01 动机
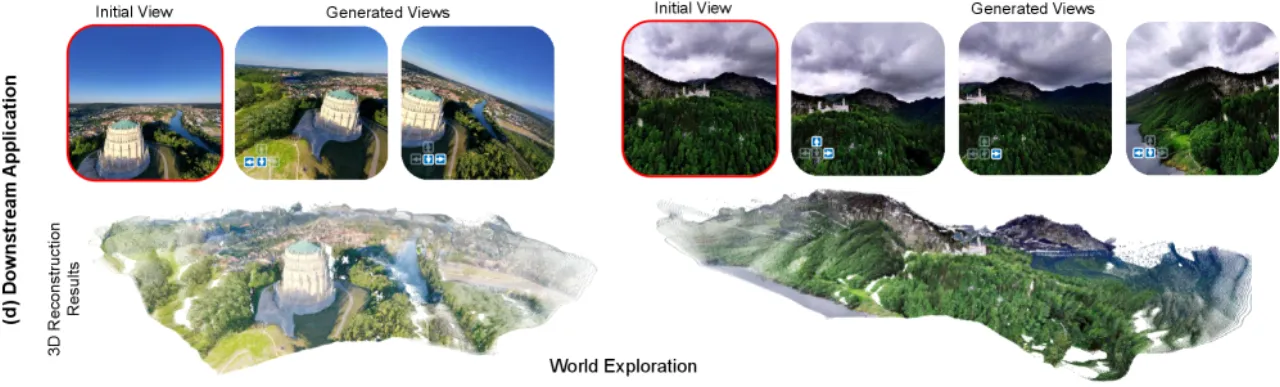
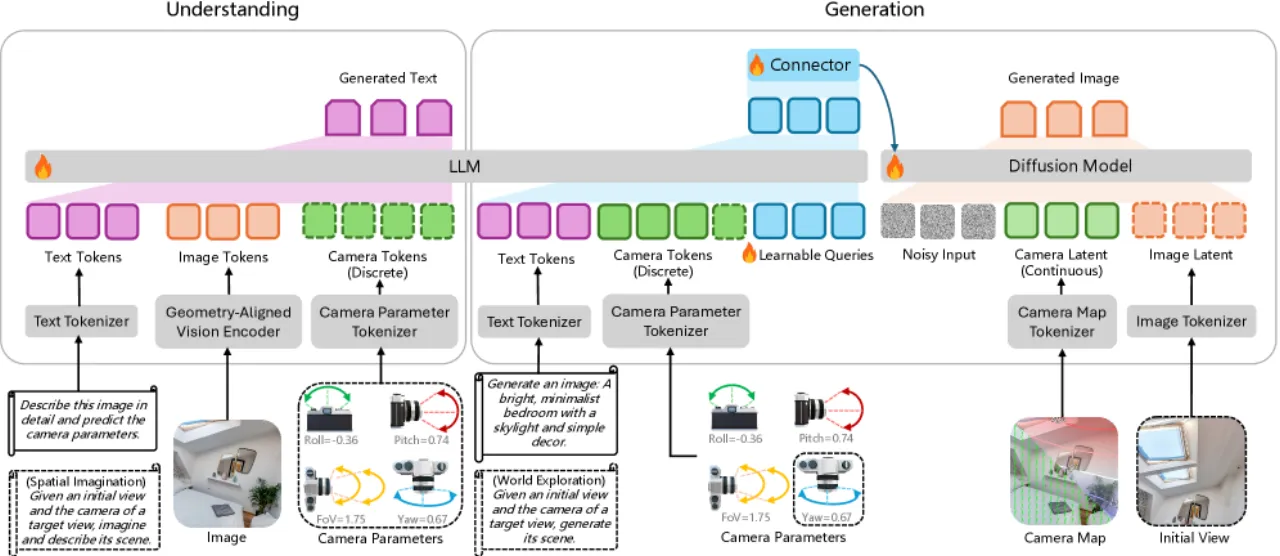
相机几何理解(从图像估计 roll/pitch/FoV 等参数)与可控图像生成(按指定视角合成场景)是空间智能的两大基石,但长期以来被作为独立任务研究。现有方法将相机参数当作辅助数字标签,忽视了其本身作为模态的语义价值,导致模型在追求语义对齐时忽略精确的空间约束,性能次优。
"Camera-centric understanding and generation are two cornerstones of spatial intelligence, yet they are typically studied in isolation."

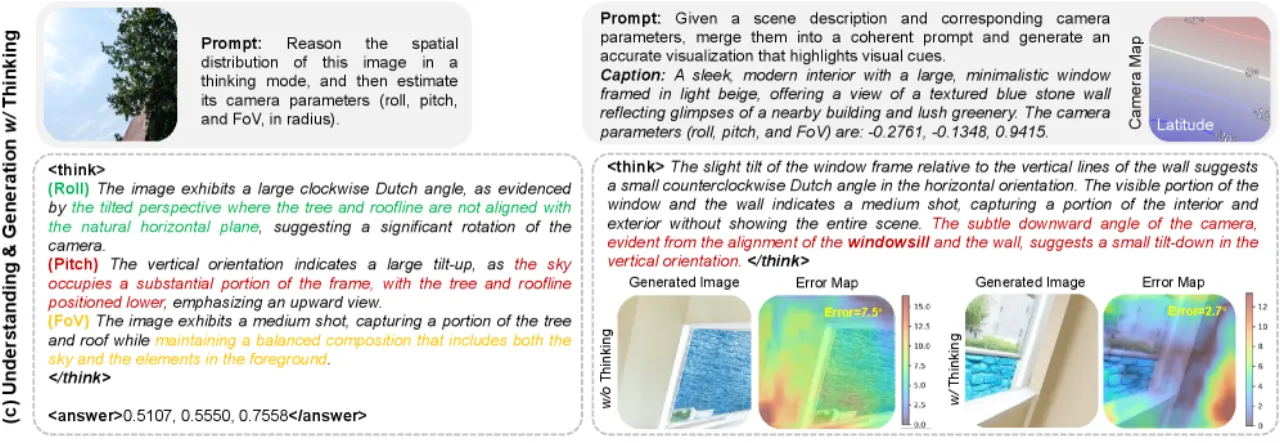
核心挑战在于模态鸿沟:相机参数是抽象的数值(如 FoV=72°),缺乏视觉语义,而大型多模态模型(LMM)的训练目标是语义对齐。现有做法要么独立训练专用的几何估计器,要么将参数硬编码为辅助标签,均未能充分利用 LMM 的视觉-语言推理能力。Puffin 提出将相机参数视为一种语言,用摄影专业术语(如 "tilt-up"、"Dutch angle"、"close-up")作为中间表示,弥合数值几何与高层语义之间的差距。
0.32°Roll 误差 (MegaDepth)
vs. GeoCalib 0.36°
vs. GeoCalib 0.36°
1.08°Pitch 误差 (MegaDepth)
vs. GeoCalib 1.94°
vs. GeoCalib 1.94°
2.42°FoV 误差 (MegaDepth)
vs. GeoCalib 4.46°
vs. GeoCalib 4.46°
11.94°Up Vector 误差(生成评估)
vs. PreciseCam 18.66°
vs. PreciseCam 18.66°