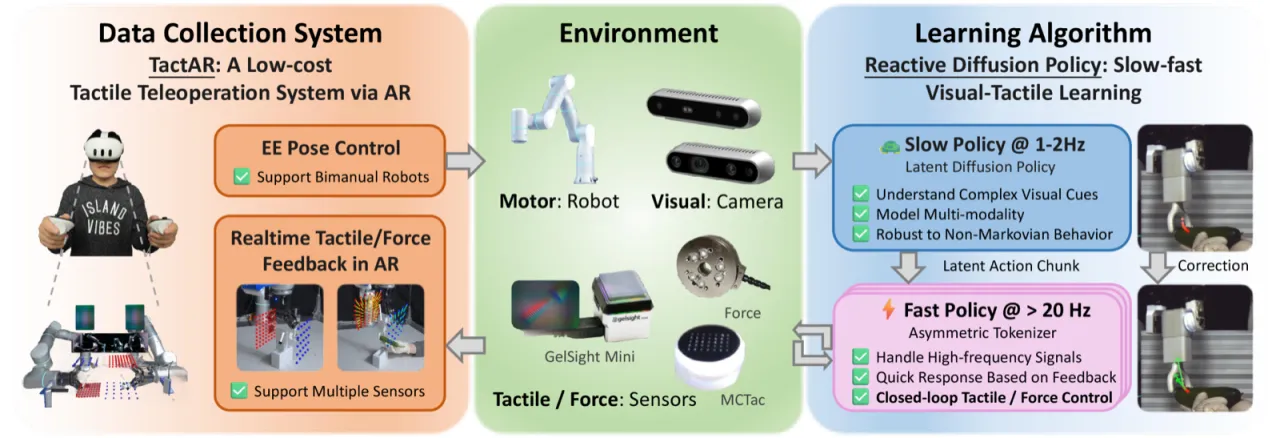
01 动机
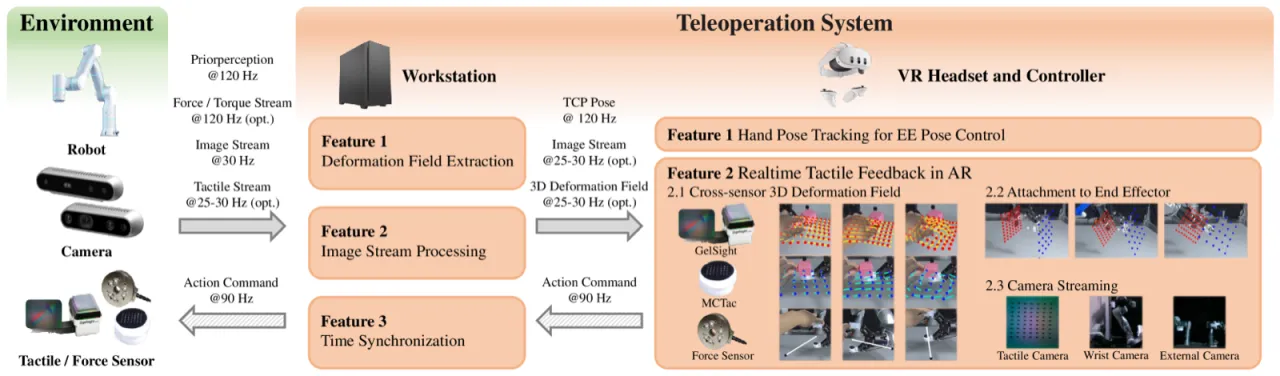
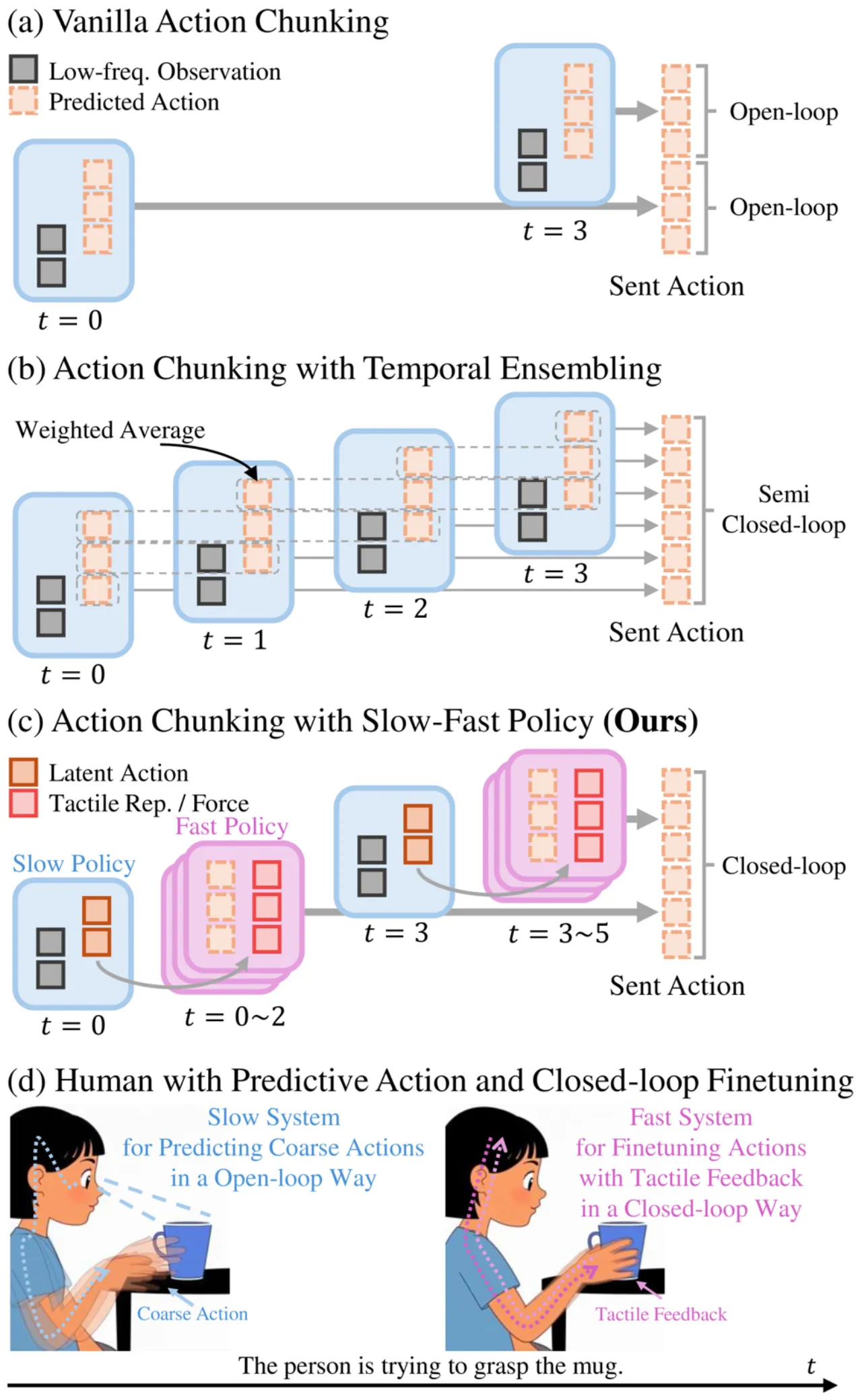
人类天然具备视觉与触觉的协同感知能力,能在接触过程中即时做出毫米级精度调整。而现有机器人操作方法面临双重困境:一方面,遥操作系统普遍缺乏精细的触觉/力反馈,导致采集的演示数据质量受限;另一方面,以 action chunking 为代表的视觉模仿学习范式将动作分块执行,形成开环控制,根本上无法在接触过程中即时响应触觉信号。
"Action chunking enables the policy to model complex behaviors but prevents immediate responses to tactile feedback during execution."
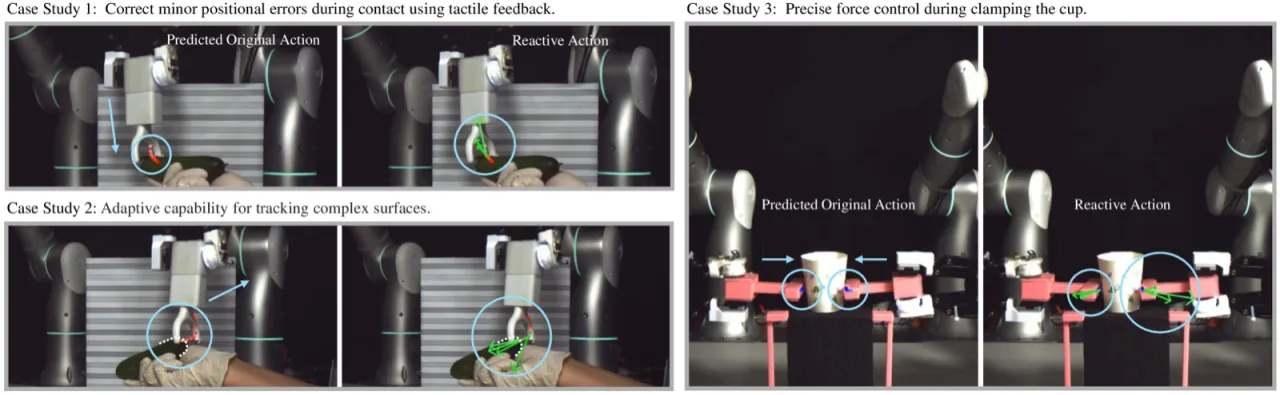
0.90RDP (GelSight) Peeling 综合得分(vs. 基线 0.39)
0.87RDP (Force) Wiping 综合得分(vs. 基线 0.50)
0.70RDP (Force) Bimanual Lifting 综合得分(vs. 基线 0.08)
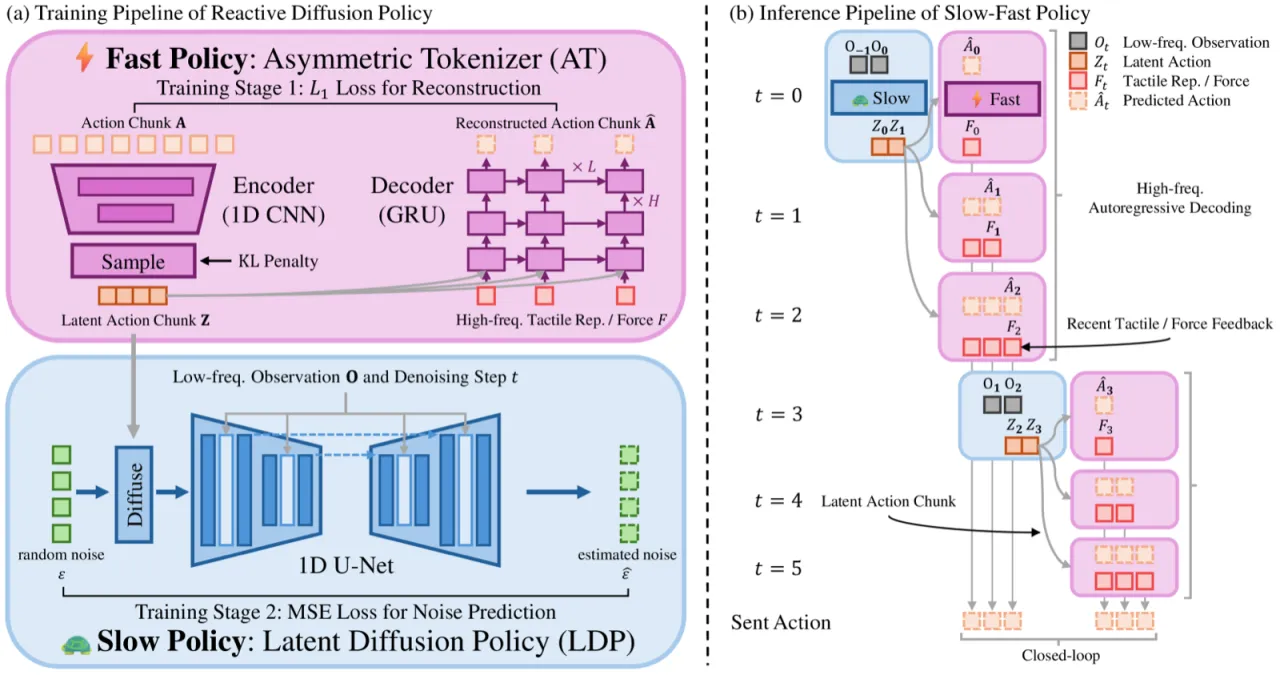
<1 msFast policy 推理延迟,理论支持 >300 Hz 触觉输入