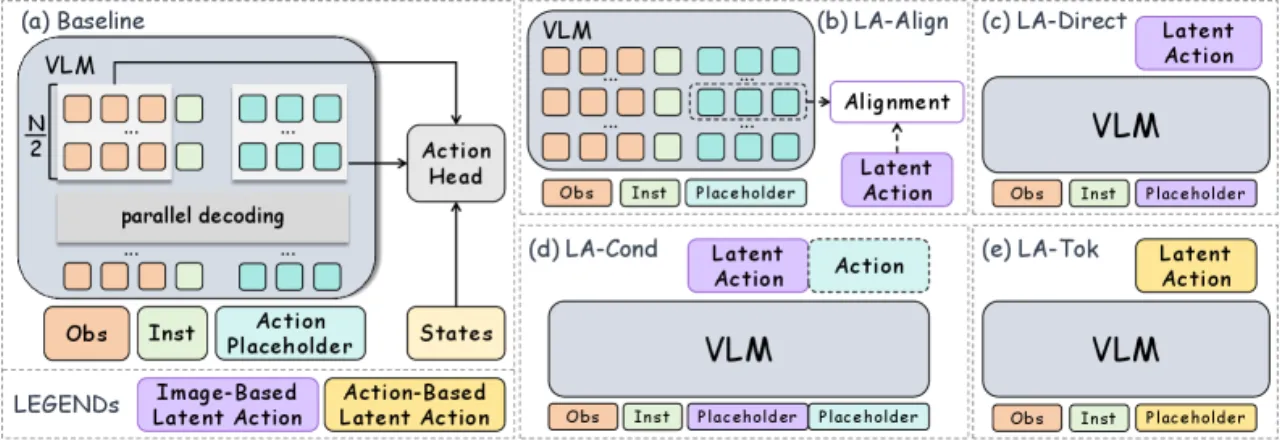
01 动机
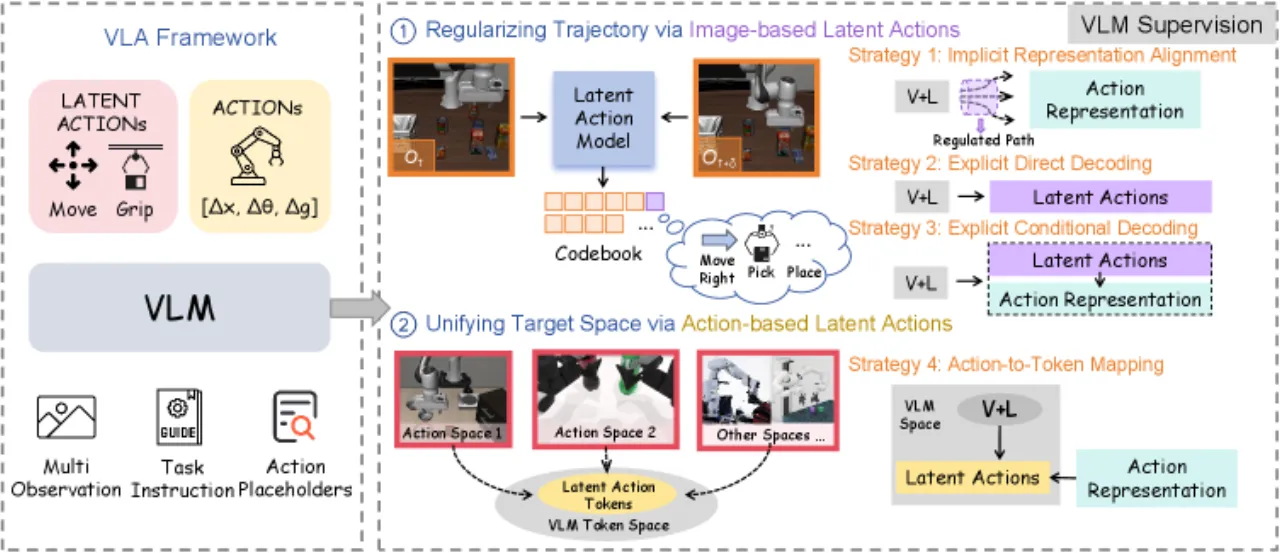
视觉-语言-动作模型(VLA)近年兴起,但异构动作空间(不同机器人、不同任务的动作格式各异)给策略学习带来挑战。Latent action 作为中间表示,可将视觉/动作信息压缩为统一的离散 token,从而桥接 VLM 和机器人控制。然而,latent action 的设计空间复杂——应从图像侧提取还是动作侧提取?如何与 VLM 集成?哪种监督形式最有效?这些问题缺乏系统研究。
"We investigate how different latent action supervision choices affect VLA policy learning under a unified baseline."
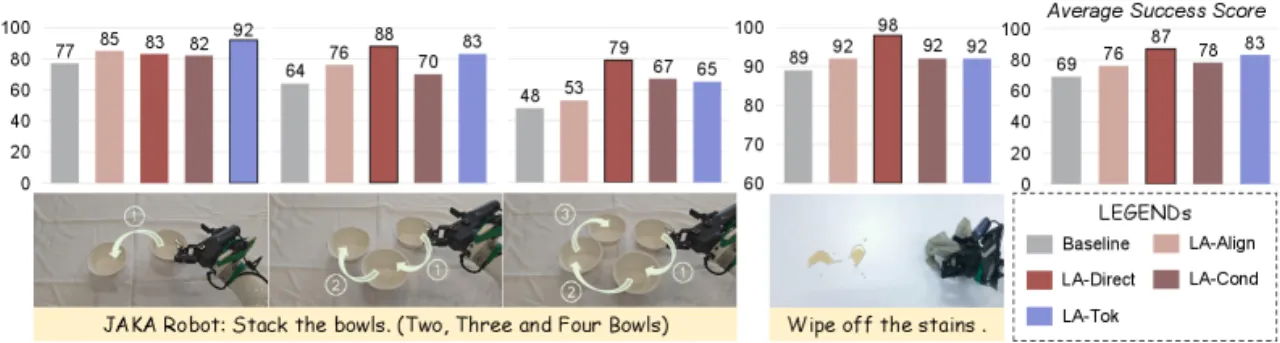
+10.8%LA-Direct 在 LIBERO-Long 上的提升(85.8% → 96.6%)
+17.5%LA-Tok 在 RoboTwin 2.0 平均成功率提升
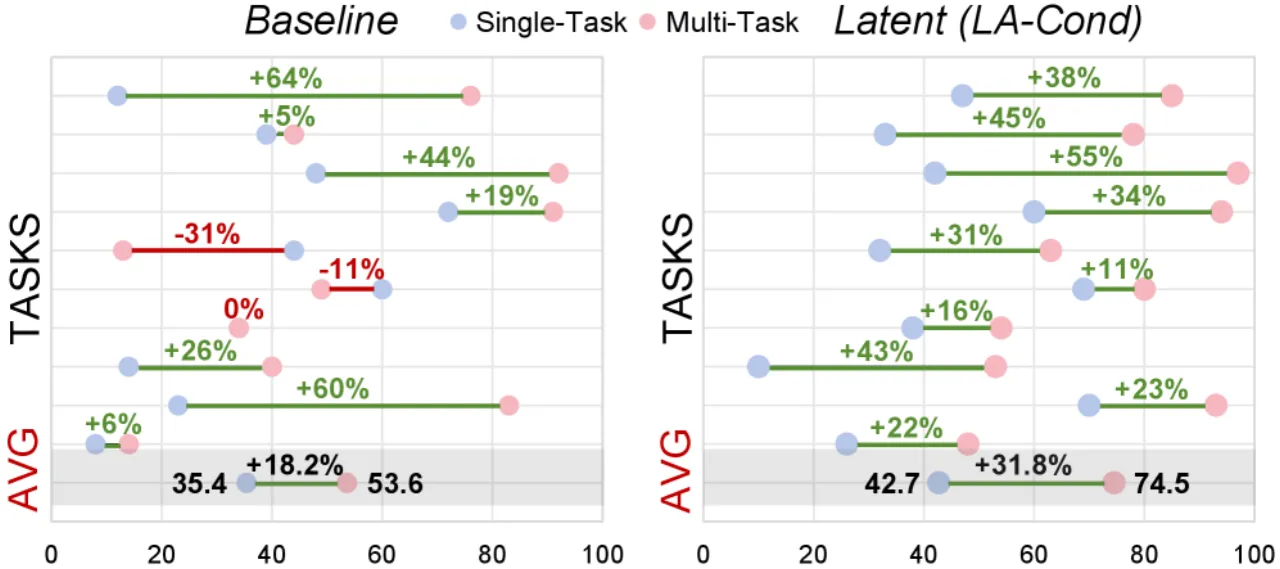
+20.9%LA-Cond 多任务联合训练消除负迁移的提升
4×四种系统策略在统一 baseline 下全面对比