01 动机
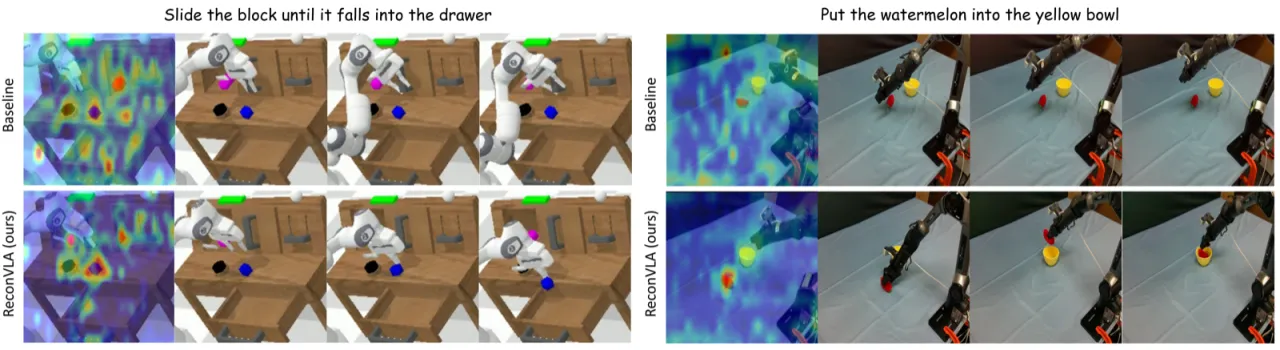
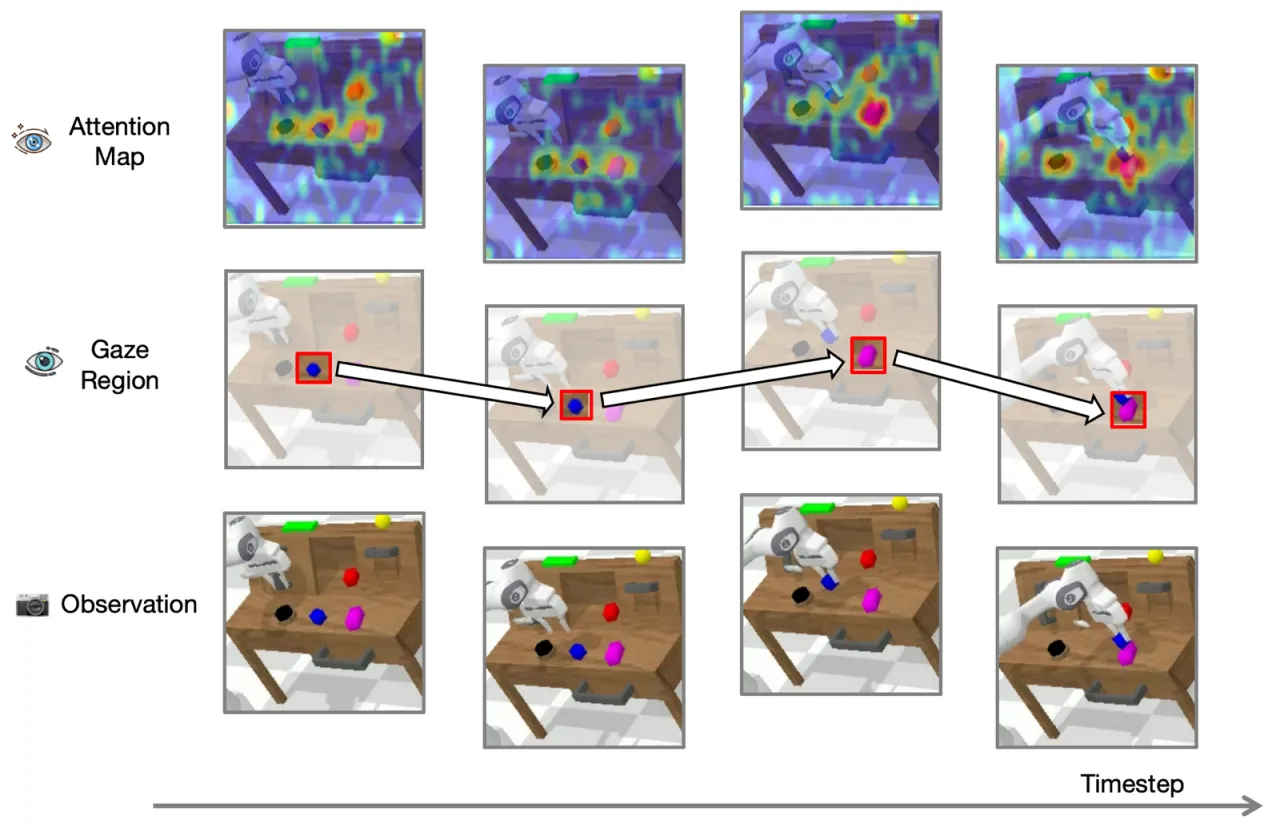
现有 VLA 模型在视觉感知上存在根本性缺陷——注意力分散,难以精准定位目标操作物体,导致在杂乱场景和精细任务中表现不佳。
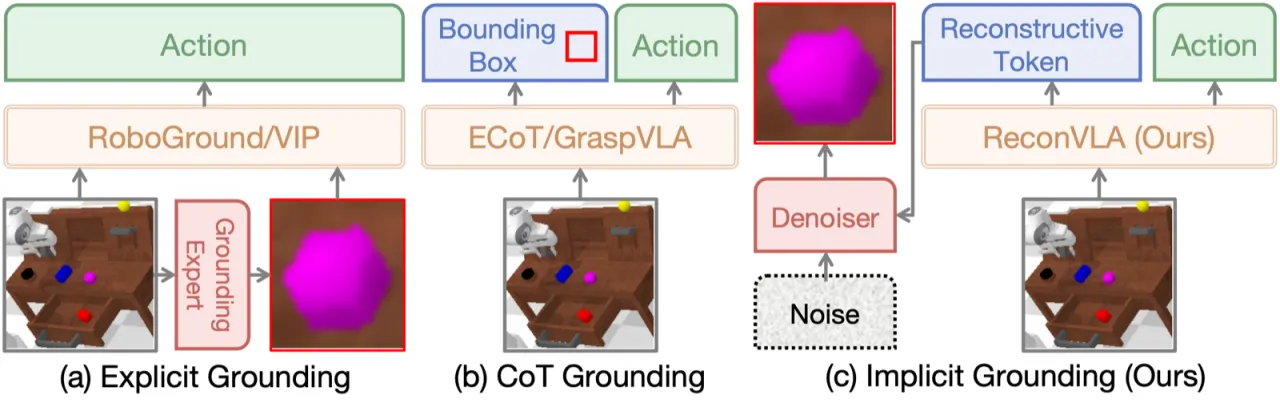
"visual attention is always dispersed" rather than focusing on target objects. Existing visual grounding methods either explicitly input cropped images or output bounding boxes in chain-of-thought fashion, but "do not fundamentally refine the attention allocation."
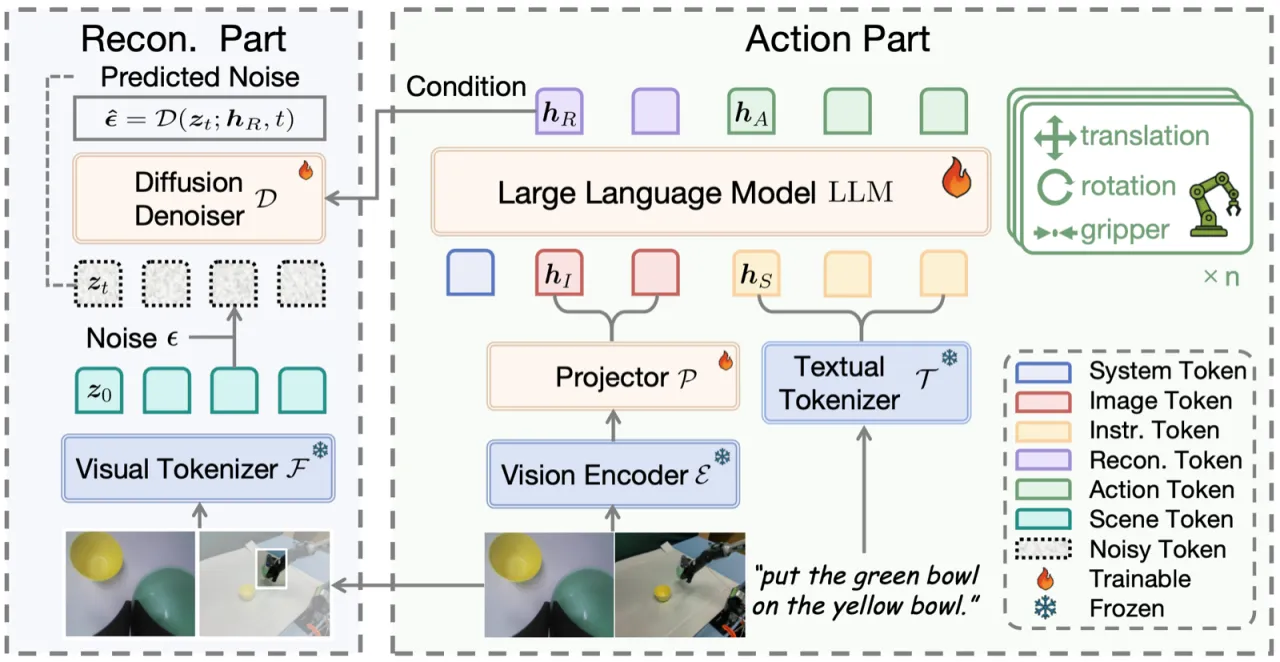
作者观察到,人眼感知的本质是:眼睛对焦的小区域清晰,周围区域模糊。现有 explicit grounding(输入裁剪图像)和 chain-of-thought grounding(输出 bounding box 坐标)两类方法都无法从根本上改变 LLM 内部的注意力分配。ReconVLA 通过隐式重建凝视区域,让模型在特征层面聚焦目标,而非依赖外部后处理。
3.95CALVIN ABC→D 平均完成序列长度(最优)
64.1%CALVIN ABC→D 5/5 子任务成功率(最优)
+20.2%精细 "stack block" 任务 vs. baseline
2M+预训练数据量(轨迹样本)