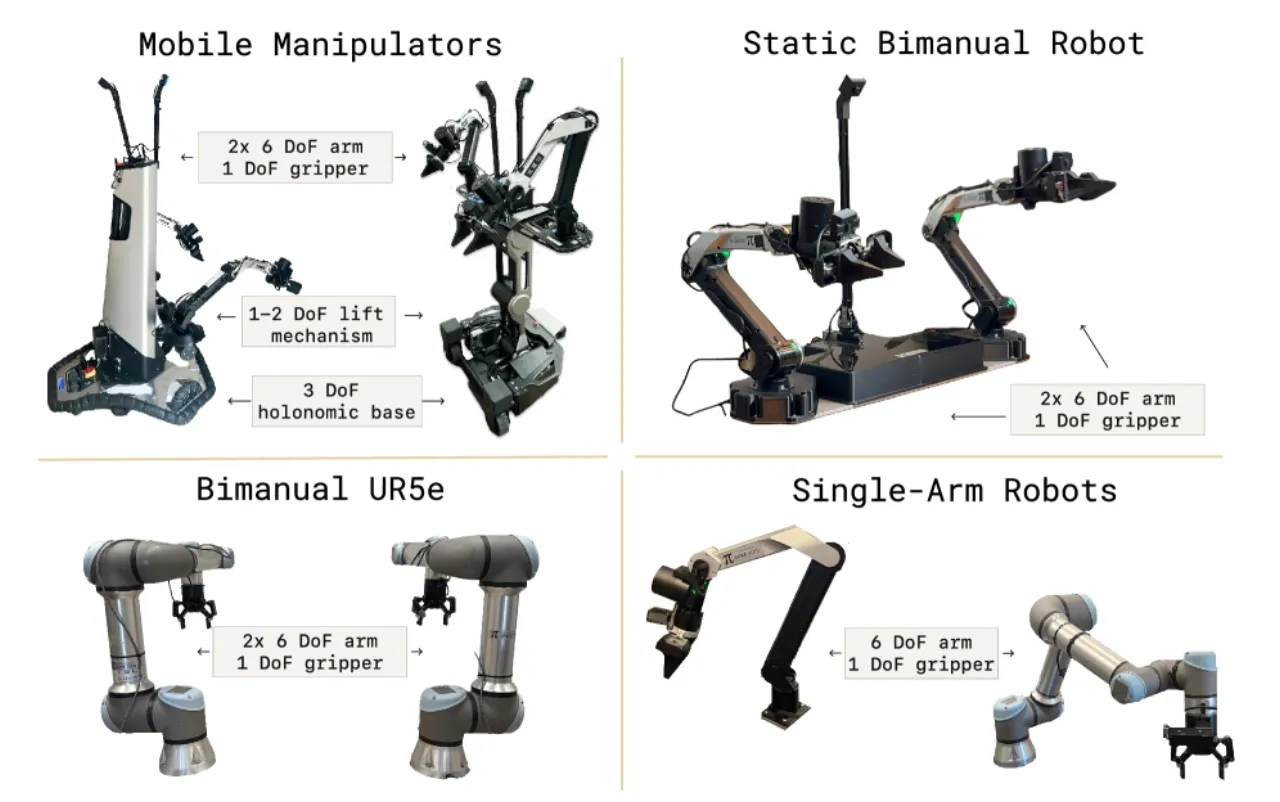
02 方法 Method
π₀.7 的核心创新在于多样化上下文条件训练(diverse context conditioning) :通过在训练时同时提供子任务自然语言指令、子目标图像和 episode 元数据,使模型能够理解并利用各种质量和来源的训练数据,并在推理时通过灵活配置这些条件来引导模型行为。
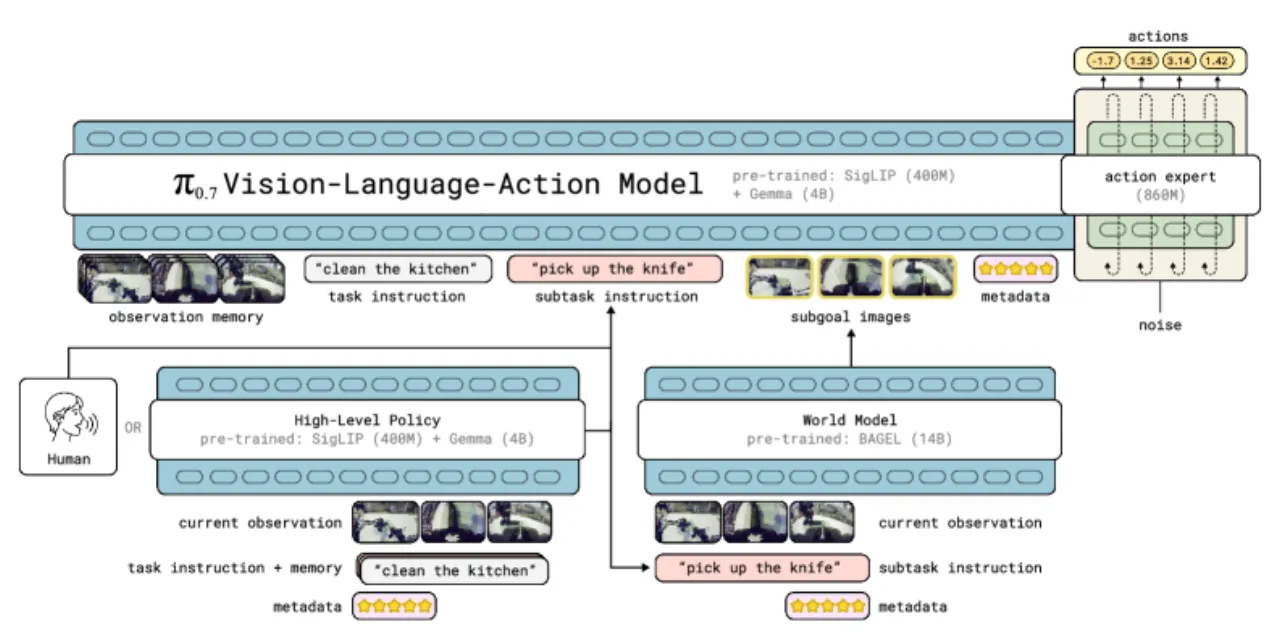
图 2:π₀.7 模型架构。 模型由三部分组成:4B 参数的 Gemma3 VLM 骨干网络(处理视觉与语言输入)、memory-style 视频历史编码器(MEM,用于记忆依赖型任务),以及 860M 参数的 flow-matching action expert(负责生成动作序列)。训练时,上下文信息包括:语言指令、子目标图像、episode 元数据(速度、质量、是否失误)和控制模式标识。
图 3:多样化提示(Diverse Prompting)策略示意图。 训练时的上下文由四类信息组成:子任务指令(subtask instructions)、子目标图像(subgoal images)、episode 元数据(episode metadata)和控制模式(control mode)。每类信息在训练时均以一定概率随机 dropout,确保模型在推理时能够灵活应对不同的提示组合。图中展示了折叠衬衫任务中子目标图像与元数据的组合提示示例。
核心组件 1:多模态上下文条件
训练时的上下文由四类信息构成,每类均以随机概率 dropout:
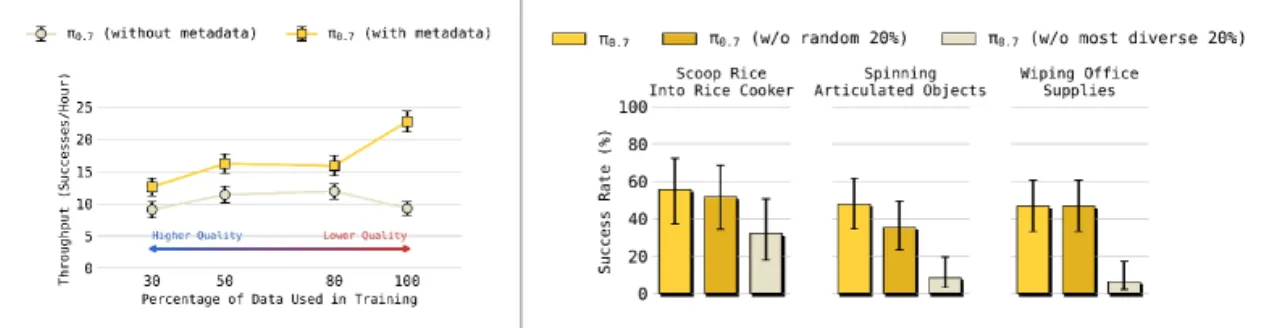
子任务指令(Subtask Instructions): 中间层语义任务描述(如 "open the fridge door"),支持逐步引导和测试时的语言 coaching。子目标图像(Subgoal Images): 描述期望近未来场景状态的多视角视觉目标,由基于 BAGEL 初始化的轻量级 world model 生成,用于表达语言难以描述的信息。子目标图像被加入 25% 的训练样本,本身以 30% 的概率随机丢弃;训练样本中以 25% 概率采样片段端点的真实未来帧,75% 概率在 0–4 秒范围内均匀采样,并混合真实帧和生成帧以减小 train-test mismatch。Episode 元数据(Episode Metadata): 包括整体速度(以 500 步为单位离散化)、质量评分(1–5 分)和失误标记。这些标签使模型能够理解不同质量和策略的数据来源。整体以 15% 概率完全丢弃,各子项以 5% 概率单独丢弃。控制模式(Control Mode): 文本标识符,指定关节级或末端执行器动作模式。
核心组件 2:训练数据多样性
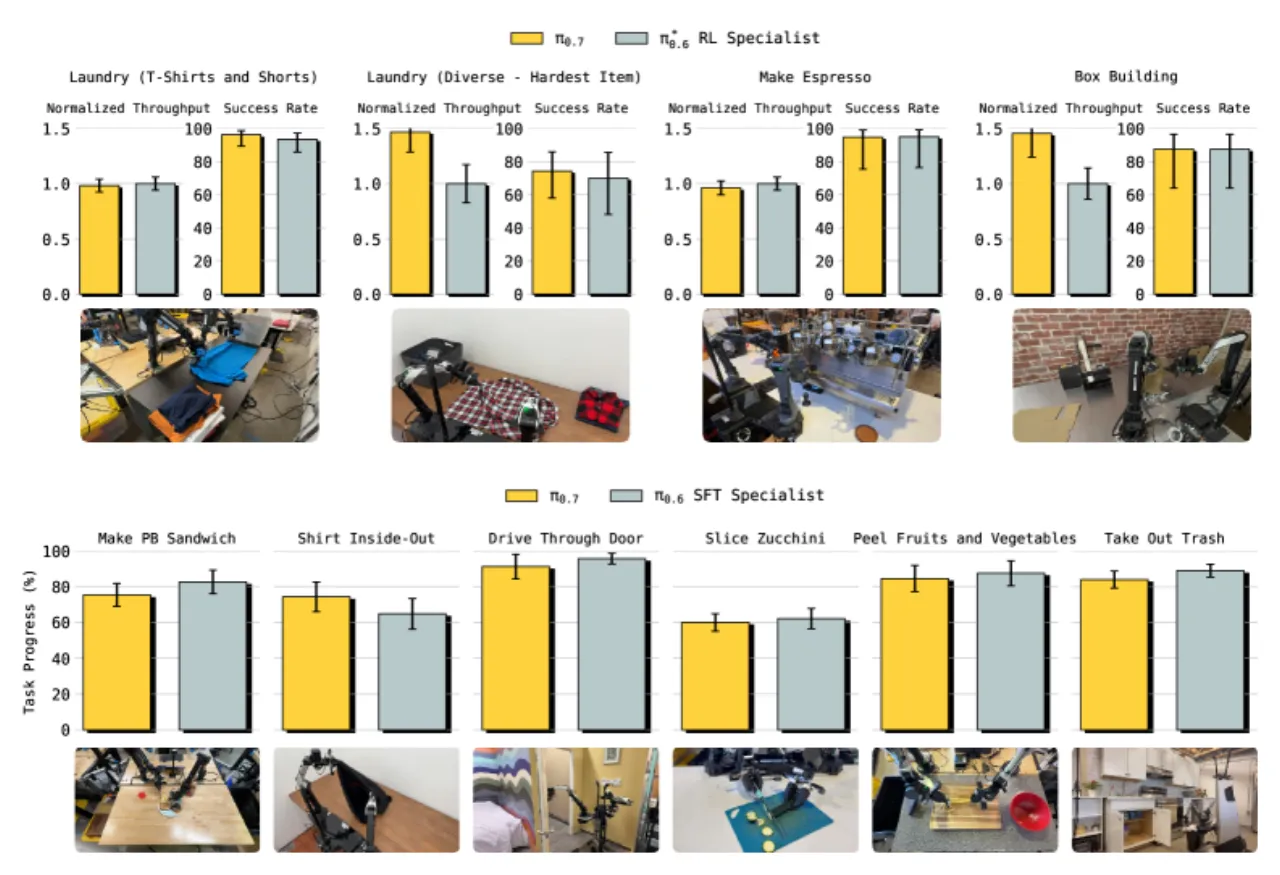
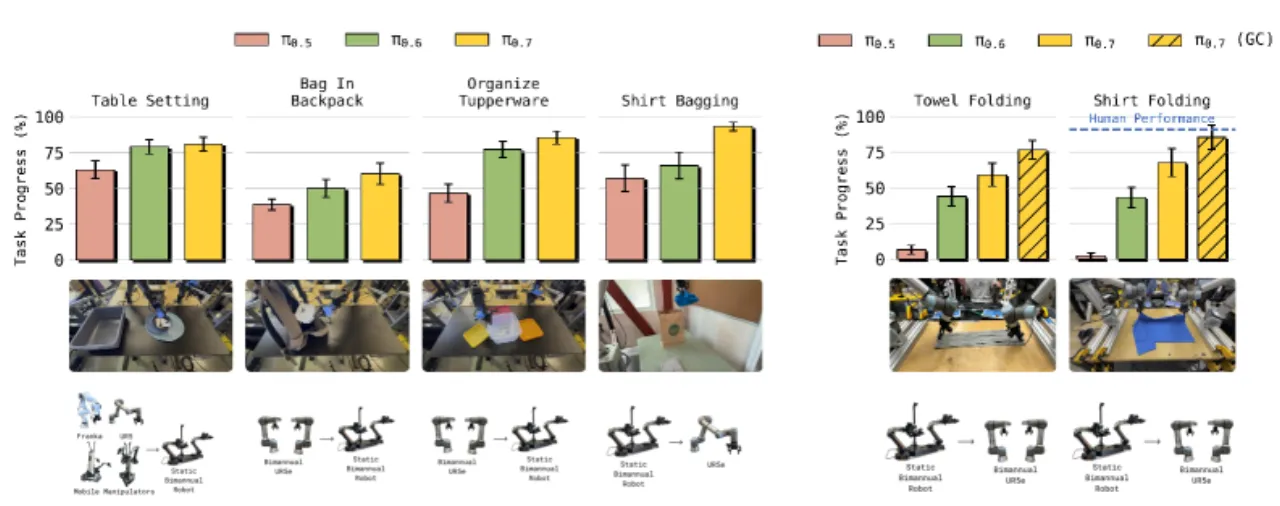
π₀.7 的训练数据涵盖前所未有的多样性:多种机器人平台的遥操作演示数据、包含失败和次优行为的自主推演数据、以人为中心的视频数据、以及网络非机器人数据(物体定位、VQA、文字预测、视频-语言任务)。值得注意的是,模型通过纳入 RL 专家模型的评估数据来蒸馏 其行为,而无需重新采集低层动作数据。
推理配置
推理时固定配置(Algorithm 1):控制模式始终提供;速度设为任务 episode 长度的第 15 百分位(偏快);质量始终设为最高(5 分);失误标记设为 false。子任务指令由高层策略或人类监督提供;子目标图像每 4 秒刷新一次或在意图改变时更新。每次推理通过 5 步去噪 生成 50 步动作 chunk,执行其中 15–25 步;支持 classifier-free guidance(CFG),权重 β ∈ {1.3, 1.7, 2.2}。