Danijar Hafner · Timothy Lillicrap · Ian Fischer · Ruben Villegas · David Ha · Honglak Lee · James Davidson(Google Brain / DeepMind / University of Michigan)
"Planning using learned models offers several benefits over model-free reinforcement learning. First, model-based planning can be more data efficient because it leverages a richer training signal and does not rely on propagating rewards through Bellman backups."
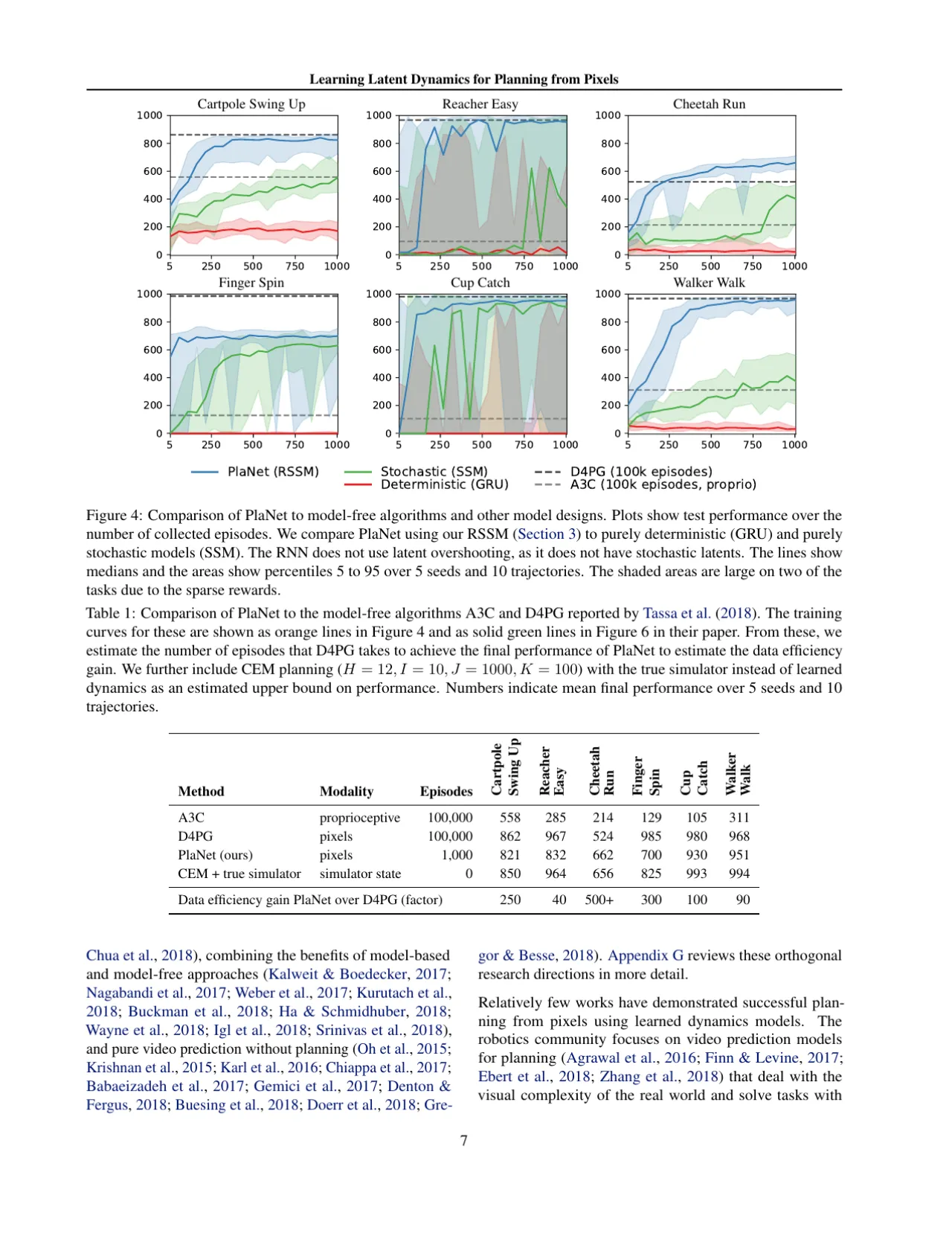
Figure 1(论文原图):PlaNet 所测试的六种 DeepMind Control Suite 任务——Cartpole Swingup、Reacher Easy、Cheetah Run、Finger Spin、Cup Catch、Walker Walk。图像分辨率降采样至 64×64 像素后作为唯一观测,不提供物理状态。Cartpole/Finger Spin 仅有稀疏奖励;Cheetah/Walker 存在接触动力学。
6连续控制任务(DeepMind Control Suite)
50×比 D4PG 少的样本(Finger Spin 任务,100K episodes)
64×64像素输入分辨率(唯一观测)
1 GPUNvidia V100,10–20 小时训练
02 方法(Method)
PlaNet 的核心是 Recurrent State Space Model(RSSM)——一个同时包含确定性(deterministic)和随机性(stochastic)转移分量的隐状态空间模型。通过变分自编码器(VAE)框架从像素中学习该模型,再利用 Cross-Entropy Method(CEM)在隐空间中规划动作序列,无需任何策略网络。
Latent overshooting 的核心思路:"If we could train our model to make perfect one-step predictions, it would also make perfect multi-step predictions, so this would not be a problem. However, when using a model with limited capacity and restricted distributional family, training the model only on one-step predictions until convergence does in general not coincide with the model that is best at multi-step predictions."
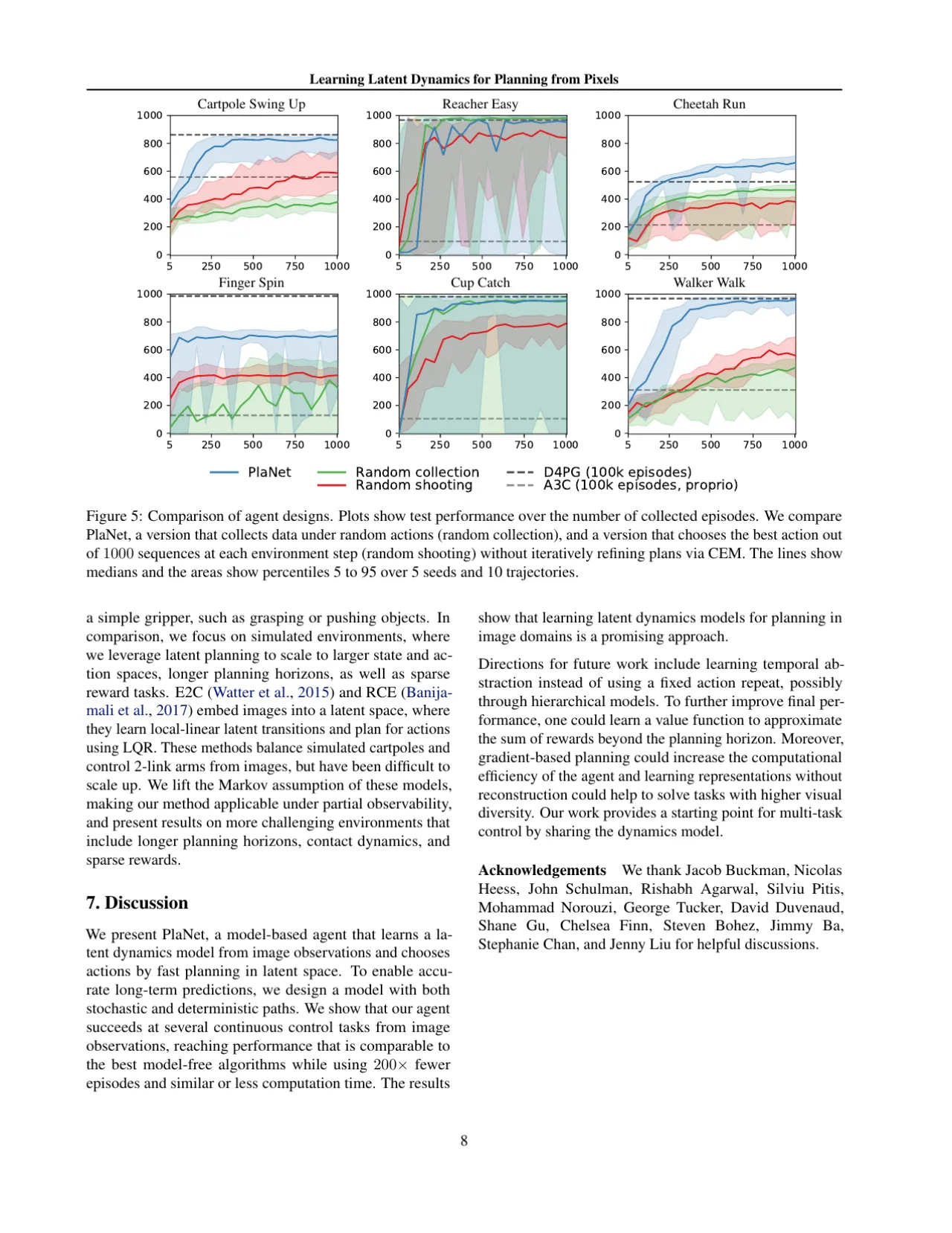
在线规划:CEM(Cross-Entropy Method)
测试时,agent 利用学习到的 RSSM 进行 MPC(Model Predictive Control):在隐空间中以 CEM 采样并评估 H 步候选动作序列(默认 H=12,迭代 10 次,每次 1000 个候选),选取期望累积奖励最高的序列执行第一步动作,再重新规划。整个过程不需要任何策略网络或价值函数——模型是唯一"知识"来源。
03 实验(Experiments)
在 DeepMind Control Suite 的 6 个连续控制任务上,对比 A3C(模型无关、像素输入)、D4PG(模型无关、像素输入,proprioceptive 版本作为上界)、带真实动态的 CEM(oracle),以及纯随机随机策略。所有 pixel-based 方法使用相同 64×64 三阶段下采样图像。指标为最终性能的 median ± IQR(5 seeds × 10 trajectories)。