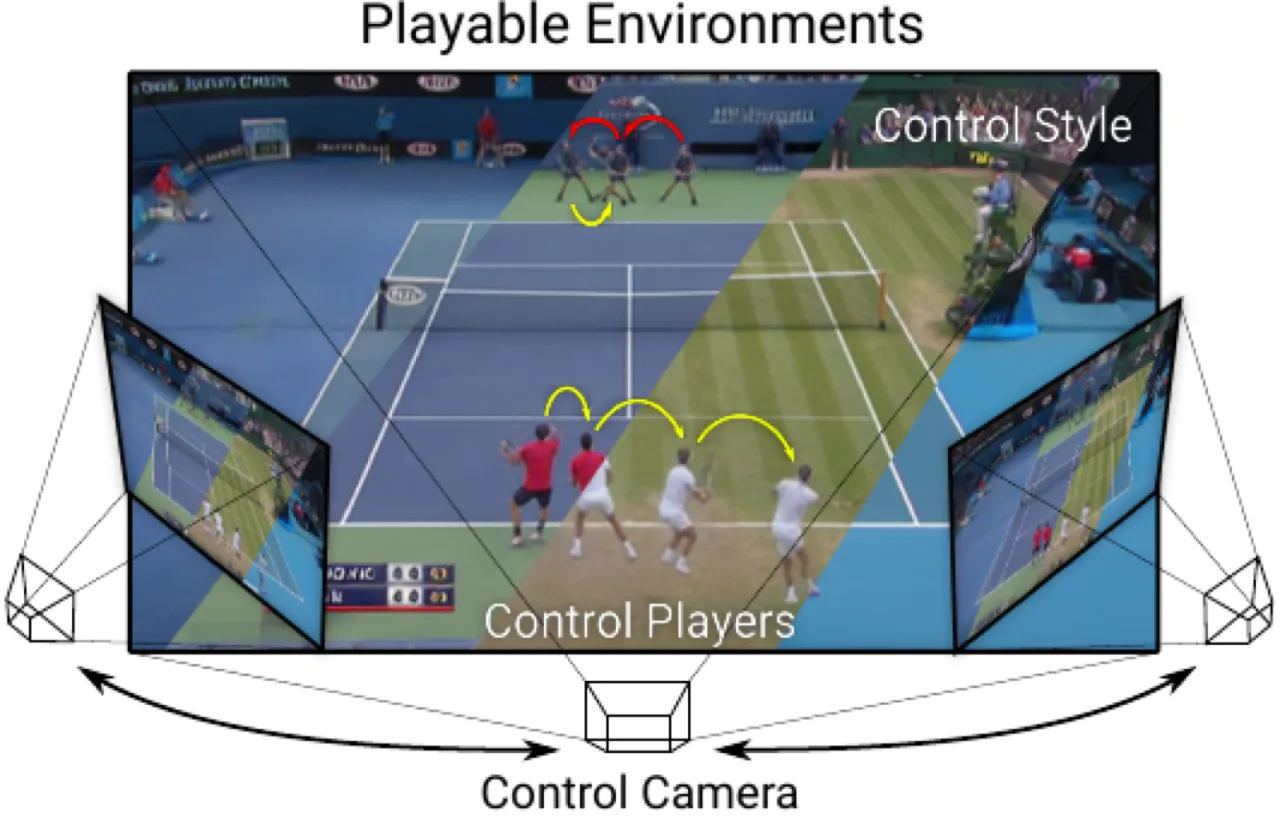
02 方法
框架采用编码器-解码器结构,核心由两个模块构成:Synthesis Module (合成模块)负责从场景状态渲染图像;Action Module (动作模块)负责在状态空间中学习并预测用户动作。训练分两阶段进行,全程仅依赖重建损失,无需人工动作标注。
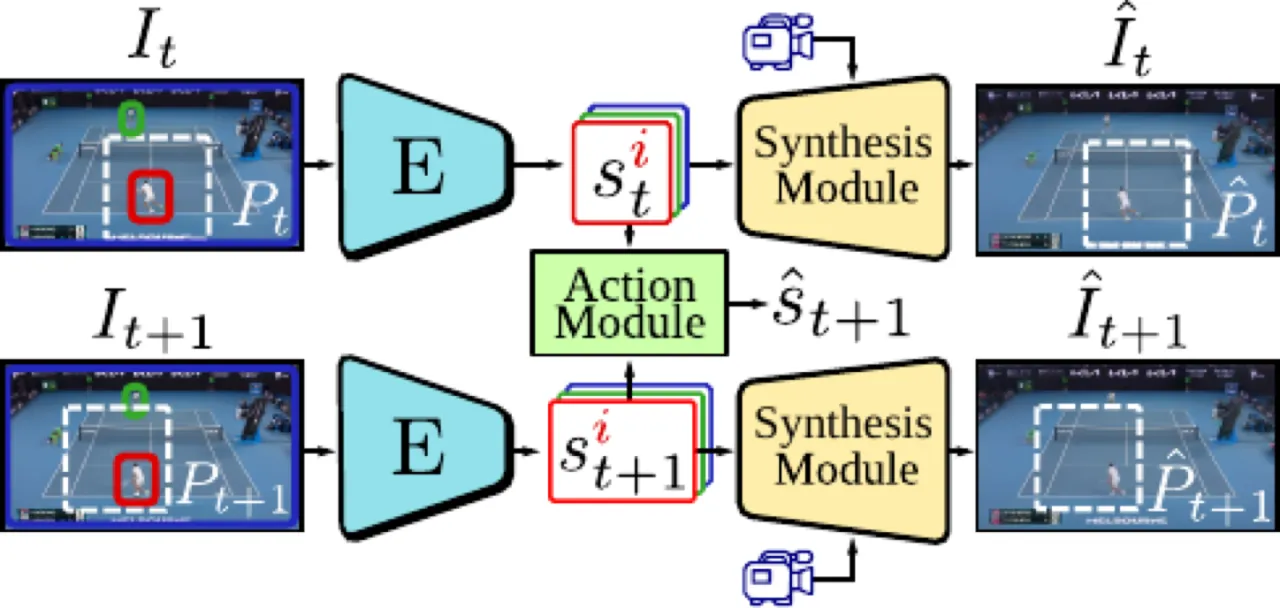
框架总览。 编码器 E 为场景中每个对象提取环境状态(位置 x 、风格 w 、姿态 π );合成模块(NeRF-like)从状态与相机参数重建帧;动作模块在瓶颈层学习离散动作标签,推理时由用户指定动作以控制生成内容。(图源:论文 Figure 2)
Synthesis Module:组合式非刚性 NeRF
合成模块以 NeRF 为基础架构,实现相机控制 ⑵。每个对象由独立的 MLP V 参数化的 feature field 建模,各 field 以对象位置为中心、受 bounding volume 约束,从而支持多对象建模 ⑶。
为处理可变形对象(如人体)⑷,引入 ray bending network B :给定姿态描述子 π 与采样点 x_p ,通过 B 将其映射到正则空间坐标 x̃_p = x_p + B(x_p, π_t) ,从而在正则空间中编码对象几何。
为建模外观多样性 ⑸,受 AdaIN 启发,在 V 的 feature prediction branch 中嵌入风格调制层:h̃_t = γ(w_t) h_t + β(w_t) ,其中 γ, β 为可训练线性层,风格码 w_t 只调制颜色特征而不影响几何。
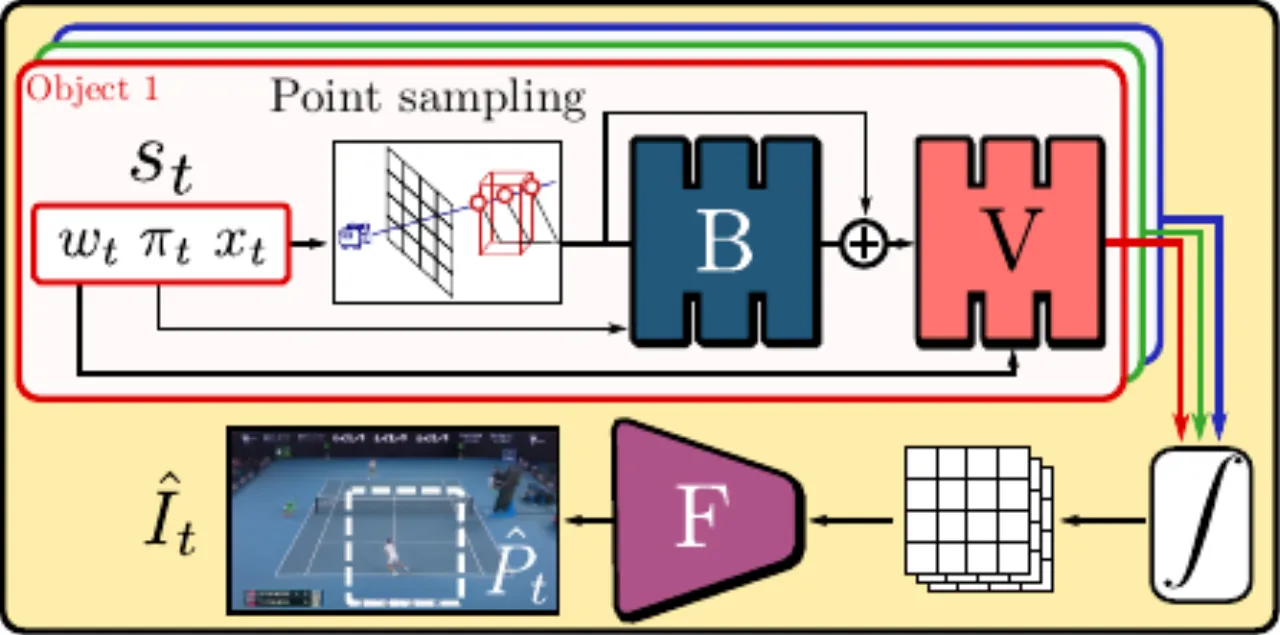
合成模块。 两步流程:首先用带 bending network B 的非刚性 NeRF 生成特征图;再将特征图送入 ConvNet F (Feature Renderer)输出最终帧图像。Feature Renderer 通过跨像素建模弥补定标噪声导致的模糊,同时因在低分辨率采样 NeRF 光线而显著降低显存消耗。(图源:论文 Figure 3)
Action Module:状态空间离散动作学习
动作模块由 Action Network A 和 Dynamics Network R 组成。A 给定相邻状态 (s_t, s_{t+1}) ,输出离散动作 a_t ∈ {1,...,K} 与 action variability embedding v_t ;R (LSTM)以 (s_t, a_t, v_t) 为输入自回归预测下一状态。
为使动作与相机朝向一致(符合游戏直觉),Dynamics Network 预测相机坐标系下的位移 Δ ,再通过旋转矩阵 M 转换:x̂_{t+1} = x_t + MΔ 。
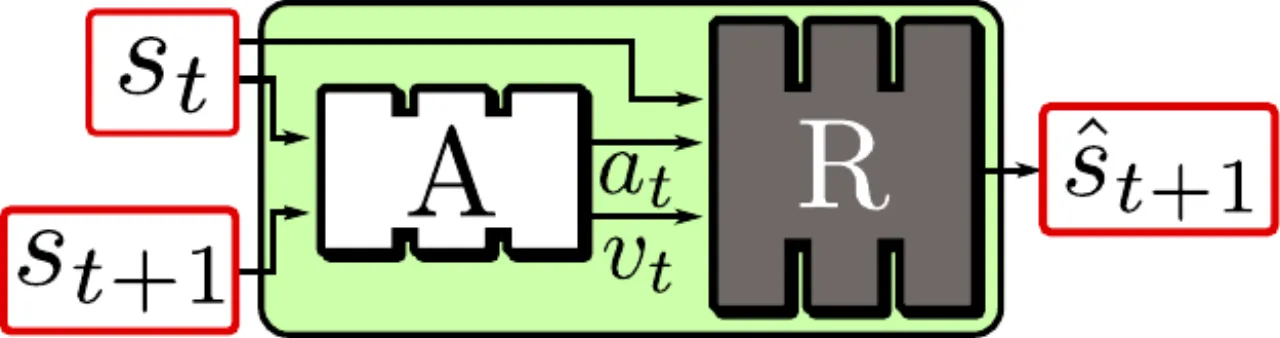
动作模块。 Action Network A 从相邻状态推断离散动作标签 a_t 及 variability v_t ;Dynamics Network R 结合 s_t, a_t, v_t 预测 s_{t+1} 。推理时由用户指定 a_t ,v_t 置零。(图源:论文 Figure 4)
训练策略
阶段一(合成模块) :用感知损失(VGG perceptual loss)+ L2 像素重建损失训练编码器与合成模块。为避免风格 w 和姿态 π 解耦失败,在每个序列的时间维度上打乱 w 的顺序再送入合成模块。
阶段二(动作模块) :联合优化四项损失——重建损失 L_rec 、信息论动作学习损失 L_act (最大化互信息)、Δ-MSE 软损失 L_Δ (同类动作应对应相似位移)、以及对抗 Temporal Discriminator D (判别真实/重建状态序列,促使动作生成真实肢体动作)。