01 动机(Motivation)
传统的 Q-learning 将回报(return)的随机性平均掉,只估计期望值。Bellemare 等人(C51)虽然提出了分布式 Bellman 算子并证明其在 Wasserstein 度量下是收缩的,却因随机梯度无法直接最小化 Wasserstein 损失而被迫退而求其次,使用 KL 散度加上启发式投影,留下了一个理论与算法之间的缺口。
"This negative result left open the question as to whether it is possible to devise an online distributional reinforcement learning algorithm which takes advantage of the contraction result... In this paper, we answer this question affirmatively."
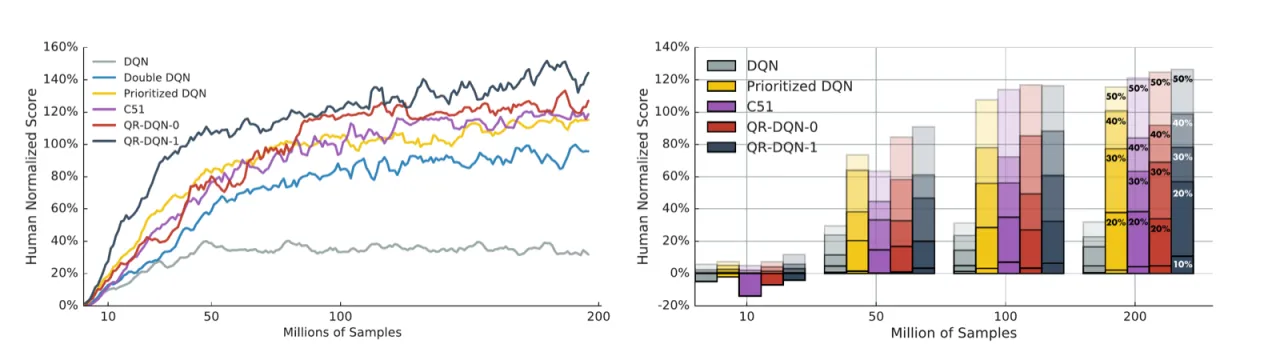
+33%中位数得分相对 C51 提升(Huber 分位数损失)
211%QR-DQN-1 在 57 Atari 游戏上的中位数人类归一化得分(best agent)
915%QR-DQN-1 平均人类归一化得分(best agent)
N=200最优分位数数量(超参数搜索结果)
为何 Wasserstein 度量具有吸引力?
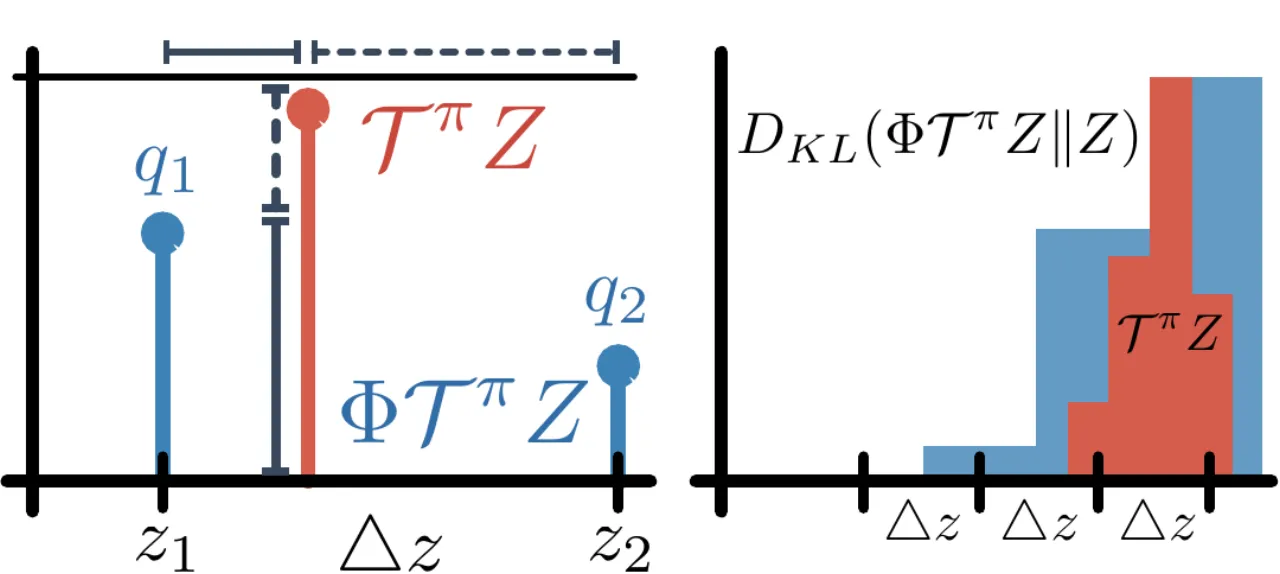
Wasserstein 度量(又称 Earth Mover's Distance,EMD)是分布间的积分概率度量,能够考虑不同结果之间的距离,而 KL 散度在支撑不相交时会产生问题。Lemma 3(来自 C51)已经证明分布式 Bellman 算子 Tπ 在 d̄p(最大化形式的 p-Wasserstein 度量)下是 γ-收缩的:
d̄p(TπZ₁, TπZ₂) ≤ γ · d̄p(Z₁, Z₂)
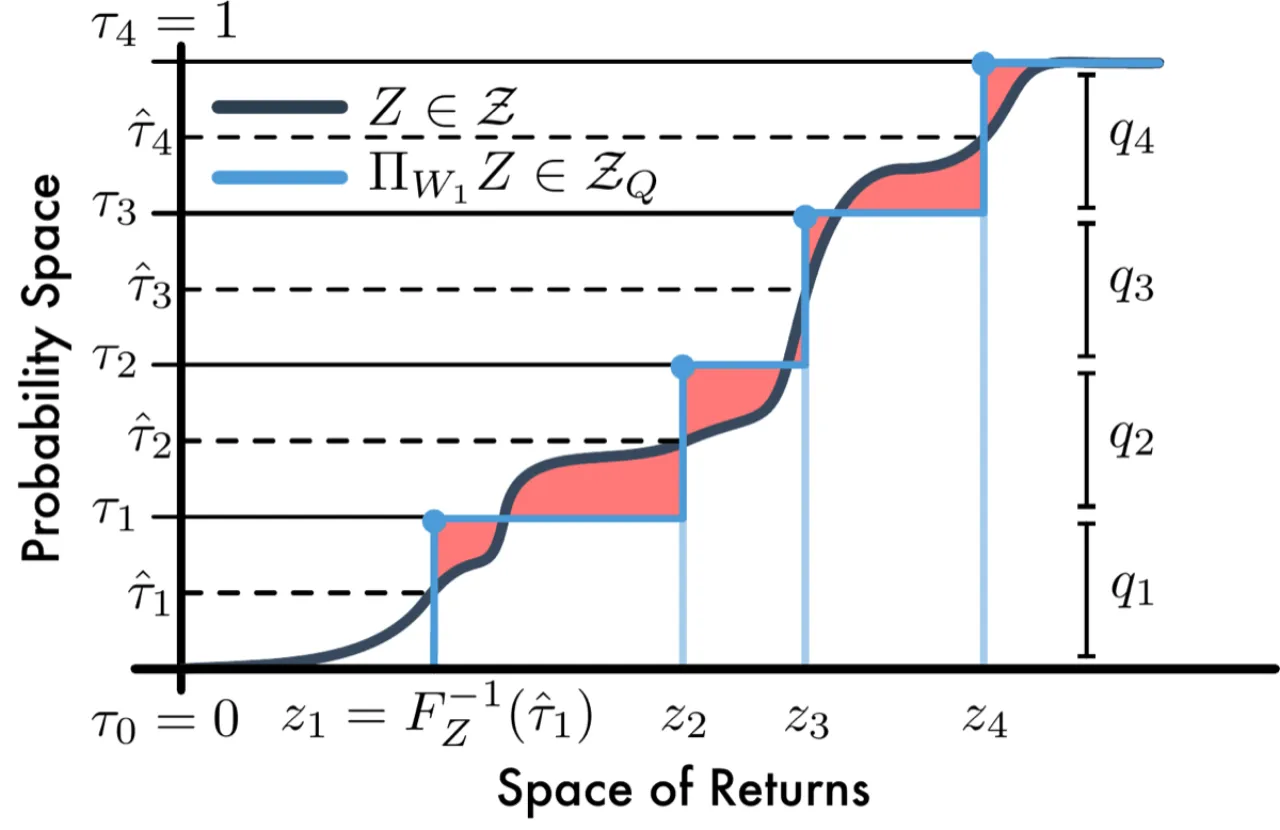
但随机梯度下降无法直接最小化 Wasserstein 损失(Theorem 1,Bellemare et al. 2017):对于样本经验分布,期望样本损失的最优解与真实 Wasserstein 损失的最优解通常不同。因此,C51 实际用的是 KL 散度,而非 Wasserstein,导致理论与实现脱节。QR-DQN 的核心贡献是找到了一种参数化方式,使得分位数回归可以给出 Wasserstein 的无偏随机梯度。