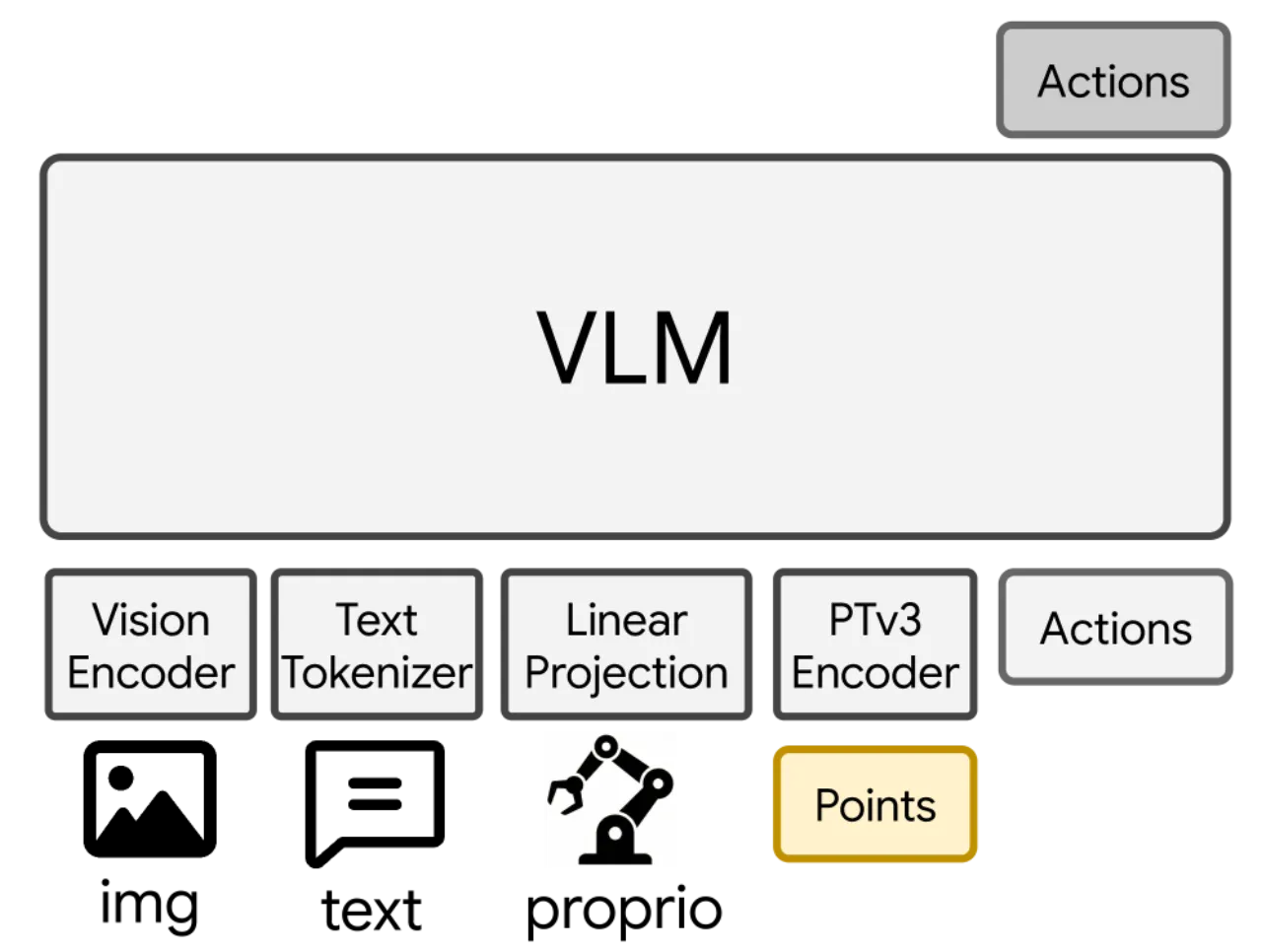
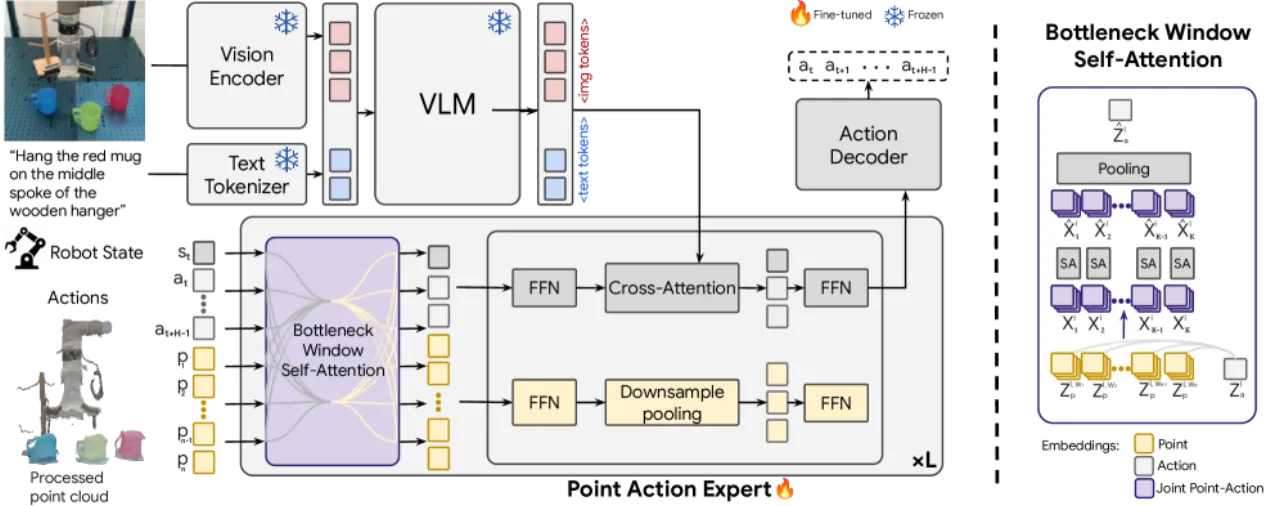
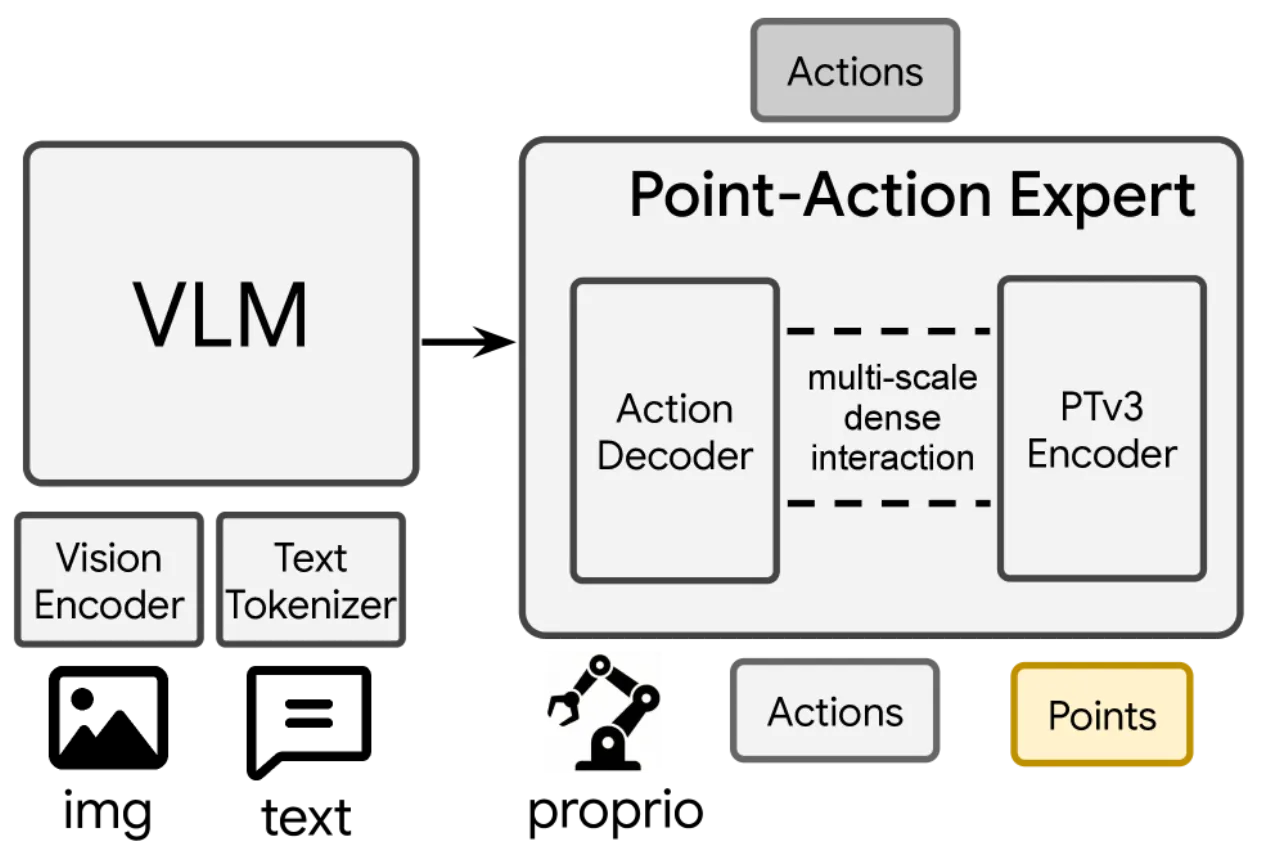
"Models lack reactive recovery from execution errors or perturbations."——模型无法从执行错误或外界扰动中主动恢复,一旦中间动作出现偏差,后续动作难以纠正。作者将改进失败恢复能力列为未来工作方向。
工具媒介操作能力不足(stated)
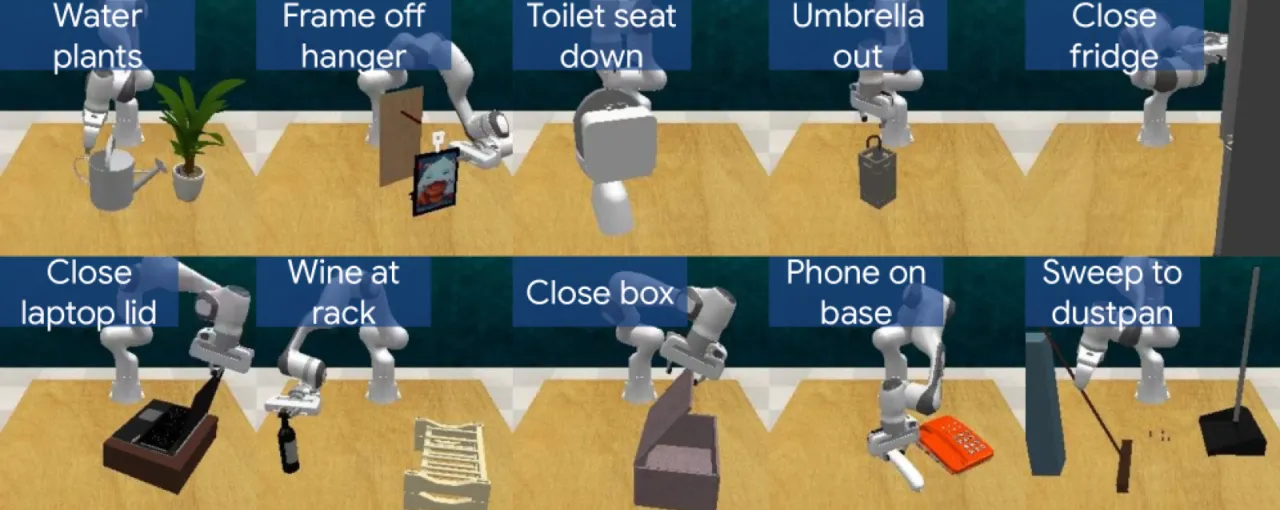
当操作需要通过工具间接施力时(如扫把→簸箕的接触几何),模型难以建模精确的接触力学,对应 Sweep to dustpan(59% 成功率)任务表现偏弱。
点云噪声鲁棒性(推断/inferred)
作者在结论中提到"improving robustness under noisy point observations"为未来工作方向,暗示当前模型对传感器噪声(如透明/反光物体的深度缺失)较为敏感。UR5 实验中关闭透明抽屉的案例(Close Drawer)也间接体现了这一挑战,但通过 2D 视觉特征部分弥补了点云缺陷。
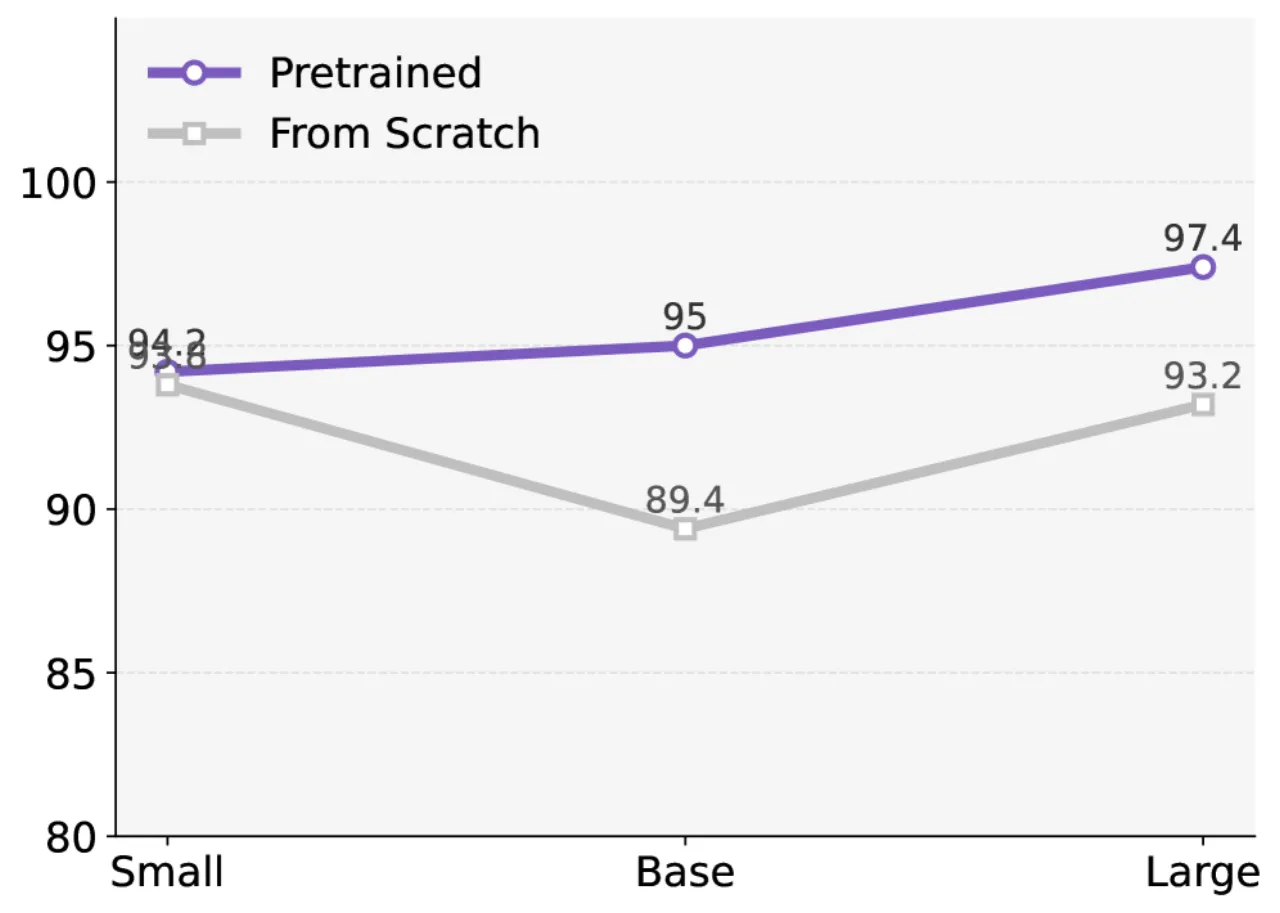
点云预训练数据与机器人场景不匹配(stated + inferred)
当前使用的 PTv3 预训练权重来自建筑级场景数据,与桌面操作任务存在显著域差异(domain gap)。作者明确将"scaling point-based pretraining on robot datasets"列为重要的未来工作,以提升特征迁移效果,尤其对大容量模型优化帮助更大。