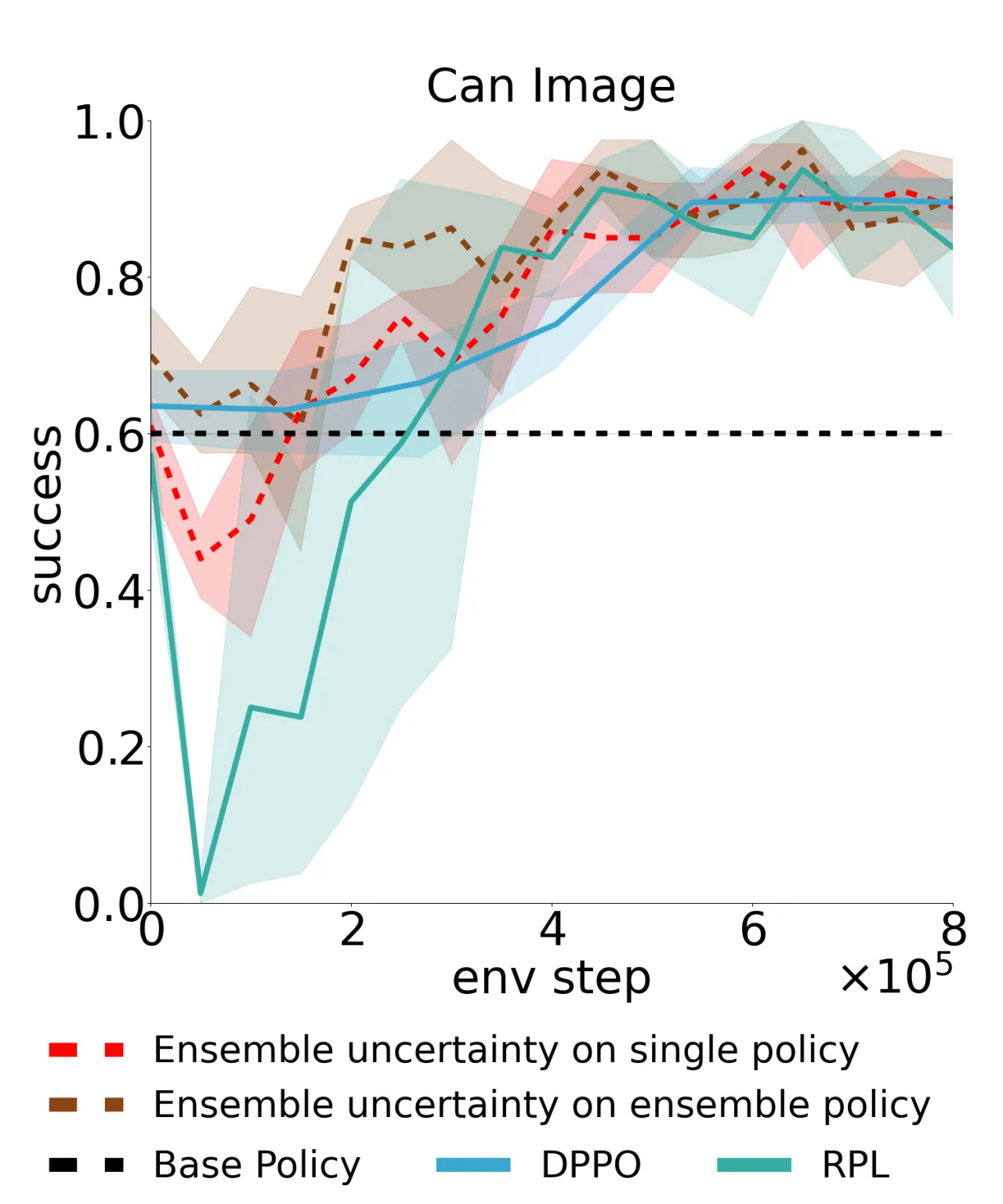
2不确定性度量
(distance-to-data, ensemble variance)
(distance-to-data, ensemble variance)
sim→real零样本迁移
保留近乎全部仿真性能
保留近乎全部仿真性能