01 动机
机器人操作长期依赖任务专用模型或精确感知管线,难以泛化到"野外"(in-the-wild)环境。作者指出,人类能仅凭一眼和对动作的构想就预测三维世界如何响应——这种能力对机器人操作至关重要。现有方法要么依赖对象先验、要么局限于二维外观,无法捕获精细接触动力学。
"Humans anticipate, from a glance and a contemplated action of their bodies, how the 3D world will respond, a capability equally vital for robotic manipulation."
"Unification for scaling: represent state and action in the same modality of 3D physical space."

~2M预训练轨迹数
~500h覆盖数据时长
0.1s单步推理时延
1B最大模型参数量
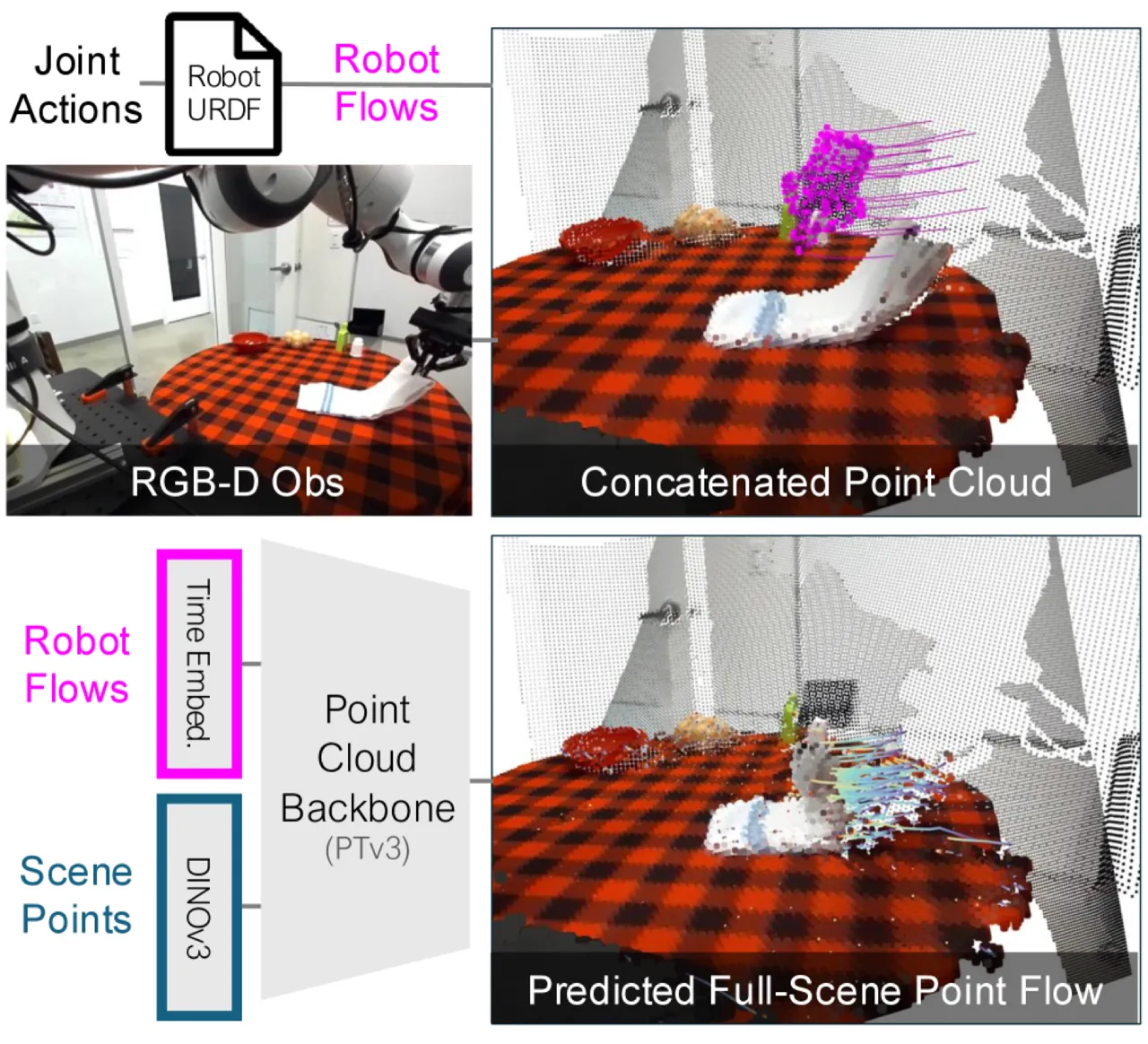
核心洞察:将场景点云(scene point flow)与机器人点流(robot point flow)统一于同一三维物理空间,摆脱对象级标注和具身形态假设,实现跨机器人、跨任务的规模化学习——类比语言模型中的 next-token prediction,但面向三维空间与时间上的交互。