02 方法
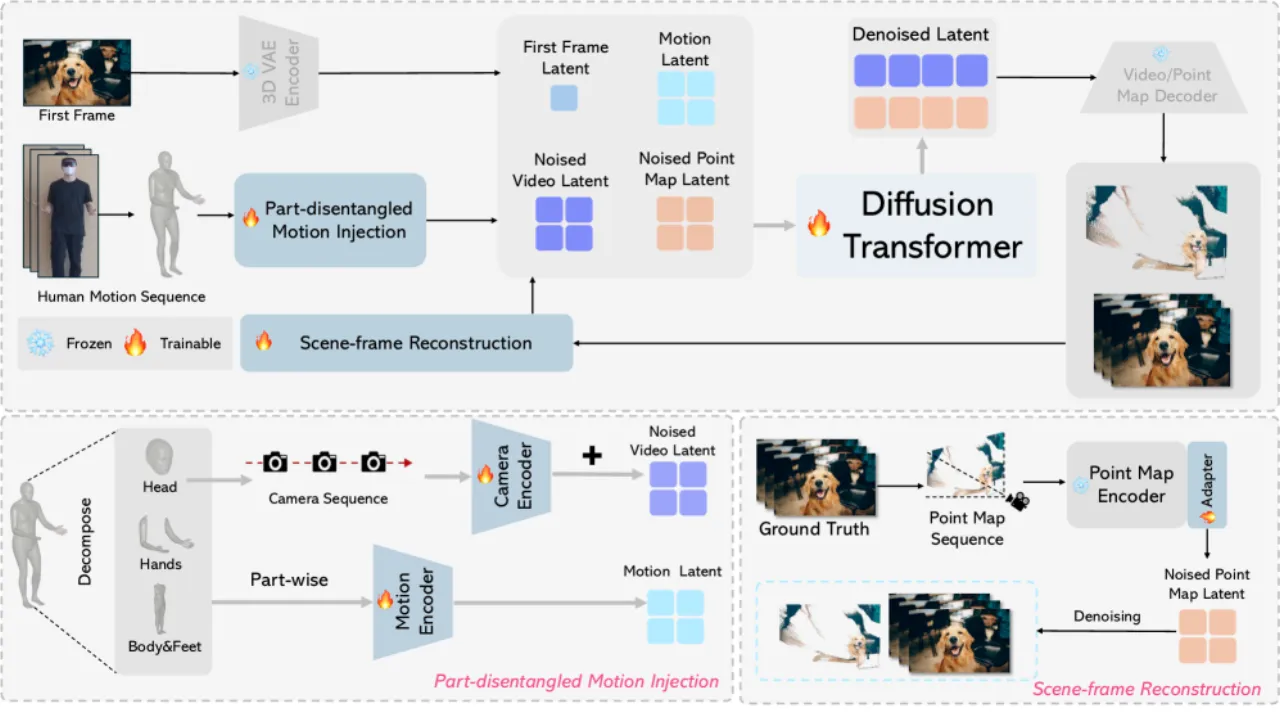
PlayerOne 以 Wanx2.1(1.3B Diffusion Transformer)为基座,引入两个核心模块:
Part-Disentangled Motion Injection (PMI) 用于精确的分部位运动控制,
Scene-Frame Reconstruction (SR) 用于保持长视频中的场景一致性。
训练采用粗到精的两阶段策略,先在大规模 egocentric 文本-视频对上做 LoRA 预训练,再冻结 LoRA 仅微调最后六个 block。
图2:PlayerOne 整体框架。
输入图像转为视觉 token;人体运动分解为身体/脚(66维)、头部(3维)、双手(各45维)三组,
分别经独立 3D 卷积编码器处理。头部参数经 Rodrigues 公式转为相机旋转序列,注入 noised 视频 latent。
场景帧重建(SR)通过 CUT3R 渲染 point map 序列,与视频 latent 联合去噪,推理时无需 point map。
Part-Disentangled Motion Injection (PMI)
传统方案将全身运动拼接为单一向量("entangled")送入 ControlNet,导致不同部位(尤其是头部视角与手部动作)互相干扰。
PMI 将运动分为三组:
Body/Feet(66维): 专用 3D 卷积编码器,捕捉步伐与全身姿态变化。Head(3维旋转): 通过 Rodrigues 公式转换为相机旋转序列,额外注入 noised 视频 latent,精确控制第一人称视角转动。Hands(各45维): 独立编码器处理双手精细动作,用于物体交互场景。
消融实验表明,PMI 相比 ControlNet 基线将 MPJPE 从 241.73 降至 156.76,FVD 从 287.52 降至 245.72。
Scene-Frame Reconstruction (SR)
为避免长视频中场景漂移,SR 在训练时用 CUT3R 从真值视频渲染 point map 序列,
通过带 5层 3D 卷积 adapter 的专用编码器与视频 latent 联合去噪,
迫使模型在时序上维持三维场景一致性。推理阶段不需要 point map 输入。
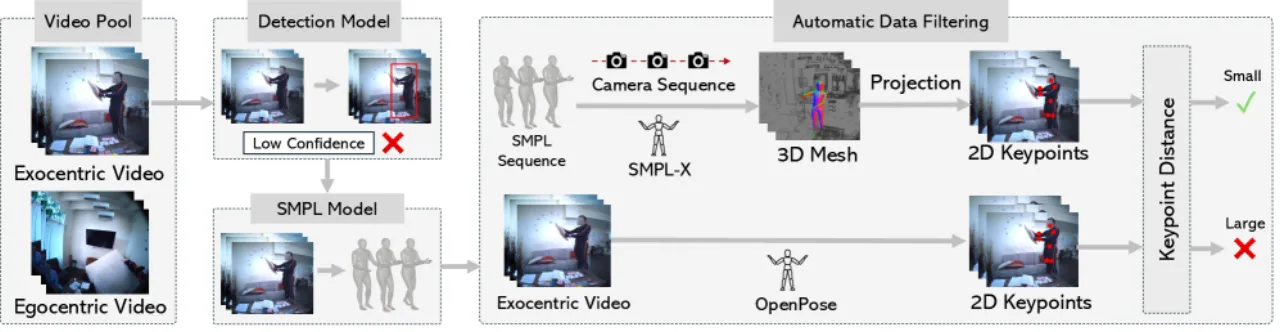
图3:自动数据集构建流水线。
利用 SAM2 检测、SMPLest-X 提取 SMPL 参数,过滤重投影误差最高的 10% 样本,
从大规模 egocentric-exocentric 配对数据集中构建高质量运动-视频配对,
最终用于 PMI 模块的精调训练。
Coarse-to-Fine 训练策略
阶段一(粗粒度): 在 Egovid-5M 等大规模 egocentric 文本-视频对上做 LoRA(rank 128,weight 4)预训练,
使模型具备第一人称视觉先验。阶段二(细粒度): 冻结 LoRA,仅对最后六个 Transformer block 在精标的运动-视频配对数据上微调,
建立精确的运动-视觉对应关系。