01 动机
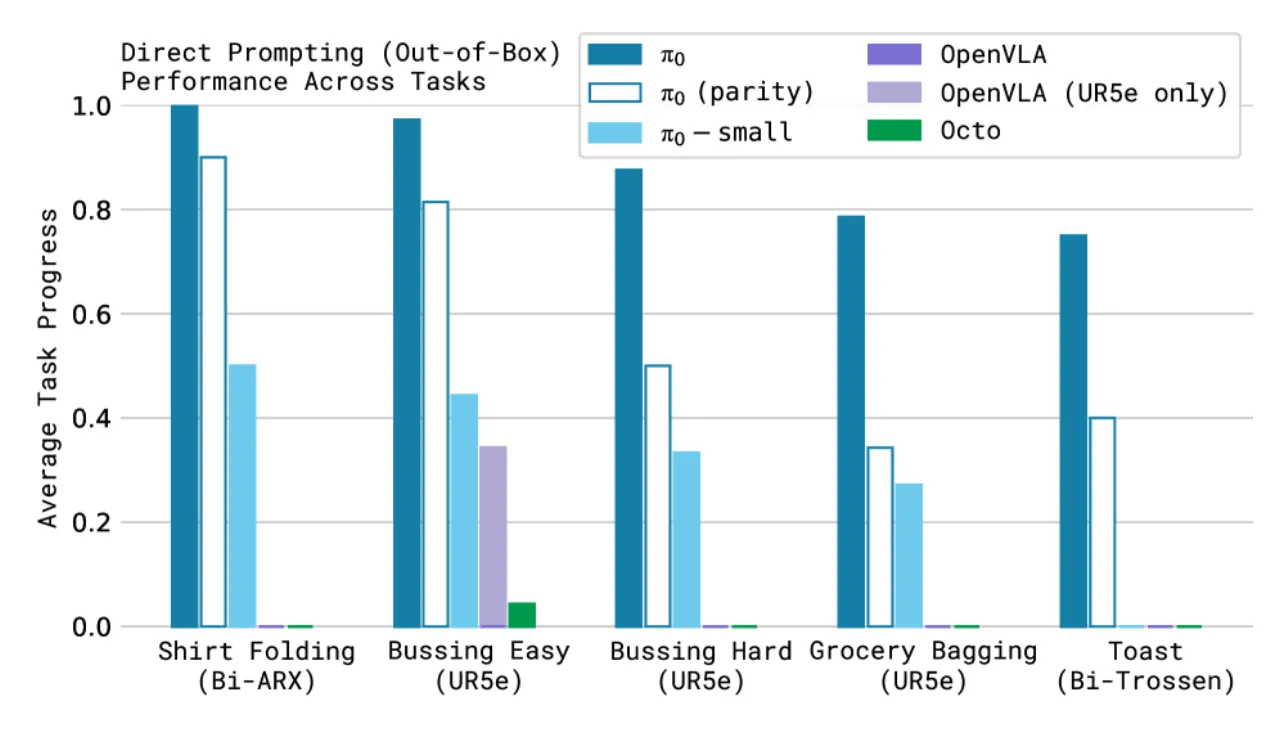
机器人学习要达到人类般的灵活性与泛化能力,面临三大核心障碍:数据规模不足、模型泛化能力弱以及训练方法不成熟。现有 VLA 模型(如 OpenVLA、Octo)大多采用自回归离散化动作表示,在高频连续控制和精细操作任务上能力受限。
"We propose a novel flow matching architecture built on top of a pre-trained vision-language model (VLM) to inherit Internet-scale semantic knowledge… Our results cover a wide variety of tasks, such as laundry folding, table cleaning, and assembling boxes."
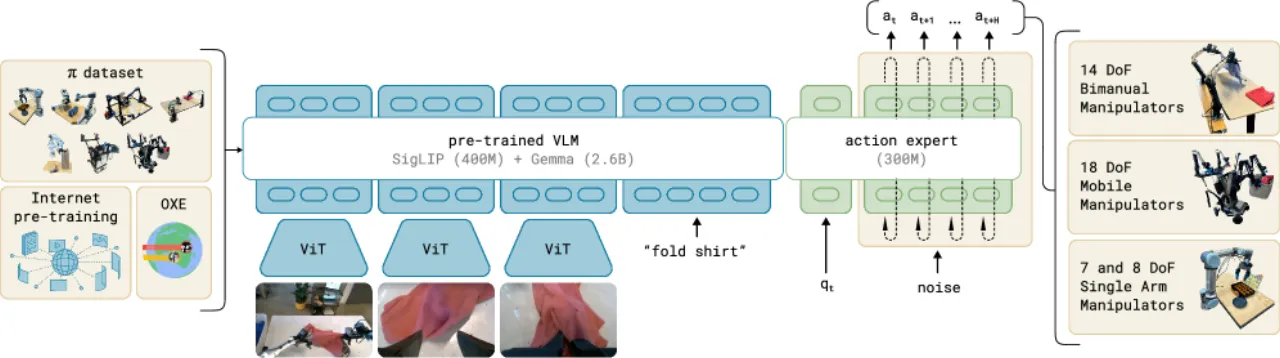
3.3B总参数量(VLM 3B + action expert 300M)
10,000+小时自有机器人操作数据(+ OXE 开源数据)
7 种机器人平台(单臂、双臂、移动操作机器人)
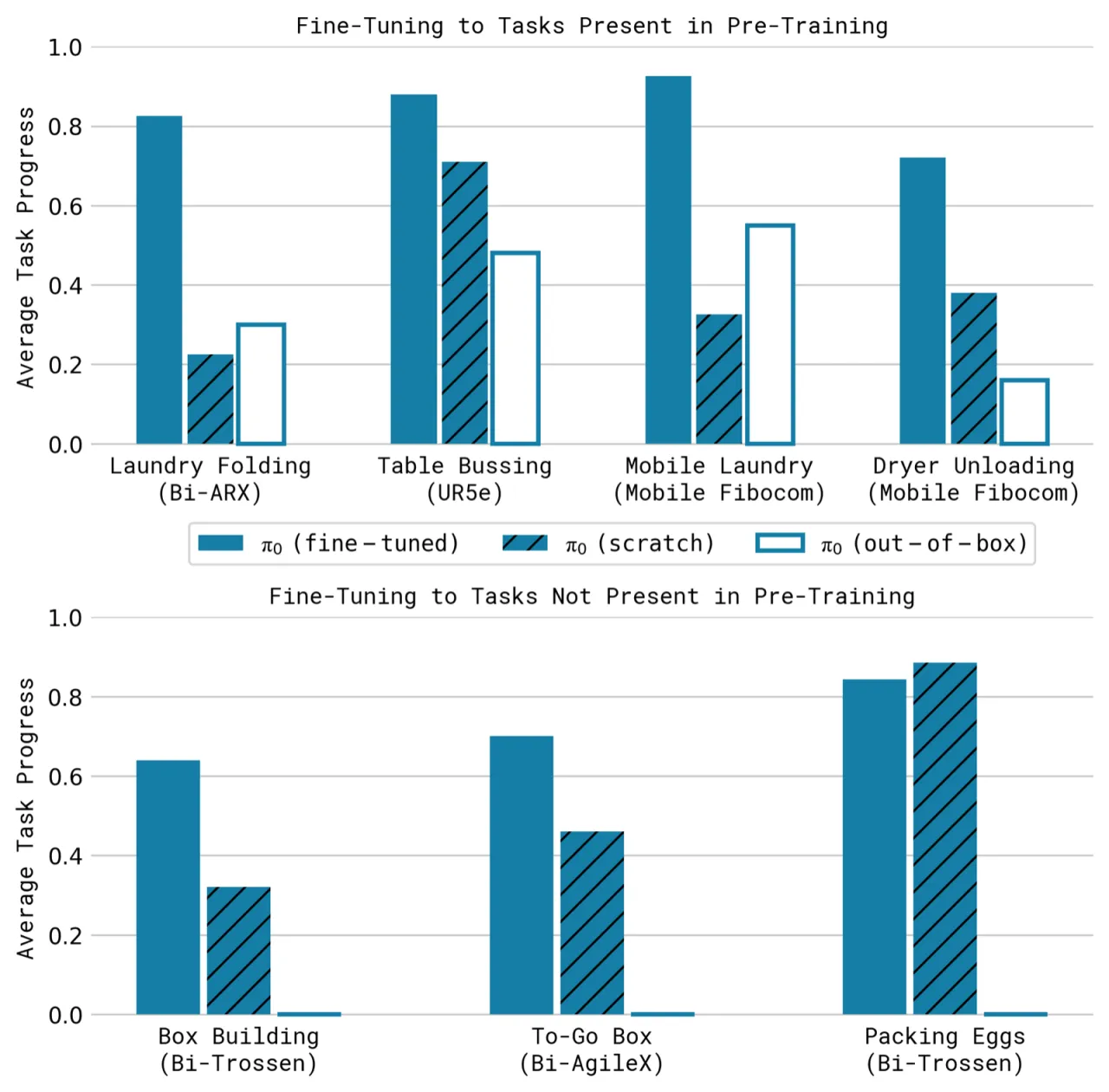
68 个任务类别,覆盖叠衣、清桌、装箱等高精操作
为什么现有方法不够用?
- OpenVLA(7B 参数):自回归离散化动作,不支持 action chunking,无法处理高频连续控制。
- Octo(93M 参数):使用 diffusion 生成动作,表达能力有限;相比 π₀ 的流匹配 VLA 架构,在精细操作任务上差距显著。
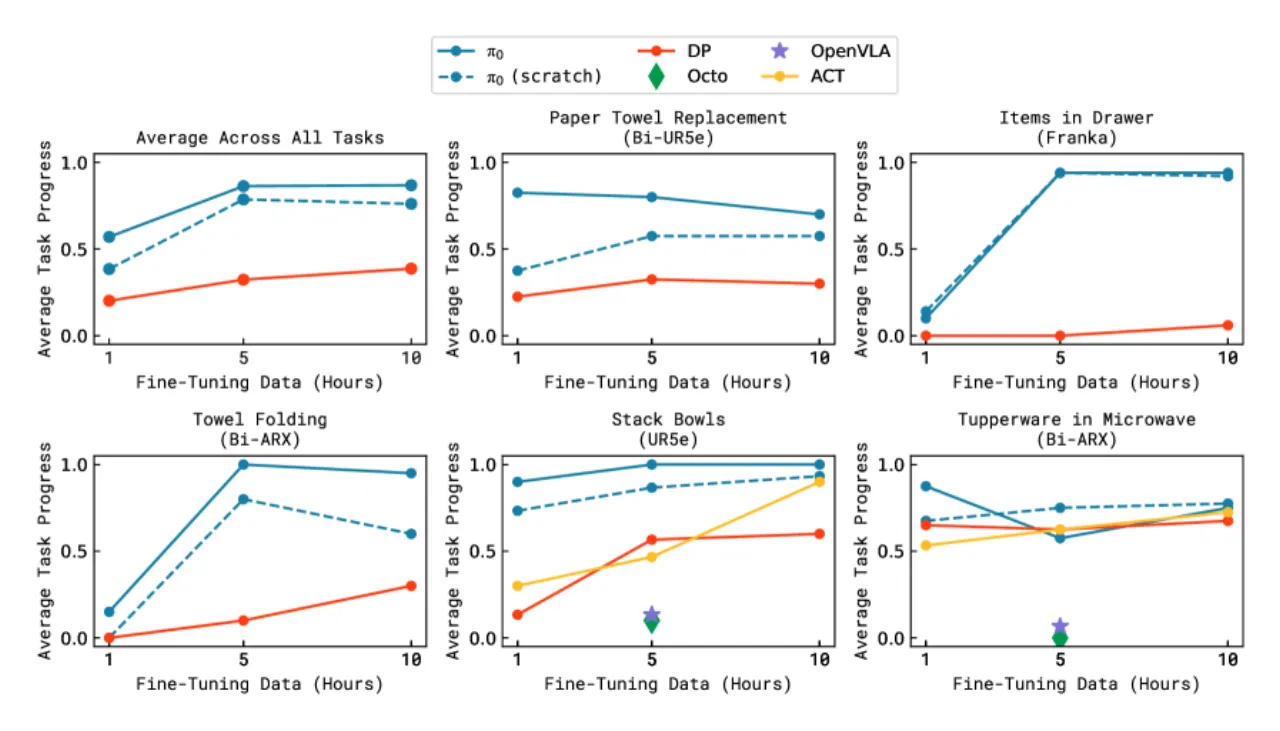
- 数据稀缺:大多数先前工作仅有 10s 或 100s 条训练轨迹(相当于 10 小时以内),难以支撑复杂任务的泛化。