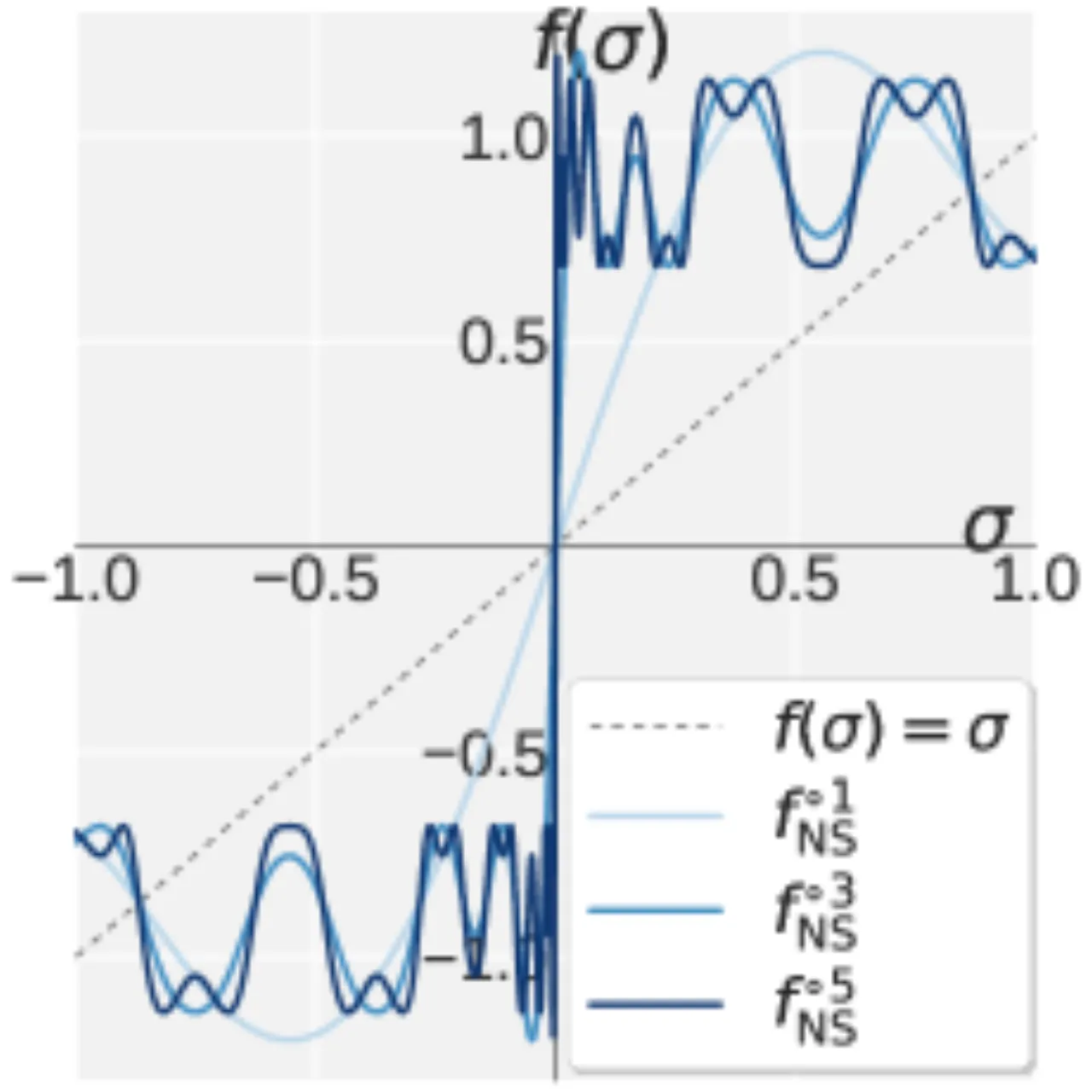
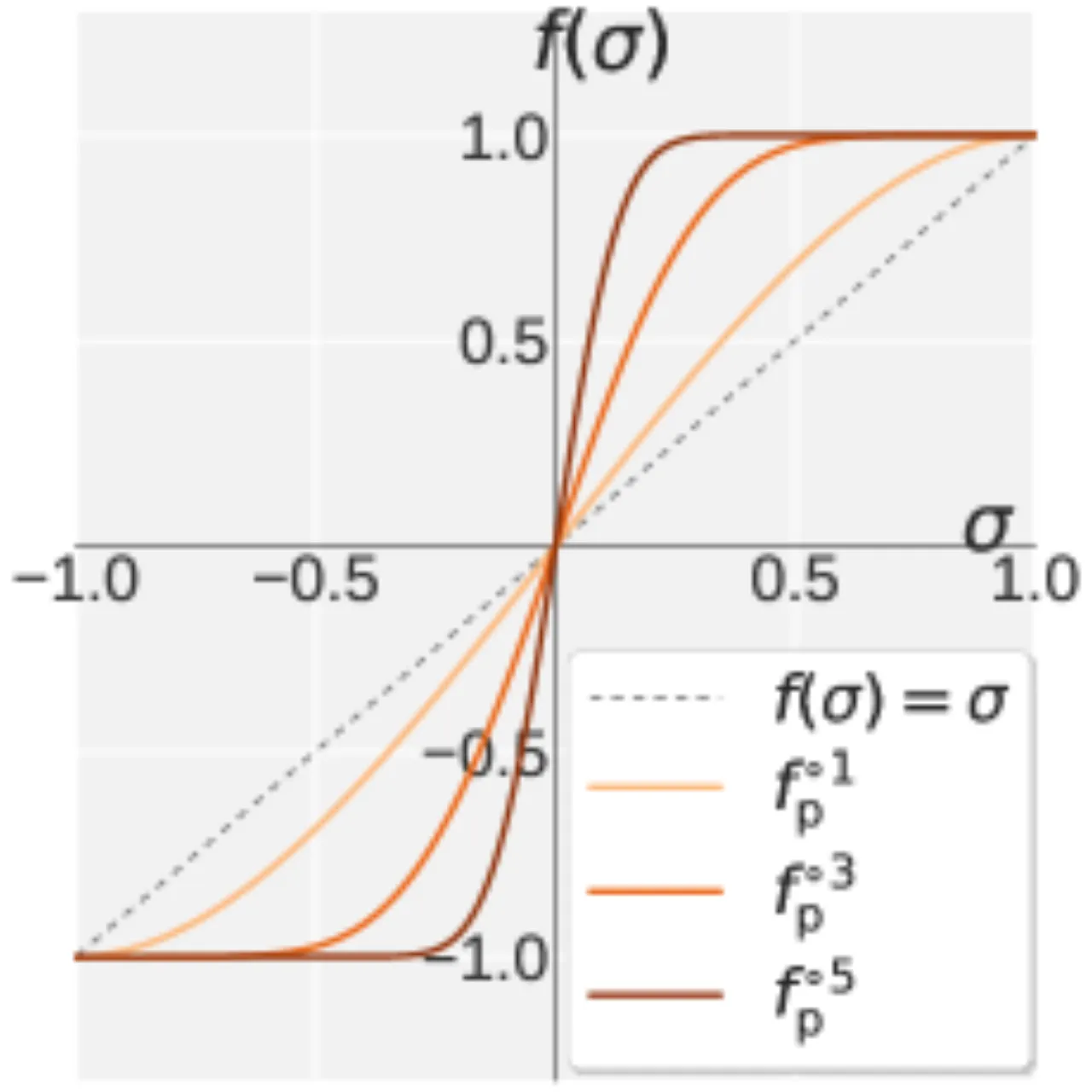
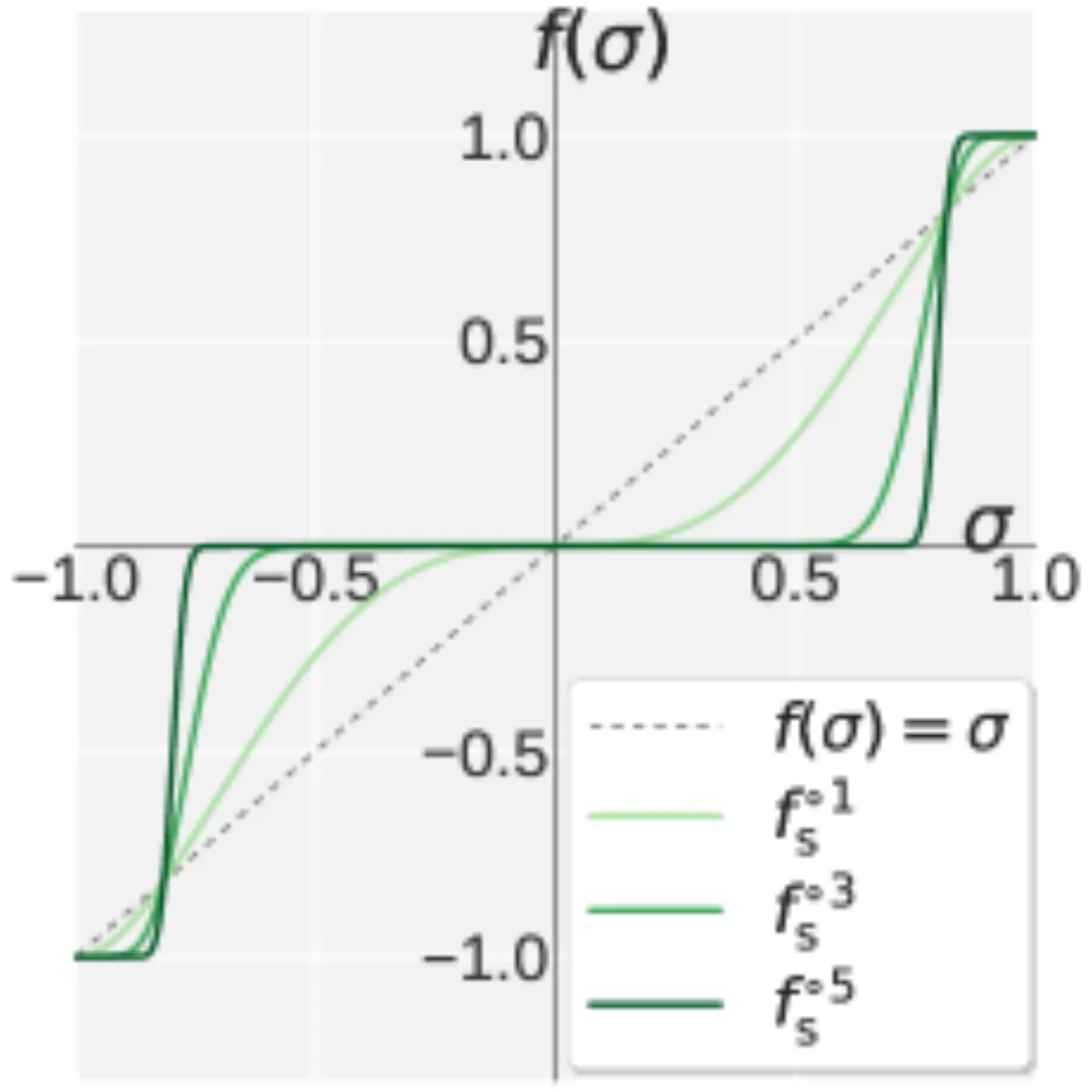
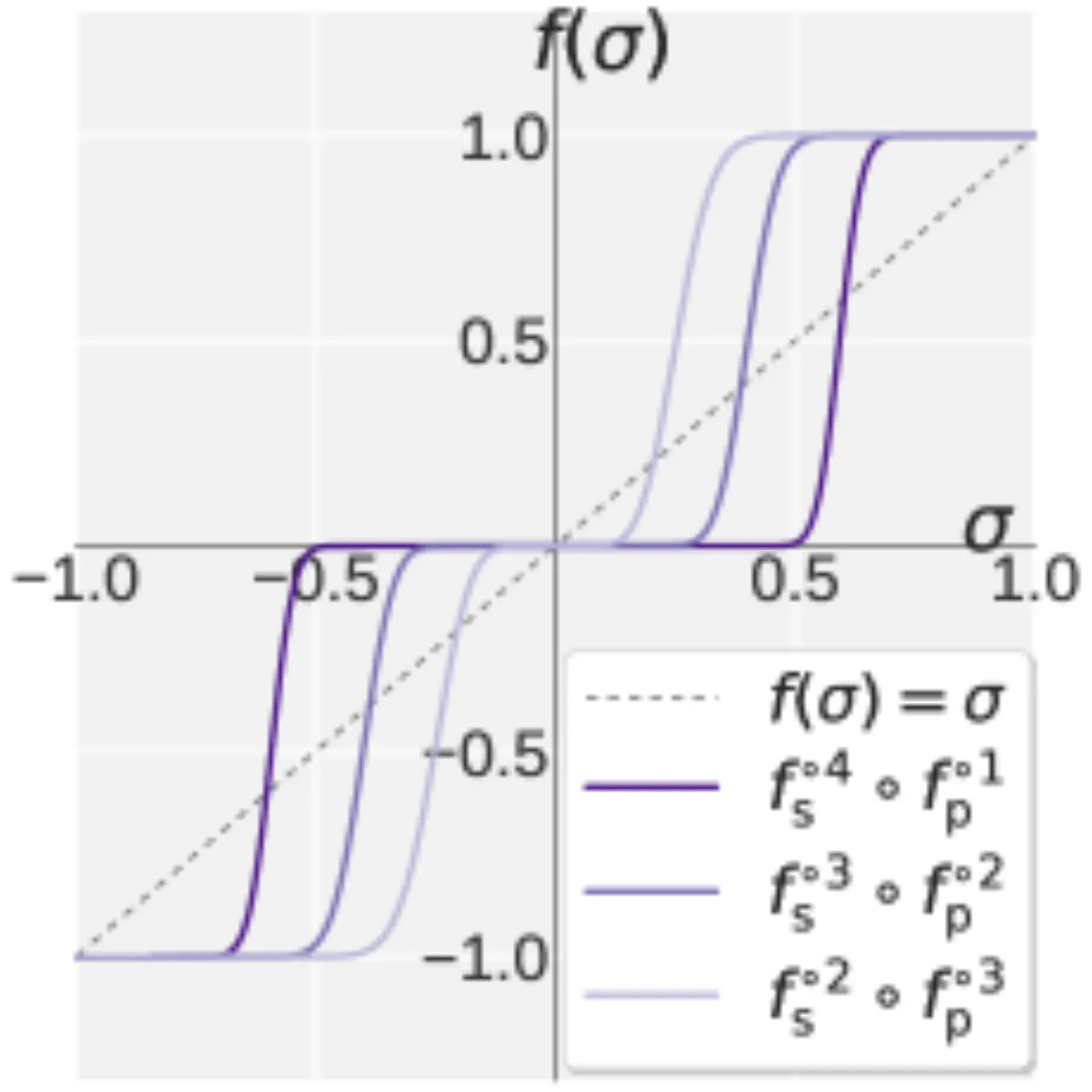
01 动机 · Motivation
Muon 是近期兴起的高效矩阵优化器,其核心操作是对动量矩阵做"矩阵符号"(matrix sign,即将所有奇异值统一归一到 1)。这一设计在 LLM 预训练中促进了各向同性探索(isotropic exploration),效果显著。然而,当 Muon 被移植到两种日益重要的后训练场景时,均匀谱白化暴露出根本性的失效模式:
VLA 跨模态训练的低秩梯度问题
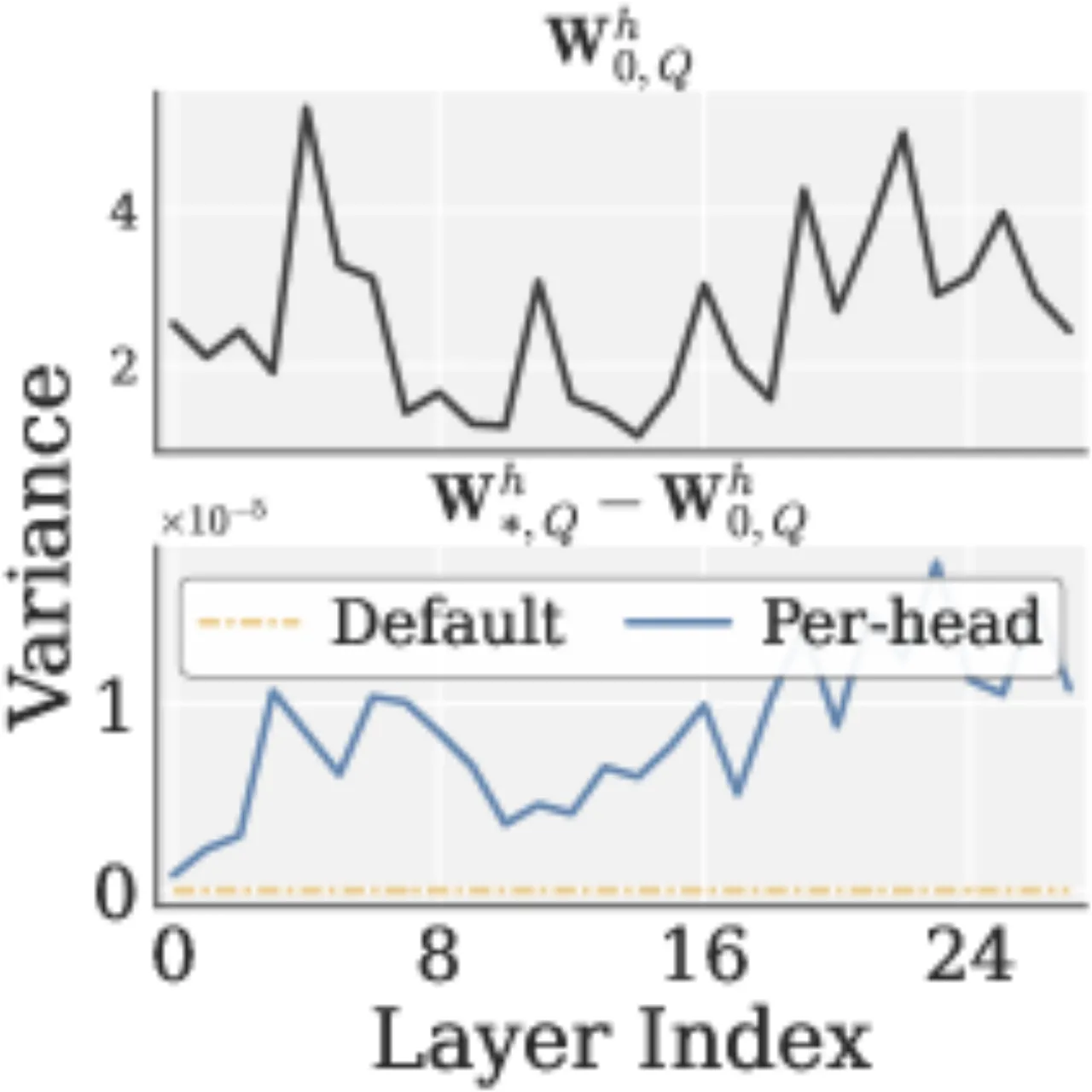
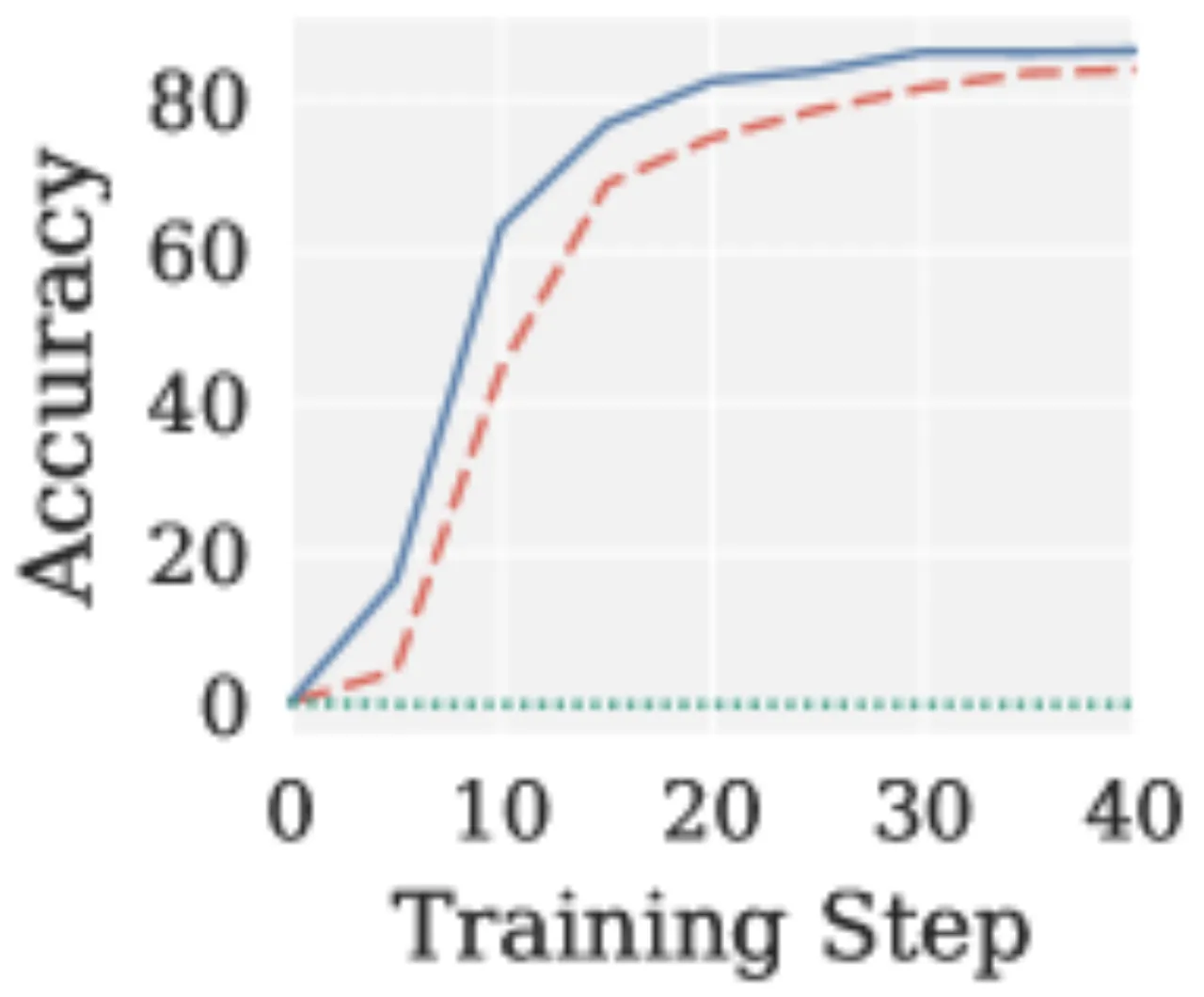
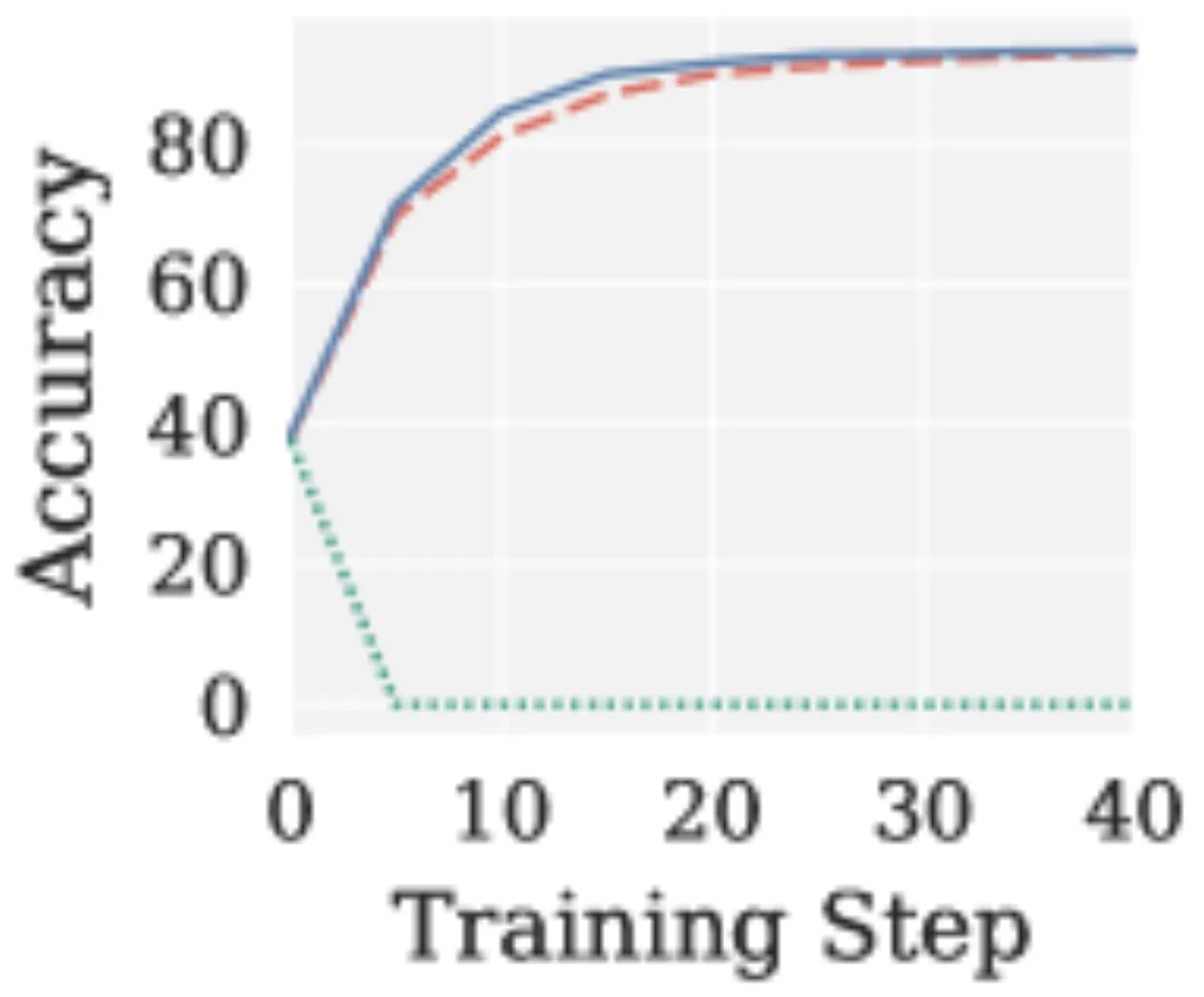
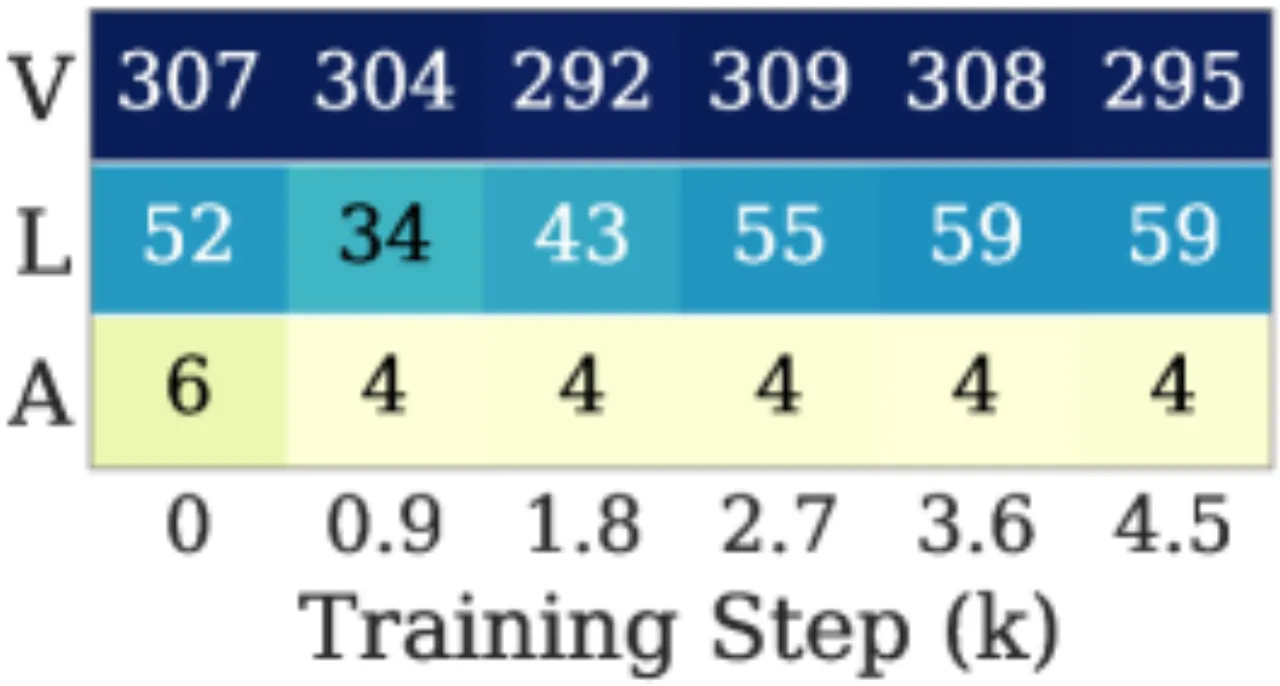
在视觉-语言-动作(VLA)微调中,动作模块(action module)的梯度本质上是低秩的(low-rank)。Muon 的均匀白化会将这些低秩噪声方向同等放大,导致有效秩(effective rank, erank)在训练过程中急剧下降,最终降低动作预测精度。
RLVR 低信噪比梯度的模型崩塌
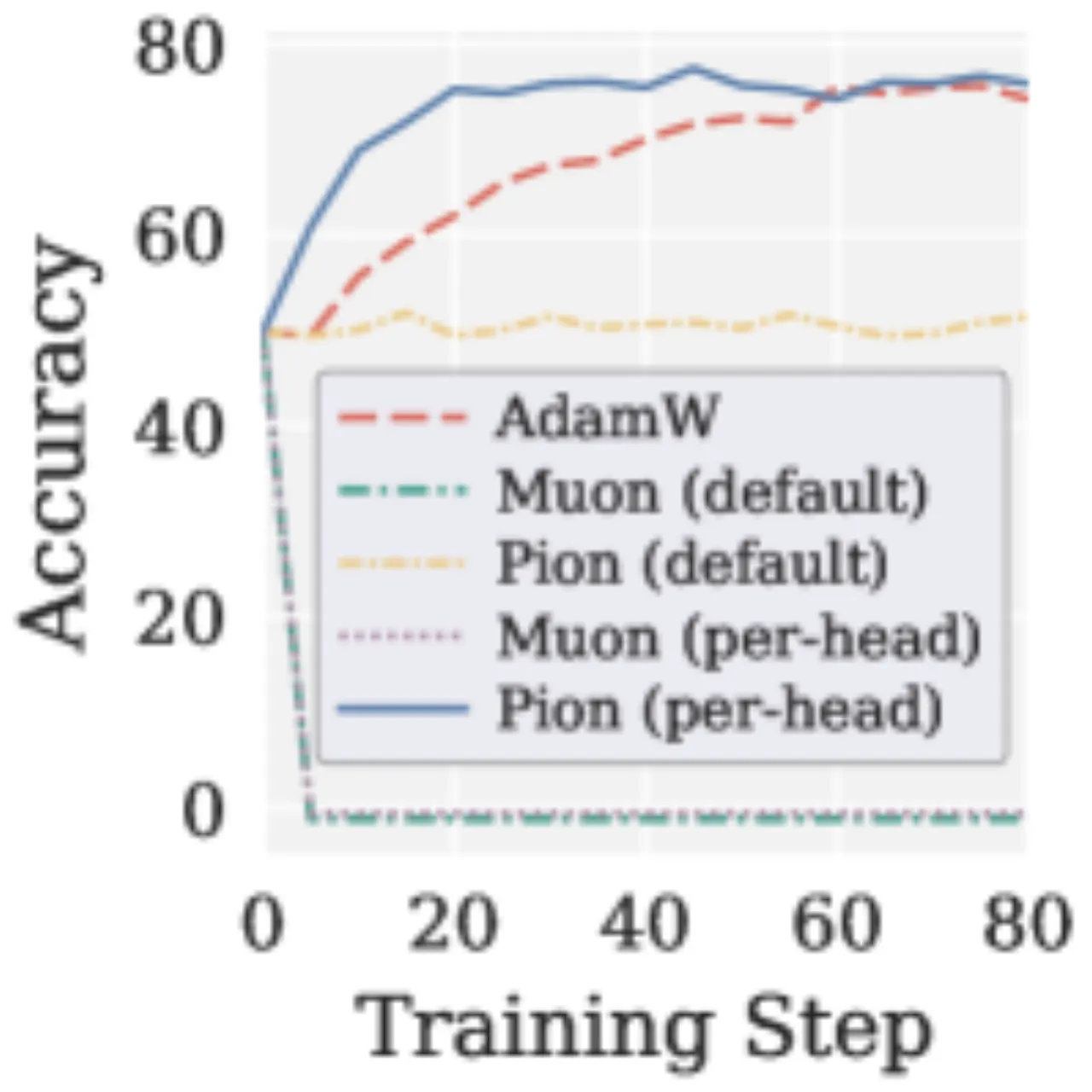
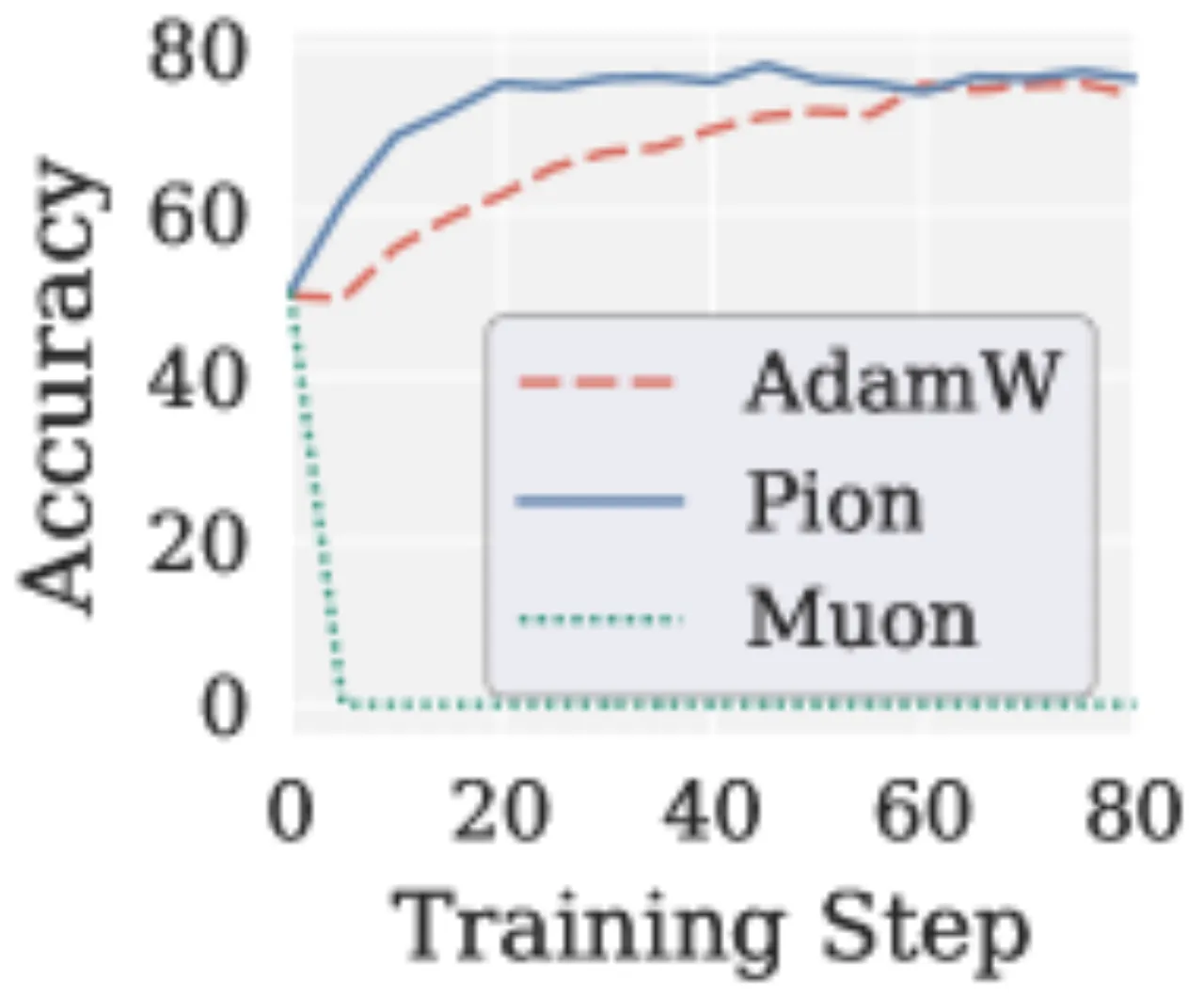
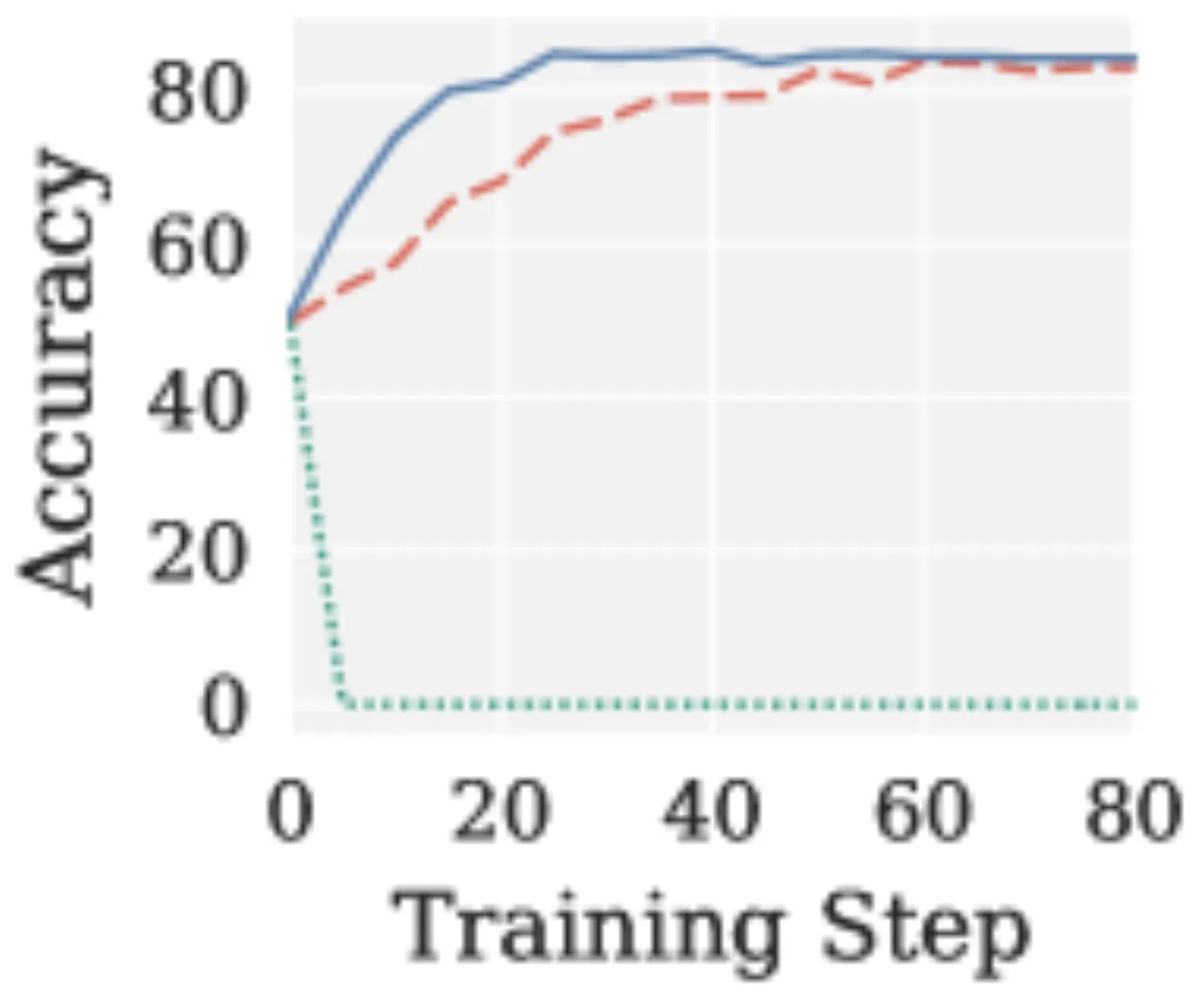
在带可验证奖励的强化学习(RLVR)中,梯度信噪比(SNR)远低于 SFT 场景(接近 1:1)。Muon 均匀放大所有奇异方向,将噪声信号等同对待,导致模型精度从初始检查点骤降至接近零:"accuracy drops from the initial checkpoint and converges to near zero."
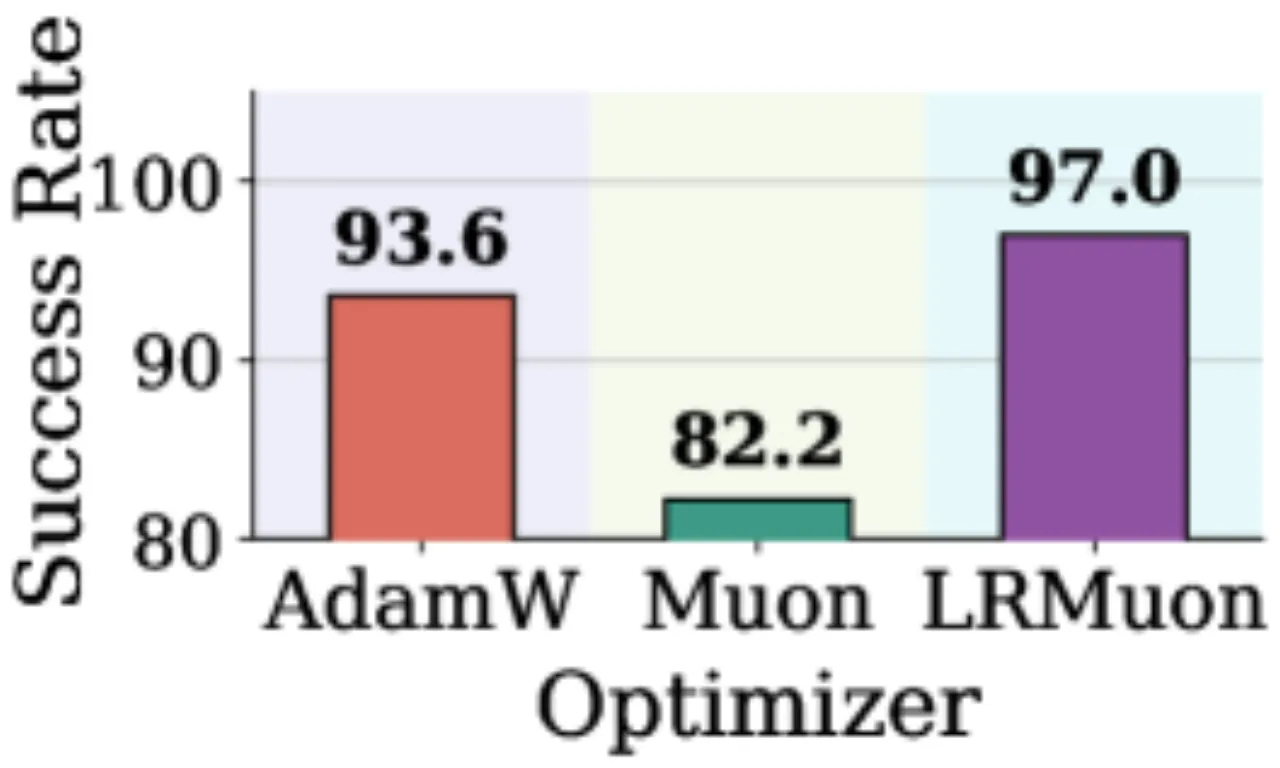
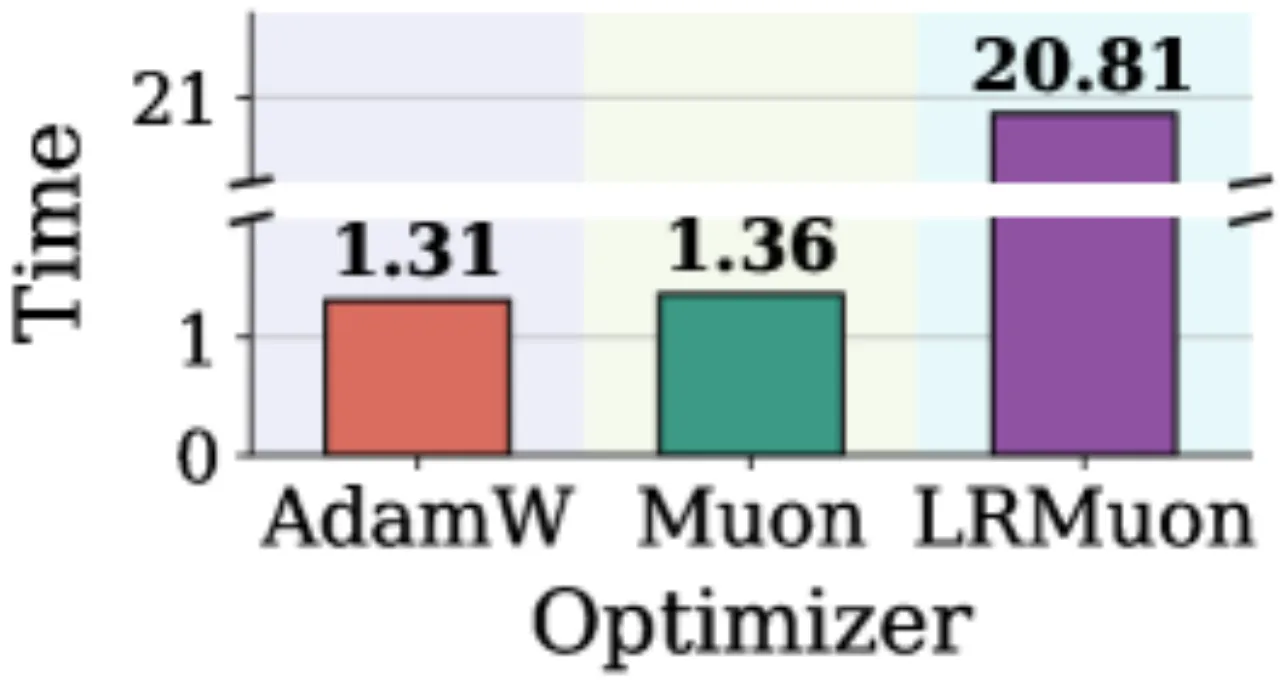
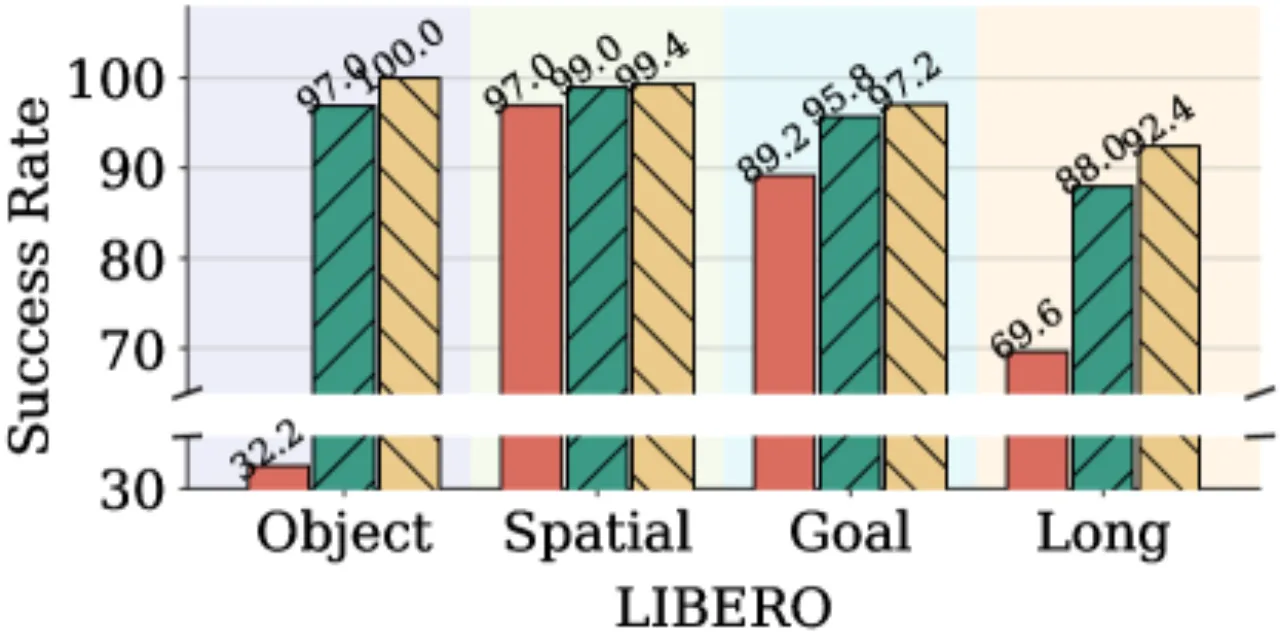
100%Pion — LIBERO Object 成功率
97.0%Muon — LIBERO Object 成功率
32.2%AdamW — LIBERO Object 成功率
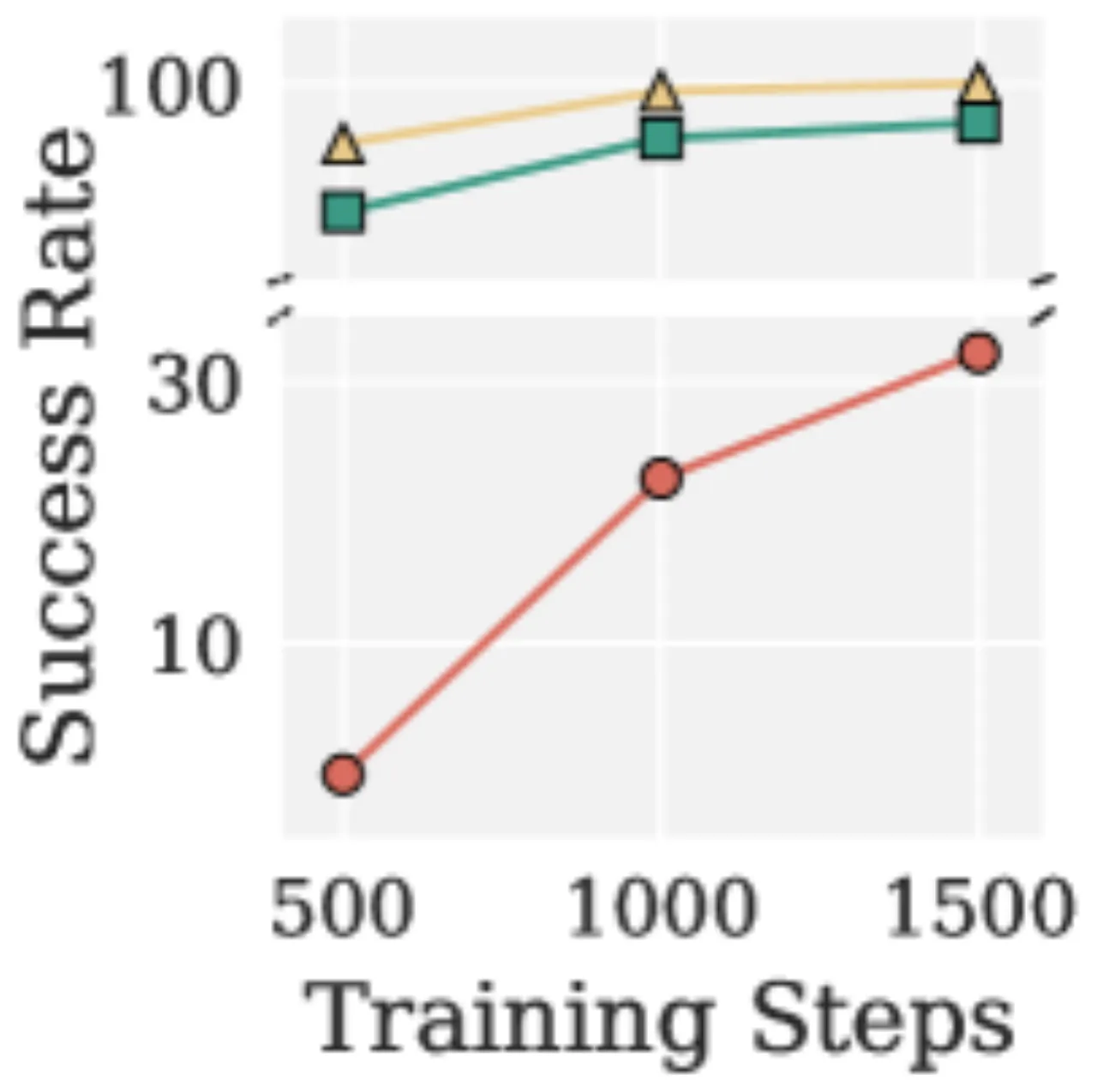
85.6%Pion — 真实机器人平均成功率
"Muon's uniform spectral whitening enhances exploration during pretraining but leads to fundamental limitations beyond that setting in two increasingly important regimes: cross-modality vision-language-action training, where low-rank action gradients amplify noise, and reinforcement learning with verifiable rewards, where low-SNR gradients and per-head specialization requirements cause instability."