01 动机
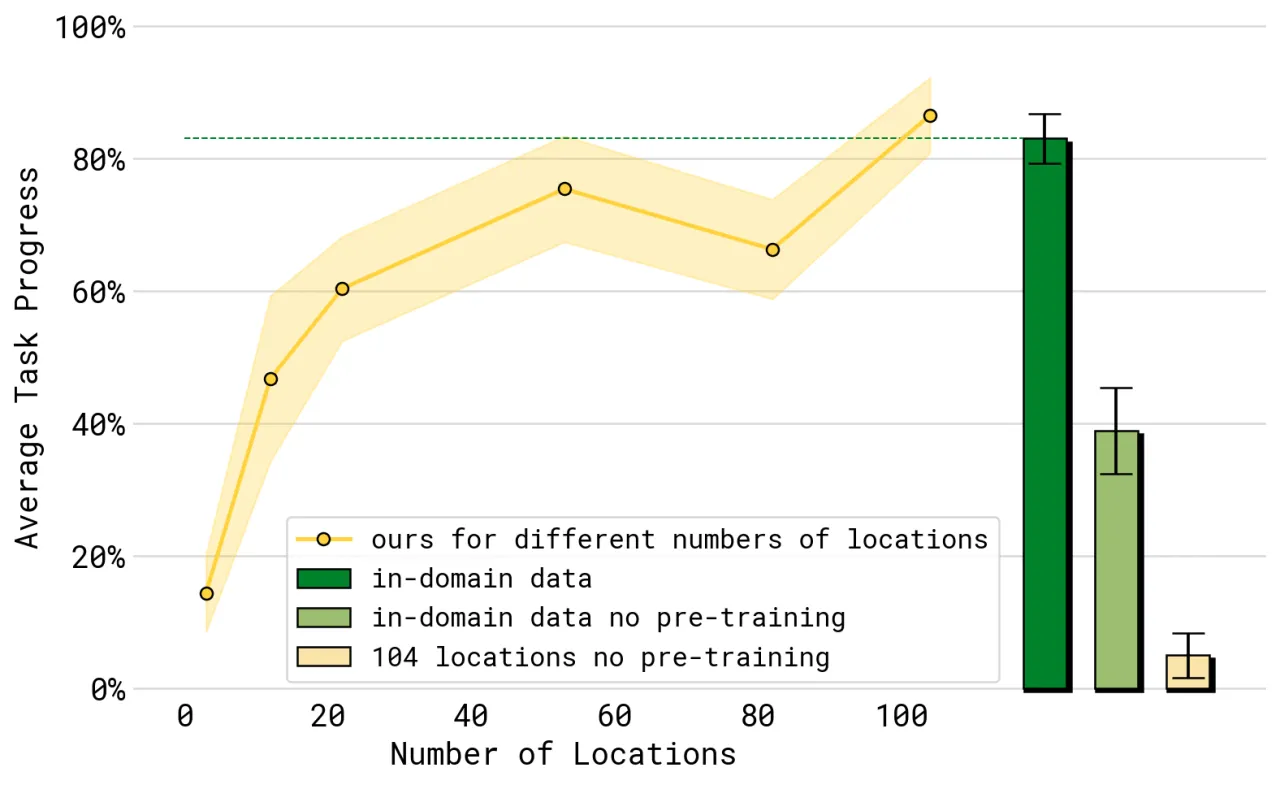
当前 VLA 模型在实验室受控场景中表现亮眼,但如何在真实的、从未见过的家庭环境中可靠执行长时域任务,仍是开放性挑战。简单堆砌机器人数据规模是不够的——泛化需要来自多个抽象层次的知识。
"In order for robots to be useful, they must perform practically relevant tasks in the real world, outside of the lab... achieving broad coverage of plausible scenarios via brute-force scaling of robot data collection is infeasible."

3全新真实家庭中完成测试
~400h移动操作机器人训练数据
~100训练环境(家庭数量)
+71%相对 π₀ 基线的任务进度提升
问题背景
Vision-Language-Action (VLA) 模型将大语言模型的语义理解能力与机器人控制相结合,展现了强大的指令跟随能力。然而,现有方法的评测大多在与训练数据分布相近的环境中进行,真正的"野外"泛化能力尚未被验证。
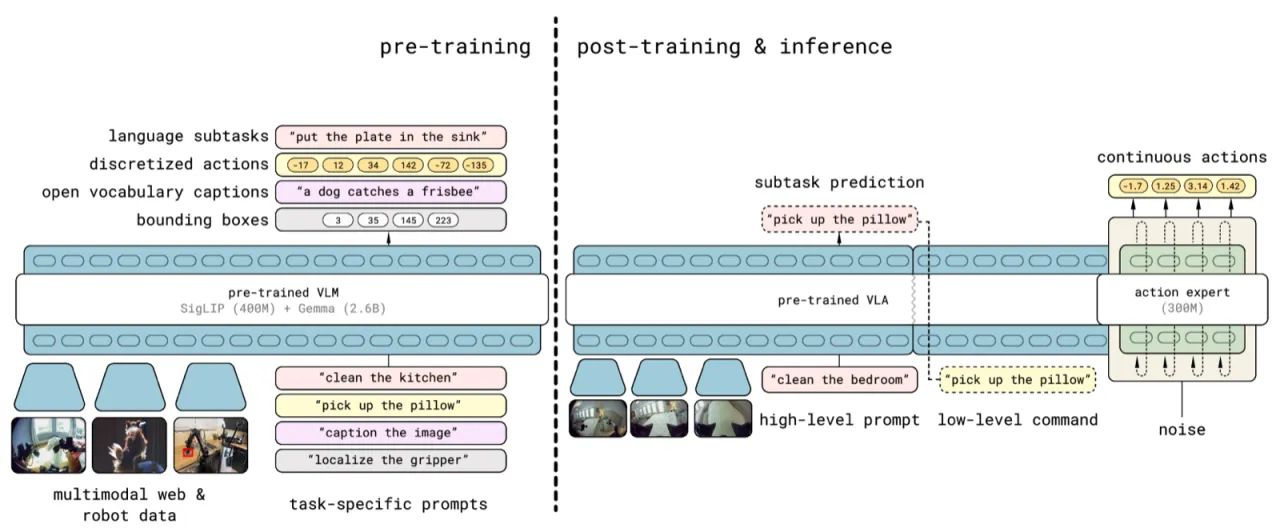
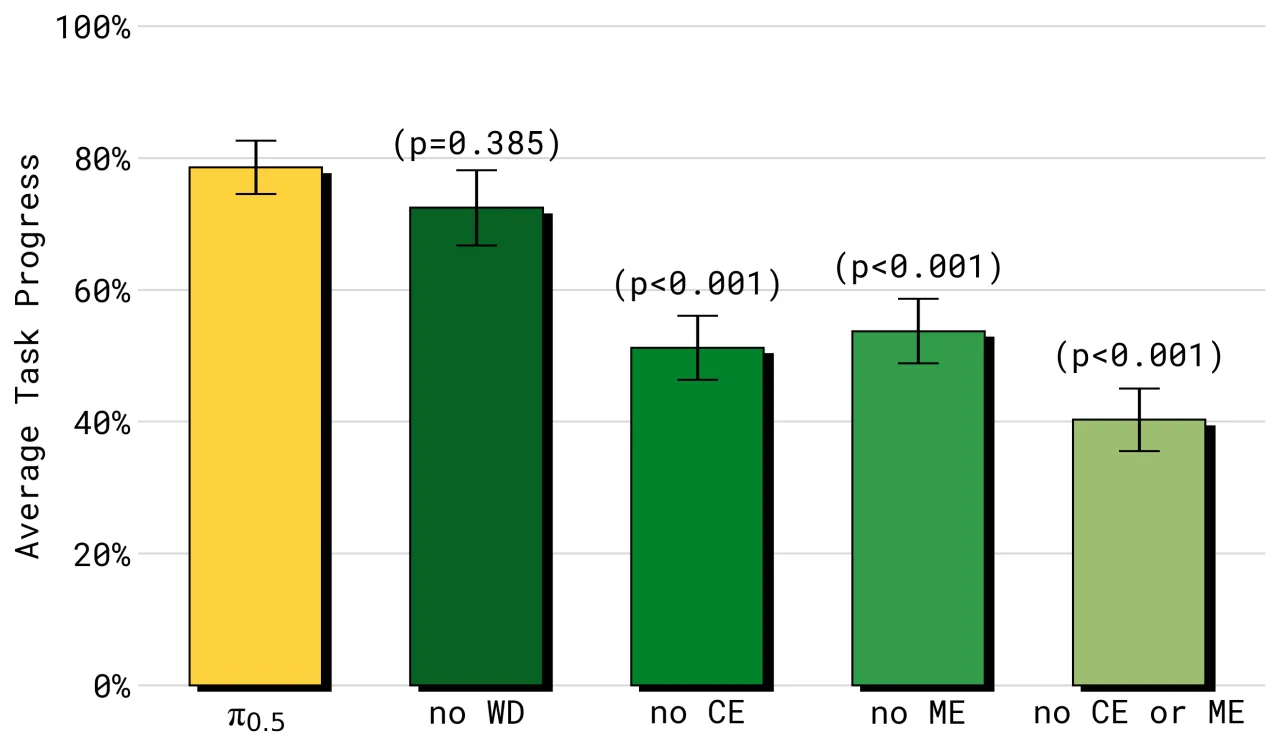
π₀.₅ 的核心主张是:有效的开放世界泛化需要来自多个信息源的知识迁移,包括多机器人平台的数据、网页视觉数据,以及对任务语义结构的显式建模。