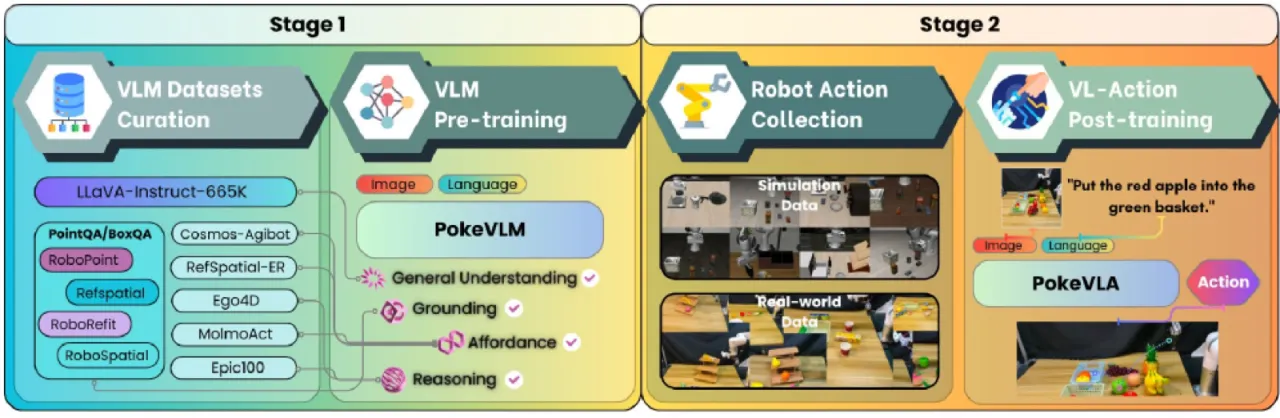
02 方法 · MethodPokeVLA 采用两阶段训练范式:第一阶段在大规模具身多模态数据集上预训练出 PokeVLM;第二阶段通过目标感知语义分割(Goal-Aware Segmentation) 与几何对齐(Geometry Alignment) 将操作相关的表征注入到动作头中。
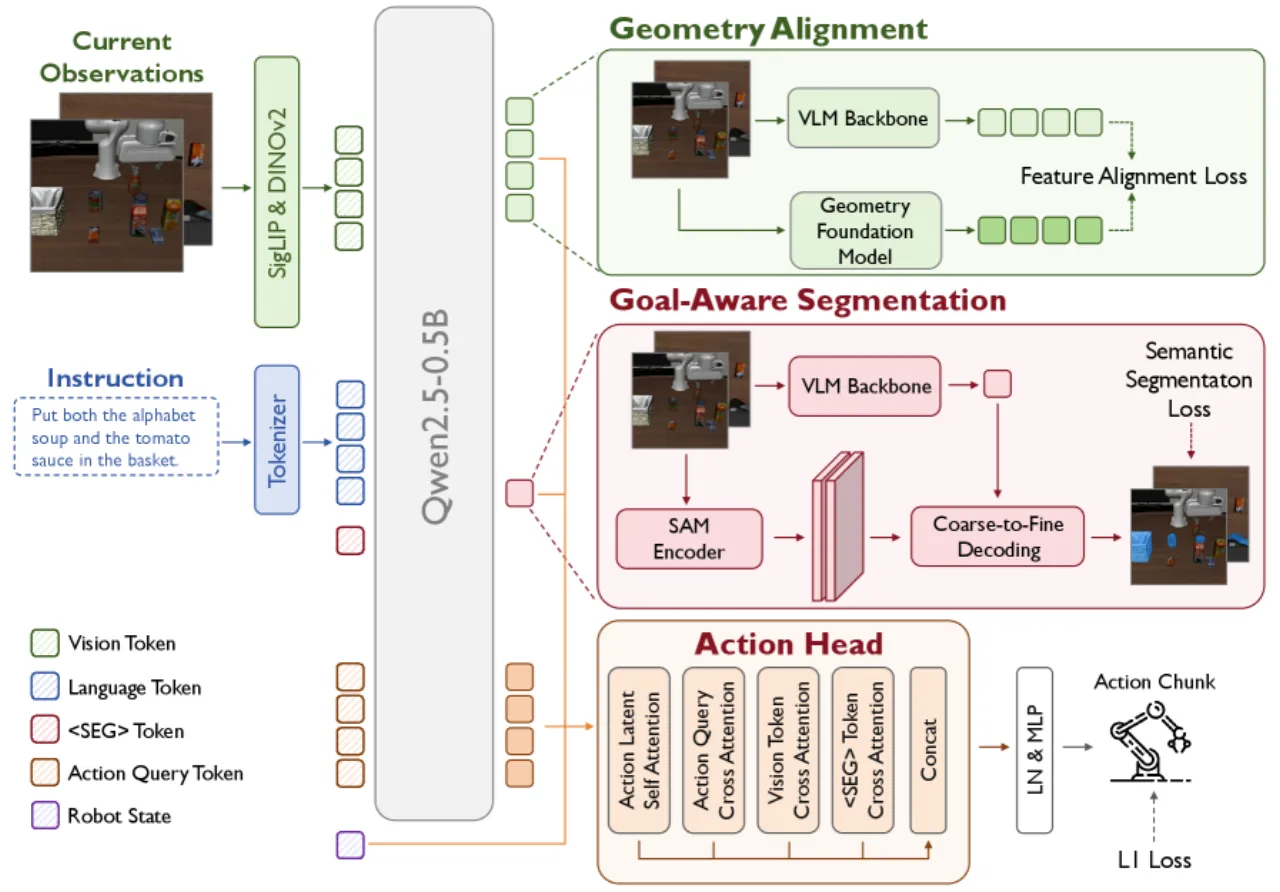
图 2:PokeVLA 系统总览。左图为第一阶段 VLM 预训练(PokeVLM),右图为第二阶段 VL-Action 后训练,引入目标感知分割与几何对齐,并以 cross-attention 动作头生成动作序列。
第一阶段:PokeVLM 预训练
以 Prismatic-VLM 为骨架,语言模型选用 Qwen2.5-0.5B ,视觉编码器为 SigLIP(语义)+ DinoV2(空间感知)双组件,通过 MLP projector 桥接视觉与语言空间。预训练数据集共约 2.4M 条 ,覆盖四类具身任务:
General Understanding :665K 条,来自 LLaVA-Instruct-665KSpatial Grounding :694K 条,来自 RoboPoint、RefSpatial、RoboRefit、RoboSpatialAffordance Learning :553K 条,来自 HOVA(Ego4D、Epic100)和 MolmoActEmbodied Reasoning :511K 条,来自 RefSpatial 和 Cosmos-Reason1-SFT
训练配置:AdamW 优化器,学习率 2e-5,batch size 128(8 卡 × 4 per-GPU × 4 梯度累积),线性 warmup(3% steps)+ cosine decay,共训练 2 个 epoch。
图 3:VL-Action 后训练架构细节。左侧为目标感知分割的 coarse-to-fine 解码流程(基于 SAM),右侧为几何对齐模块(VGGT 特征蒸馏,仅训练时使用),中间的 cross-attention 动作头融合视觉隐状态、<SEG> embedding 与机器人状态。
目标感知语义分割(Goal-Aware Segmentation)
借鉴 LISA 的设计,在语言模型中引入特殊 token <SEG>,其 embedding 整合了场景上下文与目标物体细节。解码采用 coarse-to-fine 两步范式:
Coarse Decoding :将 <SEG> embedding 通过 SAM prompt encoder,获得 sparse/dense embeddings,经粗粒度 mask decoder 得到初步掩码;Fine-Grained Decoding :以粗掩码 logits 作为 mask prompt 输入,结合 <SEG> embedding 进一步细化预测。
分割损失为 focal loss 与 KL divergence 之和:Lseg = λfocal FOCAL(M̂,M) + λKLD KLD(M̂,M) ,其中 λfocal = λKLD = 1。多视角一致性通过跨视角共享 <SEG> embedding 保证,使模型对操作目标形成稳定的跨视角表征。
图 4:在长时序任务中,目标感知分割在不同视角之间保持一致性,确保 <SEG> embedding 始终指向正确的操作目标。
几何对齐(Geometry Alignment)
利用 VGGT (视觉几何基础模型)在训练阶段提取多视角图像的几何特征,通过余弦相似度损失将语言模型视觉 token 的隐状态对齐到 VGGT 特征空间:
Lgeo = (1/VN) ∑[1 − cos(P(hv ), fgeo )]
几何对齐仅在训练阶段使用 VGGT,推理时无额外开销 。轻量级 projector 负责维度对齐。整体训练目标为:
L = Laction + λseg Lseg + λgeo Lgeo
其中 λseg = 0.2,λgeo = 0.4。
动作头(Action Head)
采用含 L 个 transformer 层的 cross-attention 动作头,依次对动作 latent 进行:自注意力 → 与 query embedding 及机器人状态做 cross-attention → 与视觉隐状态做 cross-attention → 与 <SEG> embedding 做 cross-attention,最终通过 LayerNorm + MLP 输出动作 chunk:
"attl = [SA(atl ), CA(atl ,[hq ,MLP(st )]), CA(atl ,hv ), CA(atl ,hseg )]"