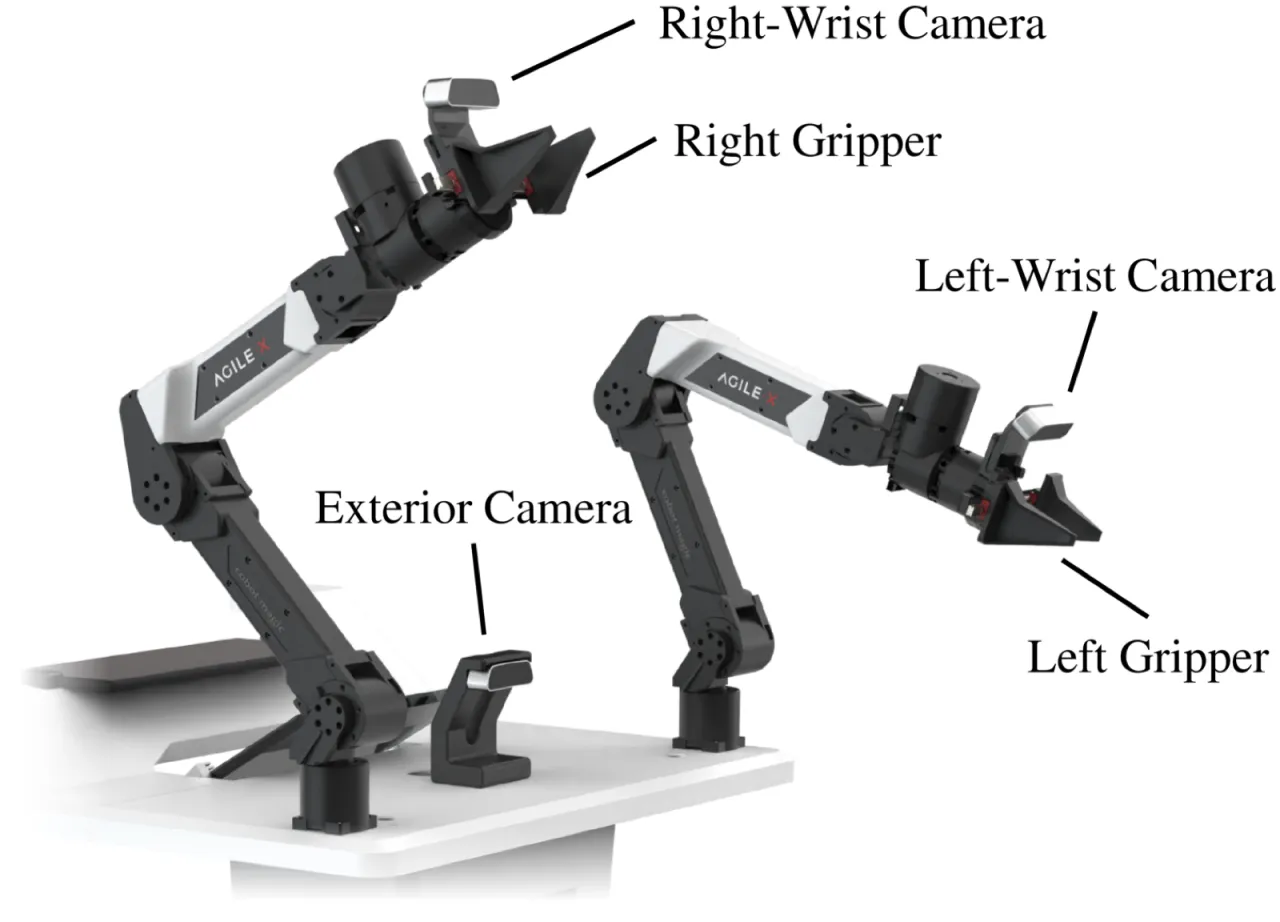
01 动机
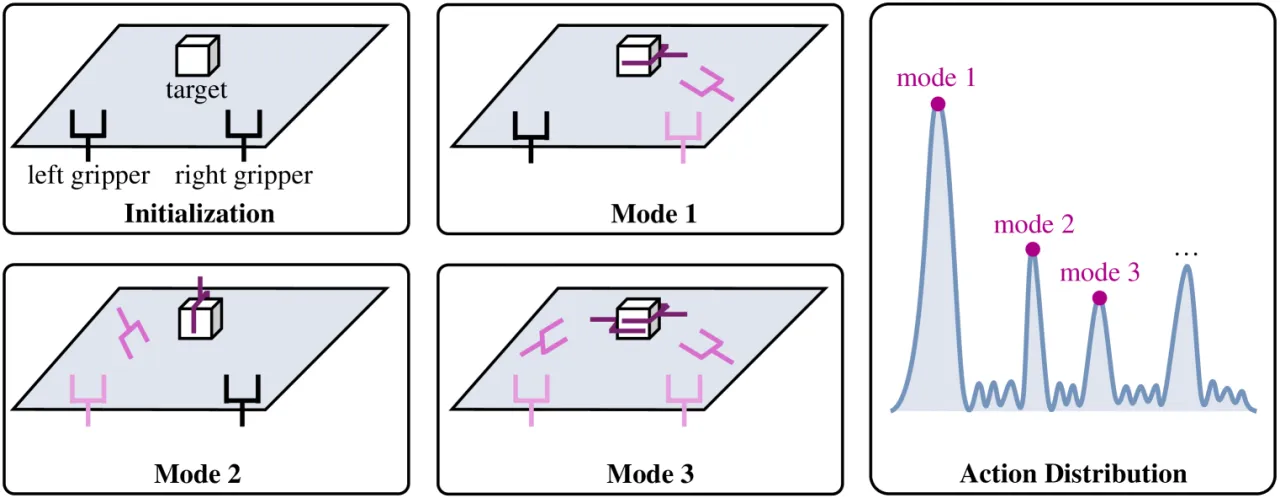
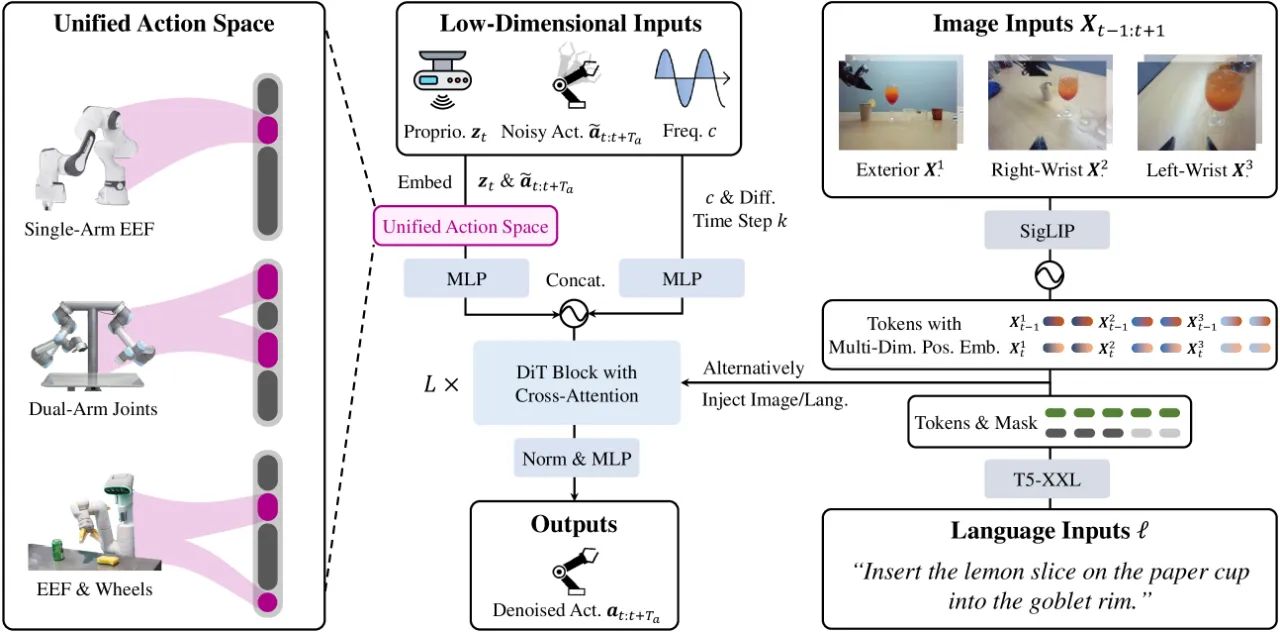
双臂操作是机器人走向真实世界的关键能力,但现有方法面临两大核心挑战: 一是双臂协调产生的多模态动作分布(同一任务可能存在多种合理的执行方式), 二是双臂演示数据的严重匮乏,限制了模型的泛化能力。 作者指出,现有扩散模型在机器人操作上最多只达到 93M 参数规模,难以充分利用大规模多机器人数据。
"Bimanual manipulation is essential in robotics, yet developing foundation models is extremely challenging due to the inherent complexity of coordinating two robot arms (leading to multi-modal action distributions) and the scarcity of training data."
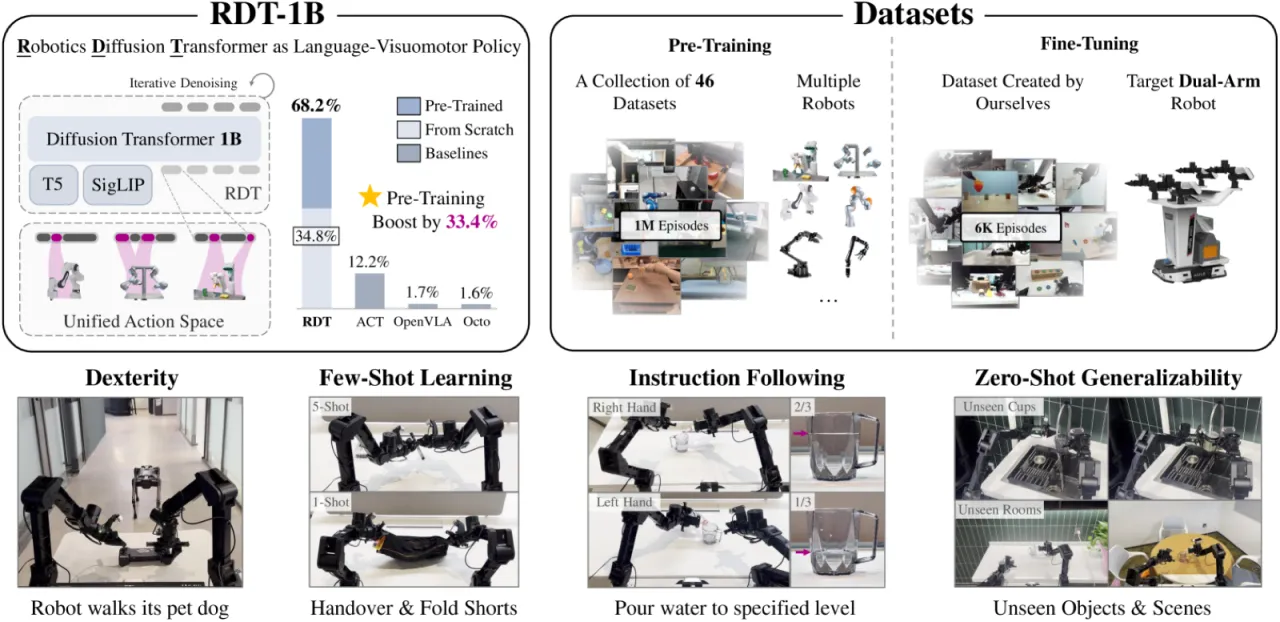
1.2B模型参数量(机器人扩散模型最大)
56%在多项挑战任务上提升幅度(相对基线)
1M+预训练轨迹数 / 21TB 数据
6K+微调双臂演示条数 / 300+ 任务