01 动机
机器人操作任务涉及多阶段、双臂协作、以及与动态物体的复杂空间关系。现有方法要么依赖大量任务专属训练数据,要么难以对操作过程中的接触关系做精确时空建模,在面对多样化场景时泛化能力有限。
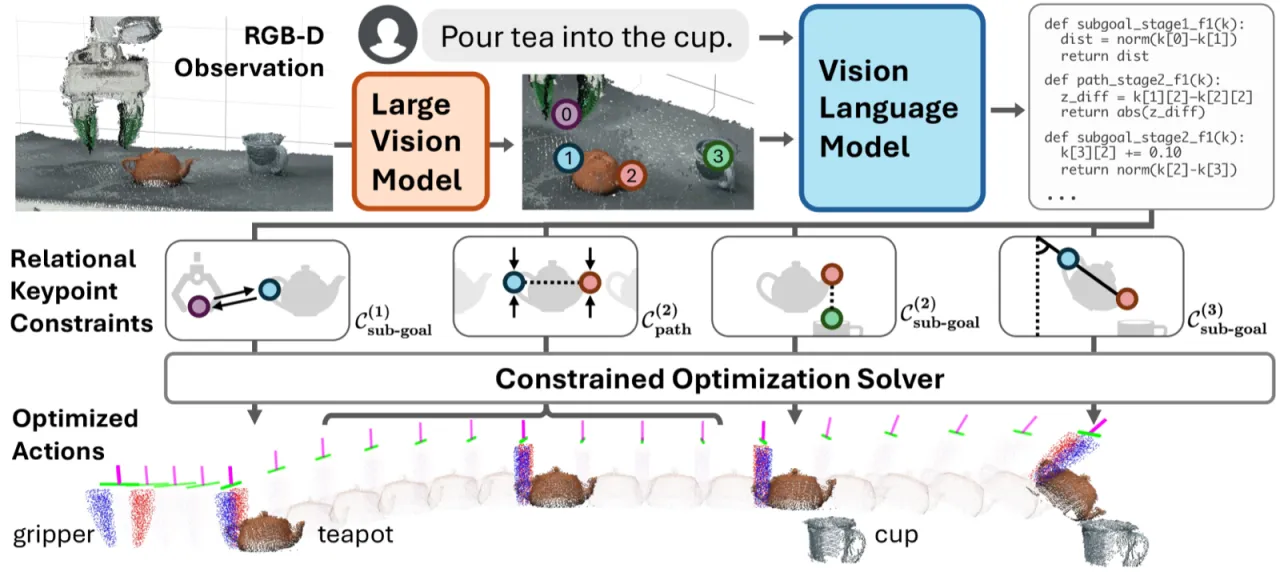
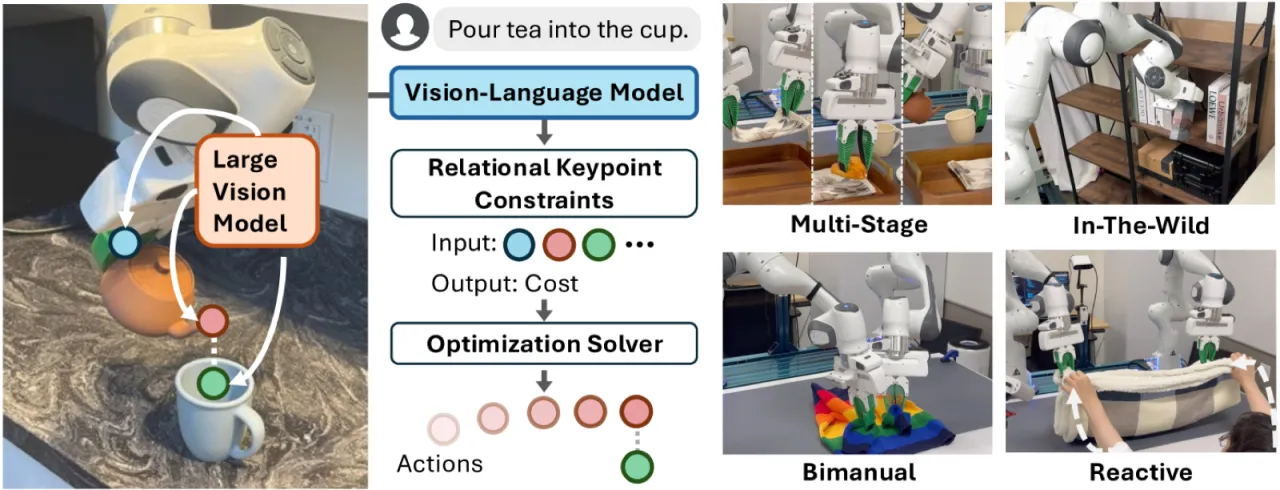
"We present ReKep, a visually-grounded constraint representation for robotic manipulation … [which] automatically generates constraints from language instructions and RGB-D observations using a vision-language model, which are then solved by a hierarchical optimization procedure."
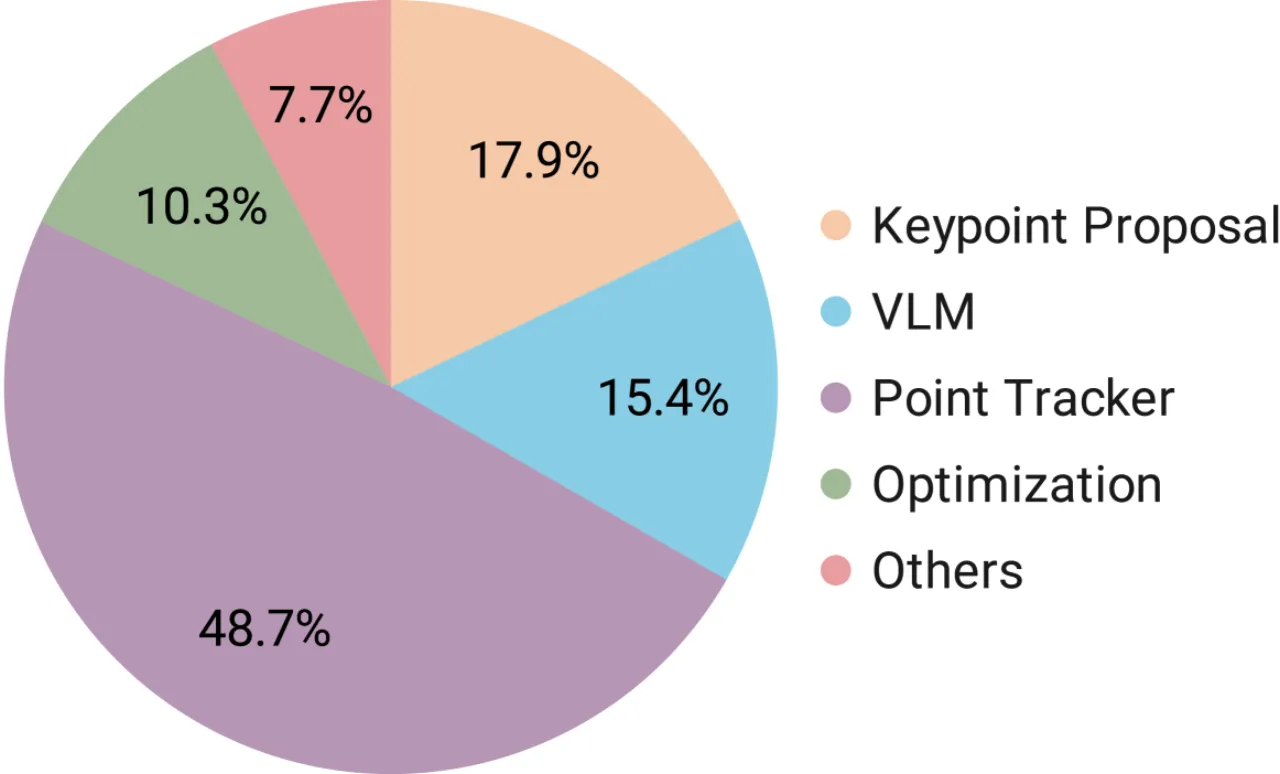
68.6%总体成功率
(vs. VoxPoser 10.0%)
(vs. VoxPoser 10.0%)
46.7%扰动条件下成功率
(vs. VoxPoser 6.7%)
(vs. VoxPoser 6.7%)
7多样化测试任务
(单臂 + 双臂)
(单臂 + 双臂)
~10 Hz实时优化求解频率